GoogLeNet之Inception结构的解读
Inception结构的解读
Inception结构,是一种高效表达特征的稀疏性结构。基于底层的相关性高的单元,通常会聚集在图像的局部区域(通常CNN底层卷积提取的都是局部特征),这就相当于在单个局部区域上,去学习它的特征,然后在高层用11卷积代替这个区域,当然某些相关性可能是隔得比较远的,通过使用大的卷积核学习即可。
原始Inception A结构如下图所示:
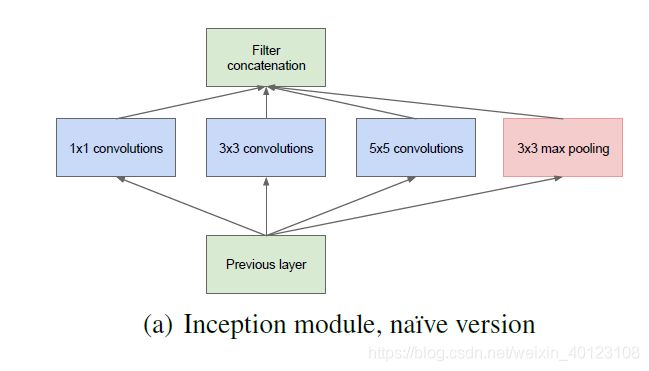
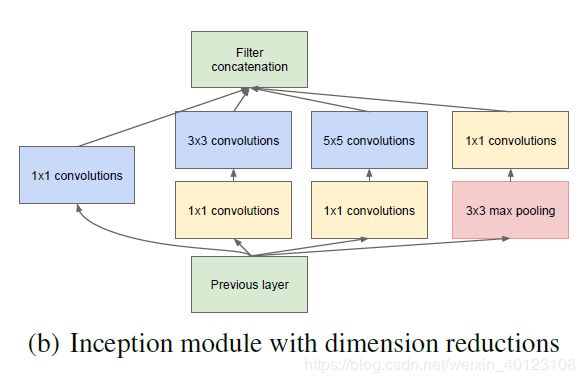
在InceptionA中33,5*5卷积仍然会导致参数量过大,对此问题进行改进,改进的inceptionB结构为:
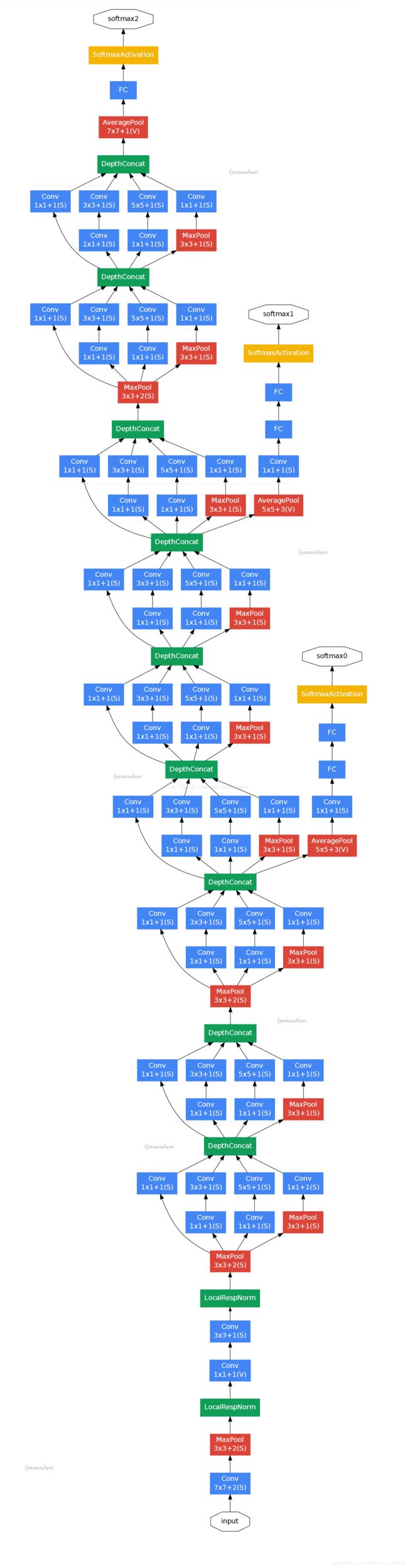
在GoogLeNet中第三层为inception module,采用不同尺度的卷积核来处理问题。第二层到第三层的四个分支分别为:
(1)64个1x1的卷积核,进行ReLU计算后得到28X28X64
(2)96个1X1的卷积核作为3x3卷积核之前的reduce,变成28x28x96,进行ReLU计算后,在进行128个3x3的卷积,pad为1,变为28x28x128.
