python爬取酷狗音乐两种方法
第一种
打开酷狗音乐 选择一首歌,如下图,
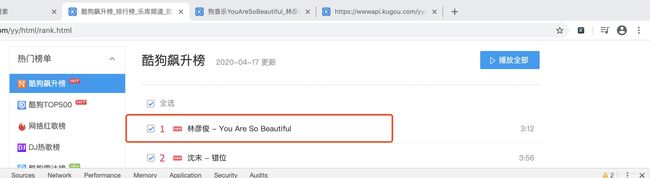
点击该歌曲,会进入新的界面,鼠标右键 选择查看,会看到下面界面,而且在下面的Elements 里面会看到有一个mp3的文件路径
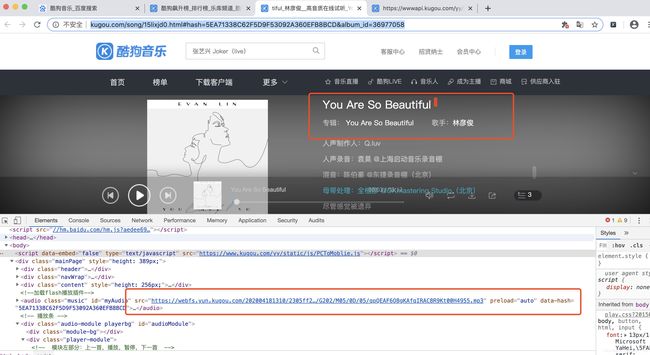
把这个文件路径复制下,直接在浏览器中打开,就会看到下图

就可以听到歌曲,也可以下载下来。所以只要去获取页面源码就行了,代码如下
import requests
url='https://www.kugou.com/song/15lixjd0.html#hash=5EA71338C62F5D9F53092A360EFB8BCD&album_id=36977058'
resp=requests.get(url).text
print(resp)然鹅 在返回的内容没有发现 上面的mp3文件。加上headers也不行
import requests
headers={
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36',
'referer': 'https://www.kugou.com/song/15lixjd0.html',
'cookie': 'kg_mid=de37a1cfd40c173f2820dfe14f530c24; kg_dfid=33MGlt3ida3b0rgFCn3P1T2f; KuGooRandom=6681586955397892; kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e; ACK_SERVER_10015=%7B%22list%22%3A%5B%5B%22bjlogin-user.kugou.com%22%5D%5D%7D; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1586955391,1587184891; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1587184949',
}
url='https://www.kugou.com/song/15lixjd0.html#hash=5EA71338C62F5D9F53092A360EFB8BCD&album_id=36977058'
resp=requests.get(url).text
print(resp)
说明mp3文件那个地址是动态加载的,在回到第一个界面,检查元素,可以看到歌曲的连接地址点击进入,和跳转后的网址不一样,多了一些数据 多了#之后的数据,说明跳转时候做了其他的动作
进入单个歌曲界面选择network ,找到 加载15lixjd0.html 页面进行的一些操作,都在initiator 中进行,
可以在index.php?r.....这个文件中发现所需要的信息
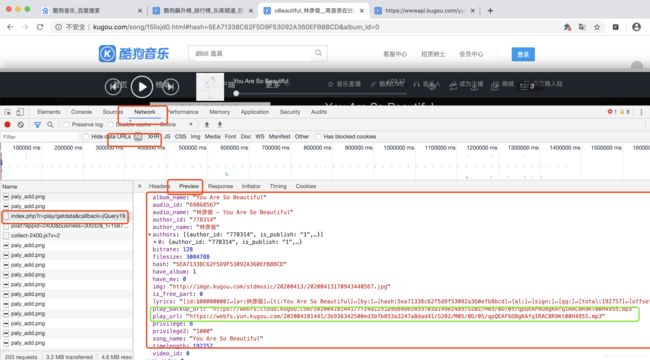
点击headers

拿到url 直接放在浏览器中打开,可以看到返回的数据,里面有需要的数据,同时url不需要那么长,可以删减一部分,可以试着删减, 删除后剩余的 是https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash=5EA71338C62F5D9F53092A360EFB8BCD
import requests
import json
import pprint
headers={
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36',
'referer': 'https://www.kugou.com/song/15lixjd0.html',
'cookie': 'kg_mid=de37a1cfd40c173f2820dfe14f530c24; kg_dfid=33MGlt3ida3b0rgFCn3P1T2f; KuGooRandom=6681586955397892; kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e; ACK_SERVER_10015=%7B%22list%22%3A%5B%5B%22bjlogin-user.kugou.com%22%5D%5D%7D; Hm_lvt_aedee6983d4cfc62f509129360d6bb3d=1586955391,1587184891; Hm_lpvt_aedee6983d4cfc62f509129360d6bb3d=1587184949',
}
# url='https://www.kugou.com/song/15lixjd0.html'
# resp=requests.get(url,headers=headers).text
# print(resp)
url='https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash=5EA71338C62F5D9F53092A360EFB8BCD'
resp=requests.get(url,headers=headers).text
data=json.loads(resp)
pprint.pprint(data)
song_url=data['data']['play_url']
print(song_url)
resp=requests.get(url,headers=headers).content
with open('kugou.mp3','wb') as f:
f.write(resp)
运行结果为
想批量下载的话 就只需要歌曲的
url='https://wwwapi.kugou.com/yy/index.php?r=play/getdata&hash=5EA71338C62F5D9F53092A360EFB8BCD' 这里面只需要获取hash 就可以。在 第一页面搜索hash
获取这些hash就可以了,完整的代码