第7章 pandas文本数据(初学者需要掌握的几种基本的数据预处理方法)
在拿到一份数据准备做挖掘建模之前,首先需要进行初步的数据探索性分析,对数据探索性分析之后要先进行一系列的数据预处理步骤。因为拿到的原始数据存在不完整、不一致、有异常的数据,而这些“错误”数据会严重影响到数据挖掘建模的执行效率甚至导致挖掘结果出现偏差,因此首先要数据清洗。数据清洗完成之后接着进行或者同时进行数据集成、转换、归一化等一系列处理,该过程就是数据预处理。一方面是提高数据的质量,另一方面可以让数据更好的适应特定的挖掘模型,在实际工作中该部分的内容可能会占整个工作的70%甚至更多。
系列文章
第1章 Pandas基础操作(使用pandas进行数据分析,从小白逆袭大神,你会了吗?)
第2章 精通pandas索引操作(使用pandas进行数据分析,从小白逆袭大神,你会了吗?)
第3章 Pandas 分组(使用pandas进行数据分析,从小白逆袭大神,你会了吗?)
第4章 精通pandas变形操作(使用pandas进行数据分析,从小白逆袭大神,你会了吗?)
第5章 精通pandas合并操作(使用pandas进行数据分析,从小白逆袭大神,你会了吗?)
第6章 pandas缺失数据(初学者需要掌握的几种基本的数据预处理方法_缺失)
文章目录
- 一、string类型的性质
- 1. string与object的区别
- 2. string类型的转换
- 二、拆分与拼接
- 1. str.split方法
- 2. str.cat方法
- 三、替换
- 2. 子组与函数替换
- 四、子串匹配与提取
- 1. str.extract方法
- 2. str.extractall方法
- 3. str.contains和str.match
- 五、常用字符串方法
- 1. 过滤型方法
- 2. isnumeric方法
import pandas as pd
import numpy as np
一、string类型的性质
1. string与object的区别
string类型和object不同之处有三:
① 字符存取方法(string accessor methods,如str.count)会返回相应数据的Nullable类型,而object会随缺失值的存在而改变返回类型
② 某些Series方法不能在string上使用,例如: Series.str.decode(),因为存储的是字符串而不是字节
③ string类型在缺失值存储或运算时,类型会广播为pd.NA,而不是浮点型np.nan
其余全部内容在当前版本下完全一致,但迎合Pandas的发展模式,我们仍然全部用string来操作字符串
2. string类型的转换
如果将一个其他类型的容器直接转换string类型可能会出错:
#pd.Series([1,'1.']).astype('string') #报错
#pd.Series([1,2]).astype('string') #报错
#pd.Series([True,False]).astype('string') #报错
当下正确的方法是分两部转换,先转为str型object,在转为string类型:
pd.Series([1,'1.']).astype('str').astype('string')

pd.Series([1,2]).astype('str').astype('string')

pd.Series([True,False]).astype('str').astype('string')

二、拆分与拼接
1. str.split方法
(a)分割符与str的位置元素选取
s = pd.Series(['a_b_c', 'c_d_e', np.nan, 'f_g_h'], dtype="string")
s
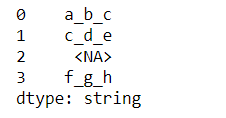
根据某一个元素分割,默认为空格
s.str.split('_')

这里需要注意split后的类型是object,因为现在Series中的元素已经不是string,而包含了list,且string类型只能含有字符串
对于str方法可以进行元素的选择,如果该单元格元素是列表,那么str[i]表示取出第i个元素,如果是单个元素,则先把元素转为列表在取出
s.str.split('_').str[1]
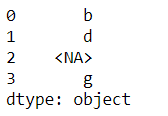
pd.Series(['a_b_c', ['a','b','c']], dtype="object").str[1]
#第一个元素先转为['a','_','b','_','c']

(b)其他参数
expand参数控制了是否将列拆开,n参数代表最多分割多少次
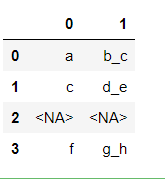
s.str.split('_',expand=True)

s.str.split('_',n=1)

s.str.split('_',expand=True,n=1)
2. str.cat方法
(a)不同对象的拼接模式
cat方法对于不同对象的作用结果并不相同,其中的对象包括:单列、双列、多列
① 对于单个Series而言,就是指所有的元素进行字符合并为一个字符串
s = pd.Series(['ab',None,'d'],dtype='string')
s

s.str.cat()
![]()
其中可选sep分隔符参数,和缺失值替代字符na_rep参数
s.str.cat(sep=',')
![]()
s.str.cat(sep=',',na_rep='*')
![]()
② 对于两个Series合并而言,是对应索引的元素进行合并
s2 = pd.Series(['24',None,None],dtype='string')
s2

s.str.cat(s2)