(3)16个1x1的卷积核作为5x5卷积核之前的reduce,变为28x28x96,进行ReLU计算后,在进行32个5x5的卷积,pad为2,变为28x28x32.
(4)pool层,3x3的卷积核,pad为1,输出为28x28x192,进行32个1x1的卷积,变为28x28x32。
最后将四个结果进行拼接,输出为28x28x256
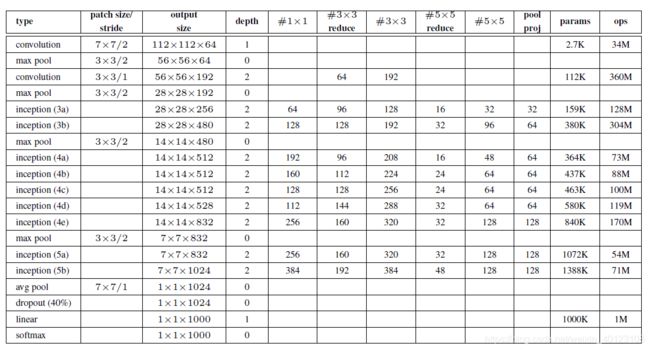
以下为整个googlenet的参数表
inception v4
图1.1 inception v4 网络结构图
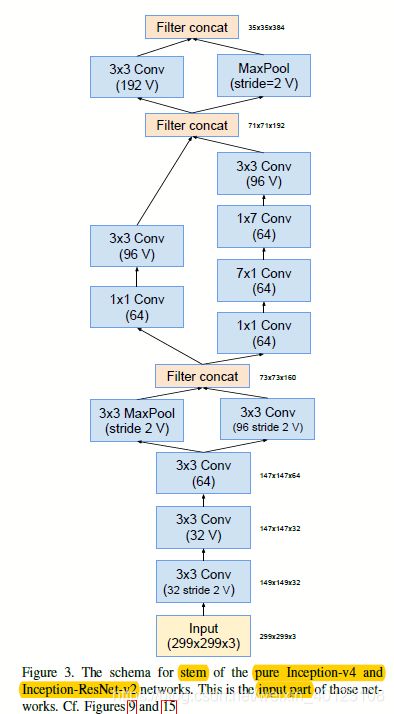
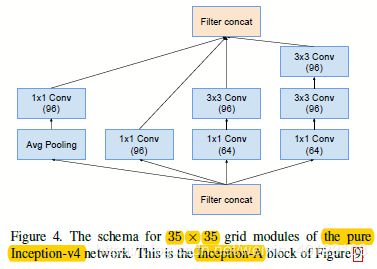
图1.2 图1.1的stem和Inception-A部分结构图
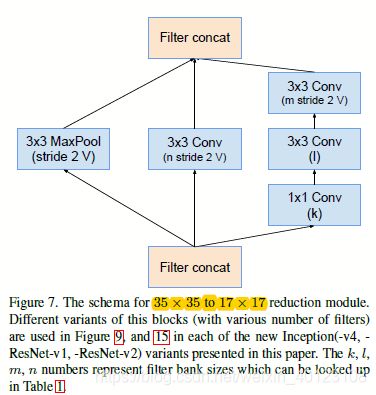
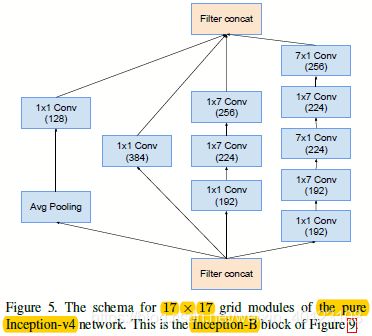
图1.3 图1.1的Reduction-A和Inception-B部分结构图
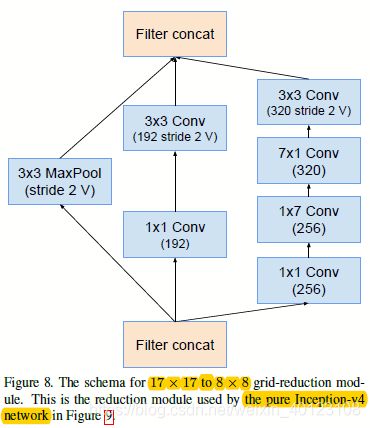
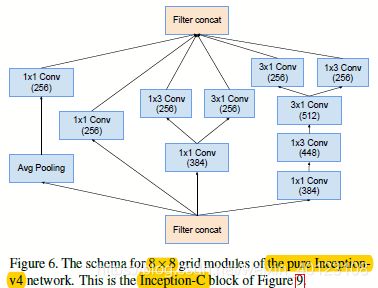 图1.4 图1.1的Reduction-B和Inception-C部分结构图
图1.4 图1.1的Reduction-B和Inception-C部分结构图
2. Inception-resnet-v1 & Inception-resnet-v2
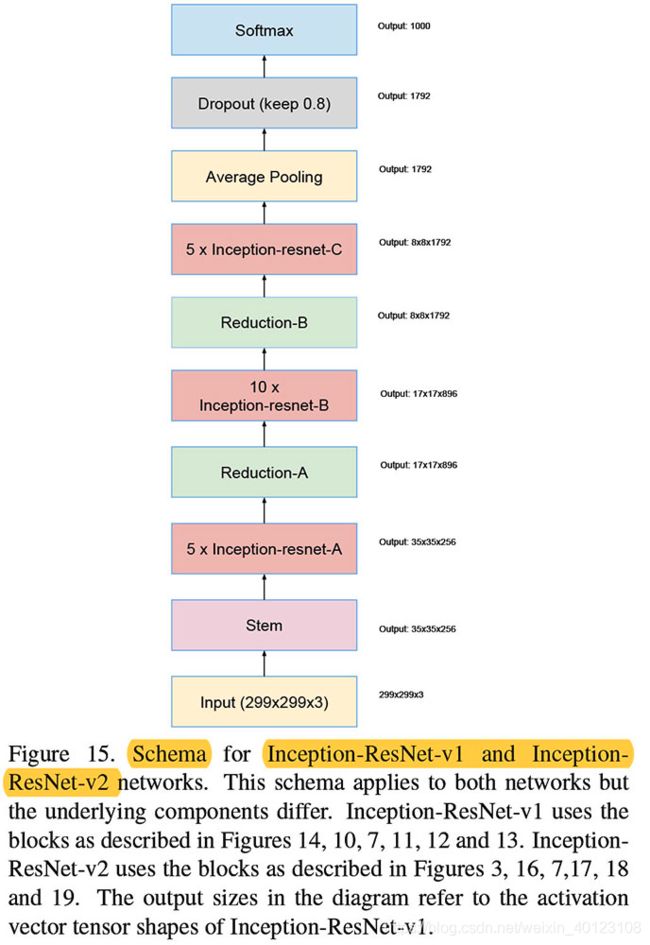
2.1 Inception-resnet-v1的组成模块

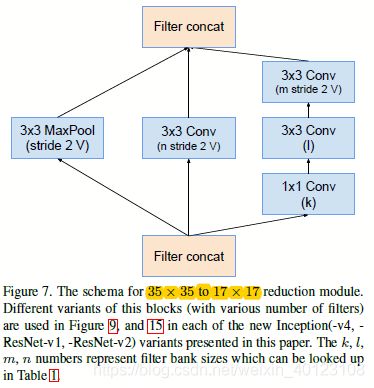

图2.1.2 图2.1的Reduction-A和Inception-ResNet-B部分结构图
2.2 Inception-resnet-v2的组成模块
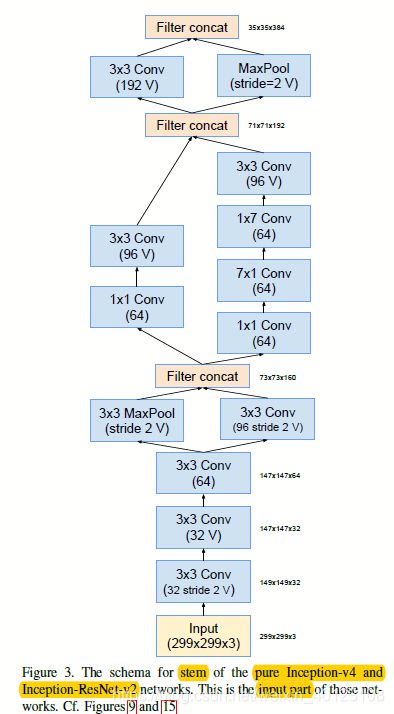
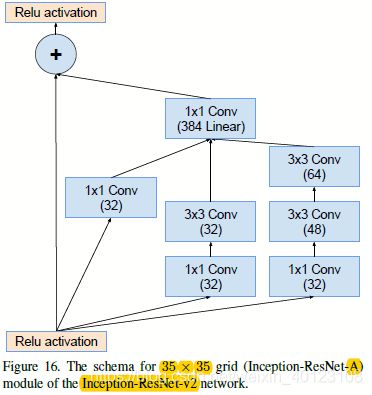
图2.2.1 图2.1的stem和Inception-ResNet-A部分结构图
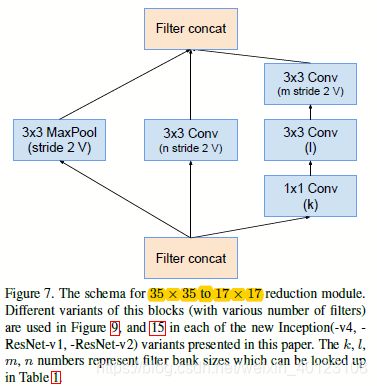
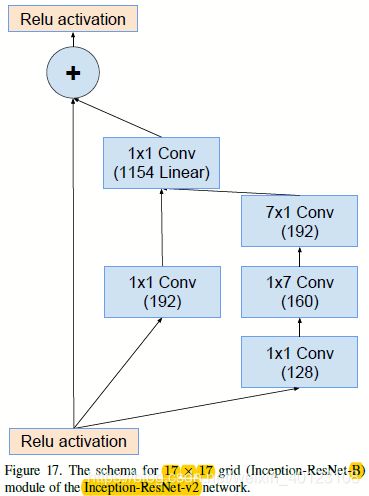 图2.2.2 图2.1的Reduction-A和Inception-ResNet-B部分结构图
图2.2.2 图2.1的Reduction-A和Inception-ResNet-B部分结构图


图2.2.3 图2.1的Reduction-B和Inception-ResNet-C部分结构图
3. 模型训练
在上述的Inception V4,Inception-Resnet-V1,Inception-ResNet-v2这三个模型中都用到了Reduction-A,他们各自的具体参数如下:
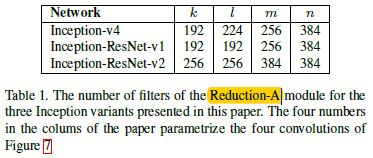 图3.1 不同模型下Reduction-A的模型超参数
