图像分割的评价指标
因为之前研究了下图像分割的评分指标, 主要应用在道路线检测方面上,所以把这些写下来:
图像分割的评分标准主要有以下四种:
- Pixel accurancy (像素准确性)
- IoU (Intersection over Union)
- Mean IoU
- Dice score
在解释以上的评价指标之前, 我们需要先了解混淆矩阵, 因为以上的评价指标是跟混淆矩阵有关, 或者可以说是由混淆矩阵引出。
混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。具体评价指标有总体精度、制图精度、用户精度等,这些精度指标从不同的侧面反映了图像分类的精度。 [1] 在人工智能中,混淆矩阵(confusion matrix)是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵。在图像精度评价中,主要用于比较分类结果和实际测得值,可以把分类结果的精度显示在一个混淆矩阵里面。混淆矩阵是通过将每个实测像元的位置和分类与分类图像中的相应位置和分类相比较计算的。
混淆矩阵的每一列代表了预测类别,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。每一列中的数值表示真实数据被预测为该类的数目:如下图,第一行第一列中的43表示有43个实际归属第一类的实例被预测为第一类,同理,第一行第二列的2表示有2个实际归属为第一类的实例被错误预测为第二类。
下面是一个简单的例子:
如果神经网络系统被训练去识别和区分狗跟猫,那么混淆矩阵将汇总测试算法的结果以供进一步检查。
我们假设有13种动物的样本-8只猫和5只狗

在此混淆矩阵中,系统预测了8只实际的猫,系统预测了3只是狗,而5只狗中,则预测有2只是猫。所有正确的预测都位于表格的对角线(以粗体突出显示)中,因此很容易从视觉上检查表格中的预测错误,因为它们将由对角线之外的值表示。
In abstract terms, the confusion matrix is as follows:
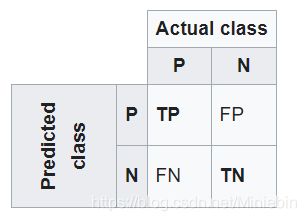
在这里我们假设猫是positive,非猫是negative (这里指的是狗)
TP:表示测试样本中猫能够被准确地预测成猫
TN: 表示测试样本中非猫(狗)能够被准确地预测成非猫(狗)
FP:表示测试样本中非猫能够被准确地预测成猫
FN:表示表示测试样本中猫能够被准确地预测成非猫
这里只要记住:T开头就是表示能准确预测, 后面接的P跟N 分别表示准确地预测了猫(P) 和非猫(N)
而 F 开头表示不能准确预测,FN可以理解成猫被错误得预测成了非猫,因为N 代表的是非猫。 相反, FP 可以理解为非猫被错误地预测称了猫。
好了, 这里我们开始解释什么是像素准确性,IoU ,MIoU 以及F1 score
pixel accuracy (像素准确性)
像素精度是图像分割的最简单指标,它是正确分类的总像素除以总像素,可以理解为图像中正确分类的像素的百分比。
下面我们举一个简单的例子:
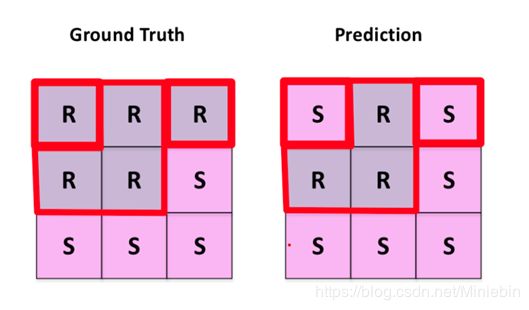
一般在图像分割,都是label图像的像素点
这里我们假设R指的是道路线像素点,S 指的是背景像素点
所以R 是positive, 非R(S)就是negative,指的是像素点不属于道路线
从上面的图我们可以看出
道路线像素点能够地预测为道路线像素点有3 个(中间行前两个+第一行中间) ,所以TP=3
非道路线像素点能够地预测为非道路线像素点有4个(最后一整行+中间行最后一个),所以TN=4
道路线点被错误地预测为非道路线像素点有2个(第一行的左右两个角落上S),所以FN=2
像素精度:

根据上面的数据, 我们能够计算出像素精度:

IoU
IoU(intersection over union) 值得是像素的真实值与预测值的交集除以像素的真实值和预测值的交集

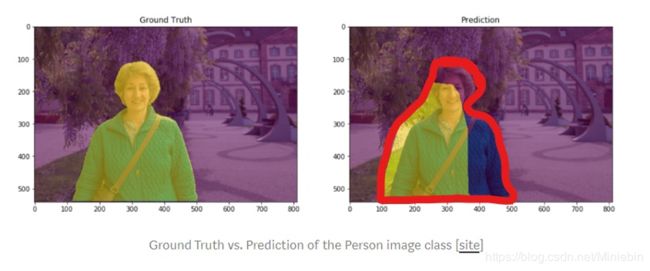
在图像分割中,我们的目标是把人物分割出来。
右边的图片是真实值(黄色部分), 左边(黄色部分)是预测值
所以我们可以计算IoU:
真实值跟预测值交集(红色部分):


真实值与预测值的并集(红色部分):

MIoU
在语义分割中,MIoU 就是分别对每个类计算(真实标签和预测结果的交并比)IOU,然后再对所有类别的IOU求均值。MIoU是标准的准确率度量方法。


比如上面的图片,我们做实例分割,区分每一条道路线,相当于每一条道路线属于一类。如果我们需要计算平均IoU, 就得算出每条道路线的IoU,然后在求平均值就是MIoU
F1 score (Dice score):
Dice score 是根据测试样本的准确性(precision)跟敏感度(也叫recall)计算出来的,就是平衡两个标准
precision:
用上面猫狗分类的例子解释
准确性就是 测试样本中准确地预测为猫的数除以测试样本准确预测的总数(包括猫和狗)
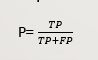
recall: 就是测试样本中准确地预测为猫的数除以测试样本猫总数

Dice score 的通用公式:

通常,我们认为recall的重要性跟precision的重要性一样,所以 belta=1
这就是所谓的 F1 score。