同样也有相应参数,需要注意的是两个缺失值会被同时替换
s.str.cat(s2,sep=',',na_rep='*')

③ 多列拼接可以分为表的拼接和多Series拼接
表的拼接
s.str.cat(pd.DataFrame({0:['1','3','5'],1:['5','b',None]},dtype='string'),na_rep='*')

多个Series拼接
s.str.cat([s+'0',s*2])

(b)cat中的索引对齐
当前版本中,如果两边合并的索引不相同且未指定join参数,默认为左连接,设置join=‘left’
s2 = pd.Series(list('abc'),index=[1,2,3],dtype='string')
s2
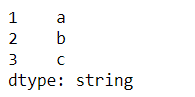
s.str.cat(s2,na_rep='*')

三、替换
广义上的替换,就是指str.replace函数的应用,fillna是针对缺失值的替换,上一章已经提及
提到替换,就不可避免地接触到正则表达式,这里默认读者已掌握常见正则表达式知识点,若对其还不了解的,可以通过这份资料来熟悉
s = pd.Series(['A', 'B', 'C', 'Aaba', 'Baca','', np.nan, 'CABA', 'dog', 'cat'],dtype="string")
s

第一个值写r开头的正则表达式,后一个写替换的字符串
s.str.replace(r'^[AB]','***')

2. 子组与函数替换
通过正整数调用子组(0返回字符本身,从1开始才是子组)
s.str.replace(r'([ABC])(\w+)',lambda x:x.group(2)[1:]+'*')

利用?P<…>表达式可以对子组命名调用
s.str.replace(r'(?P[ABC])(?P\w+)' ,lambda x:x.group('two')[1:]+'*')

3. 关于str.replace的注意事项
首先,要明确str.replace和replace并不是一个东西:
str.replace针对的是object类型或string类型,默认是以正则表达式为操作,目前暂时不支持DataFrame上使用
replace针对的是任意类型的序列或数据框,如果要以正则表达式替换,需要设置regex=True,该方法通过字典可支持多列替换
但现在由于string类型的初步引入,用法上出现了一些问题,这些issue有望在以后的版本中修复
(a)str.replace赋值参数不得为pd.NA
这听上去非常不合理,例如对满足某些正则条件的字符串替换为缺失值,直接更改为缺失值在当下版本就会报错
#pd.Series(['A','B'],dtype='string').str.replace(r'[A]',pd.NA) #报错
#pd.Series(['A','B'],dtype='O').str.replace(r'[A]',pd.NA) #报错
此时,可以先转为object类型再转换回来,曲线救国:
pd.Series(['A','B'],dtype='string').astype('O').replace(r'[A]',pd.NA,regex=True).astype('string')
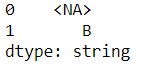
至于为什么不用replace函数的regex替换(但string类型replace的非正则替换是可以的),原因在下面一条
(b)对于string类型Series,在使用replace函数时不能使用正则表达式替换
该bug现在还未修复
pd.Series(['A','B'],dtype='string').replace(r'[A]','C',regex=True)
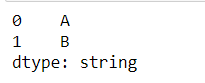
pd.Series(['A','B'],dtype='O').replace(r'[A]','C',regex=True)

(c)string类型序列如果存在缺失值,不能使用replace替换
#pd.Series(['A',np.nan],dtype='string').replace('A','B') #报错
pd.Series(['A',np.nan],dtype='string').str.replace('A','B')
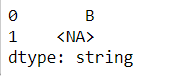
综上,概况的说,除非需要赋值元素为缺失值(转为object再转回来),否则请使用str.replace方法
四、子串匹配与提取
1. str.extract方法
(a)常见用法
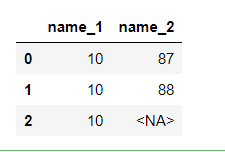
pd.Series(['10-87', '10-88', '10-89'],dtype="string").str.extract(r'([\d]{2})-([\d]{2})')

使用子组名作为列名
pd.Series(['10-87', '10-88', '-89'],dtype="string").str.extract(r'(?P[\d]{2})-(?P[\d]{2})' )
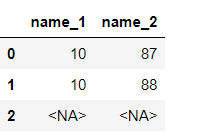
利用?正则标记选择部分提取
pd.Series(['10-87', '10-88', '-89'],dtype="string").str.extract(r'(?P[\d]{2})?-(?P[\d]{2})' )