图3.1 不同模型下Reduction-A的模型超参数
作者们在训练的过程中发现,如果通道数超过1000,那么Inception-resnet等网络都会开始变得不稳定,并且过早的就“死掉了”,即在迭代几万次之后,平均池化的前面一层就会生成很多的0值。作者们通过调低学习率,增加BN都没有任何改善。
不过他们发现如果在将残差汇入之前,对残差进行缩小,可以让模型稳定训练,值通常选择[0,1.0.3],如图3.2
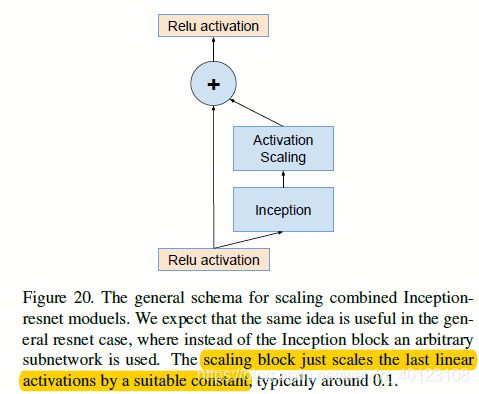
图3.2 对inception-resnet模块进行最后输出值的等比例缩小
同样的在ResNet-v1中,何凯明等人也在cifar-10中发现了模型的不稳定现象:即在特别深的网络基础上去训cifar-10,需要先以0.01的学习率去训练,然后在以0.1的学习率训练。
不过这里的作者们认为如果通道数特别多的话,即使以特别低的学习率(0.00001)训练也无法让模型收敛,如果之后再用大学习率,那么就会轻松的破坏掉之前的成果。然而简单的缩小残差的输出值有助于学习的稳定,即使进行了简单的缩小,那么对最终结果也造成不了多大的损失,反而有助于稳定训练。
在inception-resnet-v1与inception v3的对比中,inception-resnet-v1虽然训练速度更快,不过最后结果有那么一丢丢的差于inception v3;
而在inception-resnet-v2与inception v4的对比中,inception-resnet-v2的训练速度更块,而且结果比inception v4也更好一点。所以最后胜出的就是inception-resnet-v2。

具体inception A结构的pytorch实现如下所示:
import torch
from torch import nn
from torch.autograd import Variable
# 定义一个卷积加一个 relu 激活函数和一个 batchnorm 作为一个基本的层结构
def conv_relu(in_channel, out_channel, kernel, stride=1, padding=0):
layer = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel, stride, padding),
nn.BatchNorm2d(out_channel, eps=1e-3),
nn.ReLU(True)
)
return layer
class inception(nn.Module):
def __init__(self, in_channel, out1_1, out2_1, out3_1, out4_1):
super(inception, self).__init__()
# 第一条线路
self.branch1x1 = conv_relu(in_channel, out1_1, 1)
# 第二条线路
self.branch3x3 = nn.Sequential(
conv_relu(3, out2_1, 3,stride=1, padding=1)
)
# 第三条线路
self.branch5x5 = nn.Sequential(
conv_relu(3, out3_1, 5,stride=1, padding=2)
)
# 第四条线路
self.branch_pool = nn.Sequential(
nn.MaxPool2d(3, stride=1, padding=1),
conv_relu(3,out4_1, 1)
)
def forward(self, x):
f1 = self.branch1x1(x)
f2 = self.branch3x3(x)
f3 = self.branch5x5(x)
f4 = self.branch_pool(x)
output = torch.cat((f1, f2, f3, f4), dim=1)
return output
test_net = inception(3, 64, 96, 48, 48)
test_x = Variable(torch.zeros(1, 3, 96, 96))
print('input shape: {} x {} x {}'.format(test_x.shape[1], test_x.shape[2], test_x.shape[3]))
test_y = test_net(test_x)
print('output shape: {} x {} x {}'.format(test_y.shape[1], test_y.shape[2], test_y.shape[3]))
![]()
具体inception B结构的pytorch实现如下所示:
import torch
from torch import nn
from torch.autograd import Variable
# 定义一个卷积加一个 relu 激活函数和一个 batchnorm 作为一个基本的层结构
def conv_relu(in_channel, out_channel, kernel, stride=1, padding=0):
layer = nn.Sequential(
nn.Conv2d(in_channel, out_channel, kernel, stride, padding),
nn.BatchNorm2d(out_channel, eps=1e-3),
nn.ReLU(True)
)
return layer
#第一个通道
print(conv_relu(3, 64, 1))

#第二个通道
x=nn.Sequential(
conv_relu(3, 96, 1),
conv_relu(96, 128, 3, padding=1)
)
print(x)

#第三个通道
y=nn.Sequential(
conv_relu(3, 16, 1),
conv_relu(16, 32, 5, padding=2)
)
print(y)

#第四个通道
z=nn.Sequential(
nn.MaxPool2d(3, stride=1, padding=1),
conv_relu(3, 32, 1)
)
print(z)
inceptionB结构程序如下所示