pd.Series(['10-87', '10-88', '10-'],dtype="string").str.extract(r'(?P[\d]{2})-(?P[\d]{2})?' )
(b)expand参数(默认为True)
对于一个子组的Series,如果expand设置为False,则返回Series,若大于一个子组,则expand参数无效,全部返回DataFrame
对于一个子组的Index,如果expand设置为False,则返回提取后的Index,若大于一个子组且expand为False,报错
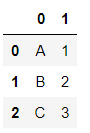
s = pd.Series(["a1", "b2", "c3"], ["A11", "B22", "C33"], dtype="string")
s.index
![]()
s.str.extract(r'([\w])')

s.str.extract(r'([\w])',expand=False)

s.index.str.extract(r'([\w])')

s.index.str.extract(r'([\w])',expand=False)
![]()
s.index.str.extract(r'([\w])([\d])')
#s.index.str.extract(r'([\w])([\d])',expand=False) #报错
2. str.extractall方法
与extract只匹配第一个符合条件的表达式不同,extractall会找出所有符合条件的字符串,并建立多级索引(即使只找到一个)
s = pd.Series(["a1a2", "b1", "c1"], index=["A", "B", "C"],dtype="string")
two_groups = '(?P[a-z])(?P[0-9])'
s.str.extract(two_groups, expand=True)

s.str.extractall(two_groups)
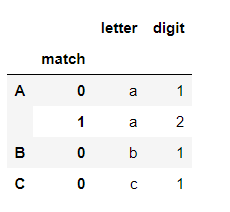
s['A']='a1'
s.str.extractall(two_groups)
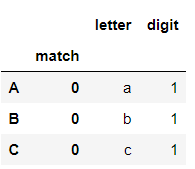
如果想查看第i层匹配,可使用xs方法
s = pd.Series(["a1a2", "b1b2", "c1c2"], index=["A", "B", "C"],dtype="string")
s.str.extractall(two_groups).xs(1,level='match')

3. str.contains和str.match
前者的作用为检测是否包含某种正则模式
pd.Series(['1', None, '3a', '3b', '03c'], dtype="string").str.contains(r'[0-9][a-z]')

可选参数为na
pd.Series(['1', None, '3a', '3b', '03c'], dtype="string").str.contains('a', na=False)

str.match与其区别在于,match依赖于python的re.match,检测内容为是否从头开始包含该正则模式
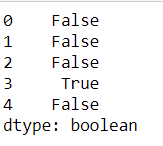
pd.Series(['1', None, '3a_', '3b', '03c'], dtype="string").str.match(r'[0-9][a-z]',na=False)

pd.Series(['1', None, '_3a', '3b', '03c'], dtype="string").str.match(r'[0-9][a-z]',na=False)
五、常用字符串方法
1. 过滤型方法
(a)str.strip
常用于过滤空格
pd.Series(list('abc'),index=[' space1 ','space2 ',' space3'],dtype="string").index.str.strip()`在这里插入代码片`
(b)str.lower和str.upper
pd.Series('A',dtype="string").str.lower()

pd.Series('a',dtype="string").str.upper()

(c)str.swapcase和str.capitalize
分别表示交换字母大小写和大写首字母
pd.Series('abCD',dtype="string").str.swapcase()

pd.Series('abCD',dtype="string").str.capitalize()
![]()
2. isnumeric方法
检查每一位是否都是数字,请问如何判断是否是数值?(问题二)
pd.Series(['1.2','1','-0.3','a',np.nan],dtype="string").str.isnumeric()
代码和数据地址:https://github.com/XiangLinPro/pandas
另外博主收藏这些年来看过或者听过的一些不错的常用的上千本书籍,没准你想找的书就在这里呢,包含了互联网行业大多数书籍和面试经验题目等等。有人工智能系列(常用深度学习框架TensorFlow、pytorch、keras。NLP、机器学习,深度学习等等),大数据系列(Spark,Hadoop,Scala,kafka等),程序员必修系列(C、C++、java、数据结构、linux,设计模式、数据库等等)以下是部分截图
更多文章见本原创微信公众号「五角钱的程序员」,我们一起成长,一起学习。一直纯真着,善良着,温情地热爱生活。关注回复【电子书】即可领取哦。

给大家推荐一个Github,上面非常非常多的干货:https://github.com/XiangLinPro/IT_book
You can’t change how people feel about you, so it is unnecessary to change their opinions. Just enjoy your own life.
你不能改变别人对你的感觉,所以无需尝试。只要享受自己的人生就好!
关于Datawhale
Datawhale是一个专注于数据科学与AI领域的开源组织,汇集了众多领域院校和知名企业的优秀学习者,聚合了一群有开源精神和探索精神的团队成员。Datawhale以“for the learner,和学习者一起成长”为愿景,鼓励真实地展现自我、开放包容、互信互助、敢于试错和勇于担当。同时Datawhale 用开源的理念去探索开源内容、开源学习和开源方案,赋能人才培养,助力人才成长,建立起人与人,人与知识,人与企业和人与未来的联结。