class inception(nn.Module):
def __init__(self, in_channel, out1_1, out2_1, out2_3, out3_1, out3_5, out4_1):
super(inception, self).__init__()
# 第一条线路
self.branch1x1 = conv_relu(in_channel, out1_1, 1)
# 第二条线路
self.branch3x3 = nn.Sequential(
conv_relu(in_channel, out2_1, 1),
conv_relu(out2_1, out2_3, 3, padding=1)
)
# 第三条线路
self.branch5x5 = nn.Sequential(
conv_relu(in_channel, out3_1, 1),
conv_relu(out3_1, out3_5, 5, padding=2)
)
# 第四条线路
self.branch_pool = nn.Sequential(
nn.MaxPool2d(3, stride=1, padding=1),
conv_relu(in_channel, out4_1, 1)
)
def forward(self, x):
f1 = self.branch1x1(x)
f2 = self.branch3x3(x)
f3 = self.branch5x5(x)
f4 = self.branch_pool(x)
output = torch.cat((f1, f2, f3, f4), dim=1)
return output
#实现上述inception结构
test_net = inception(3, 64, 96, 128, 16, 32, 32)
test_x = Variable(torch.zeros(1, 3, 96, 96))
print('input shape: {} x {} x {}'.format(test_x.shape[1], test_x.shape[2], test_x.shape[3]))
test_y = test_net(test_x)
print('output shape: {} x {} x {}'.format(test_y.shape[1], test_y.shape[2], test_y.shape[3]))
![]()
输入经过了 inception 模块之后,大小没有变化,通道的维度变多了,GoogLeNet 可以看作是很多个 inception 模块的串联,原论文中使用了多个输出来解决梯度消失的问题,这里定义一个简单版本的 **
GoogLeNet
**,简化为一个输出。
class googlenet(nn.Module):
def __init__(self, in_channel, num_classes, verbose=False):
super(googlenet, self).__init__()
self.verbose = verbose
self.block1 = nn.Sequential(
conv_relu(in_channel, out_channel=64, kernel=7, stride=2, padding=3),
nn.MaxPool2d(3, 2)
)
self.block2 = nn.Sequential(
conv_relu(64, 64, kernel=1),
conv_relu(64, 192, kernel=3, padding=1),
nn.MaxPool2d(3, 2)
)
self.block3 = nn.Sequential(
inception(192, 64, 96, 128, 16, 32, 32),
inception(256, 128, 128, 192, 32, 96, 64),
nn.MaxPool2d(3, 2)
)
self.block4 = nn.Sequential(
inception(480, 192, 96, 208, 16, 48, 64),
inception(512, 160, 112, 224, 24, 64, 64),
inception(512, 128, 128, 256, 24, 64, 64),
inception(512, 112, 144, 288, 32, 64, 64),
inception(528, 256, 160, 320, 32, 128, 128),
nn.MaxPool2d(3, 2)
)
self.block5 = nn.Sequential(
inception(832, 256, 160, 320, 32, 128, 128),
inception(832, 384, 182, 384, 48, 128, 128),
nn.AvgPool2d(2)
)
self.classifier = nn.Linear(1024, num_classes)
def forward(self, x):
x = self.block1(x)
if self.verbose:
print('block 1 output: {}'.format(x.shape))
x = self.block2(x)
if self.verbose:
print('block 2 output: {}'.format(x.shape))
x = self.block3(x)
if self.verbose:
print('block 3 output: {}'.format(x.shape))
x = self.block4(x)
if self.verbose:
print('block 4 output: {}'.format(x.shape))
x = self.block5(x)
if self.verbose:
print('block 5 output: {}'.format(x.shape))
x = x.view(x.shape[0], -1)
x = self.classifier(x)
return x
test_net = googlenet(3, 10, True)
test_x = Variable(torch.zeros(1, 3, 96, 96))
test_y = test_net(test_x)
print('output: {}'.format(test_y.shape))