快速入门Flink (9) —— DataStream API 开发之【Time 与 Window】
写在前面: 博主是一名软件工程系大数据应用开发专业的学生,昵称来源于《爱丽丝梦游仙境》中的Alice和自己的昵称。作为一名互联网小白,
写博客一方面是为了记录自己的学习历程,一方面是希望能够帮助到很多和自己一样处于起步阶段的萌新。由于水平有限,博客中难免会有一些错误,有纰漏之处恳请各位大佬不吝赐教!个人小站:http://alices.ibilibili.xyz/ , 博客主页:https://alice.blog.csdn.net/
尽管当前水平可能不及各位大佬,但我还是希望自己能够做得更好,因为一天的生活就是一生的缩影。我希望在最美的年华,做最好的自己!
本文是快速入门Flink的第九篇博客,主要介绍的是关于DataStream API的开发,其中涉及到一些抽象性名词,理解起来会有点难度,希望大家认真阅读ヽ( ̄▽ ̄)ノ
码字不易,先赞后看!!!

文章目录
- DataStream API 开发
- 1、Time 与 Window
- 1.1 Time
- 1.2 Window
- 1.2.1 Window 概述
- 1.2.2 Window 类型
- 1.3 Window API
- 1.3.1 CountWindow
- 1.3.2 TimeWindow
- 1.3.3 Window Reduce
- 1.3.4 Window Apply
- 1.3.5 Window Fold
- 1.3.6 Aggregation on Window
- 小结
DataStream API 开发
1、Time 与 Window
1.1 Time
在 Flink 的流式处理中,会涉及到时间的不同概念,如下图所示:
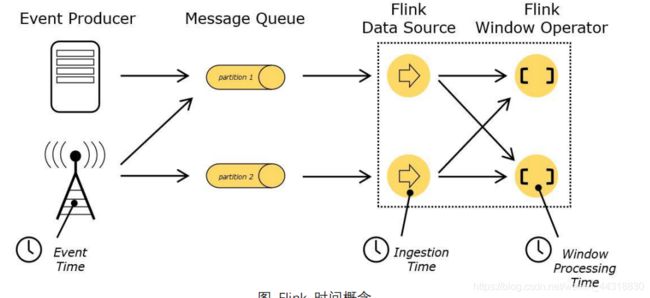
Event Time:是事件创建的时间。它通常由事件中的时间戳描述,例如采集的日志数据中, 每一条日志都会记录自己的生成时间,Flink 通过时间戳分配器访问事件时间戳。
Ingestion Time:是数据进入 Flink 的时间。
Processing Time:是每一个执行基于时间操作的算子的本地系统时间,与机器相关,默认的时间属性就是 Processing Time。
例如,一条日志进入 Flink 的时间为 2019-08-12 10:00:00.123,到达 Window 的系统时间为:
2019-08-12 10:00:01.234,
日志的内容如下:
2019-08-02 18:37:15.624 INFO Fail over to rm2
对于业务来说,要统计 1min 内的故障日志个数,哪个时间是最有意义的?—— eventTime, 因为我们要根据日志的生成时间进行统计。
1.2 Window
1.2.1 Window 概述
Streaming 流式计算是一种被设计用于处理无限数据集的数据处理引擎,而无限数据集是指一种不断增长的本质上无限的数据集,而 window 是一种切割无限数据为有限块进行处理的手段。
Window 是无限数据流处理的核心,Window 将一个无限的 stream 拆分成有限大小的”buckets”桶,我们可以在这些桶上做计算操作。
1.2.2 Window 类型
Window 可以分成两类:
1) CountWindow:按照指定的数据条数生成一个 Window,与时间无关。
2) TimeWindow:按照时间生成 Window。
对于 TimeWindow,可以根据窗口实现原理的不同分成三类:滚动窗口(Tumbling Window)、 滑动窗口(Sliding Window)和会话窗口(Session Window)。
- 滚动窗口(Tumbling Windows)
将数据依据固定的窗口长度对数据进行切片。
特点:时间对齐,窗口长度固定,没有重叠。
滚动窗口分配器将每个元素分配到一个指定窗口大小的窗口中,滚动窗口有一个固定的大小,并且不会出现重叠。例如:如果你指定了一个 5 分钟大小的滚动窗口,窗口的创建如下图所示:

适用场景:适合做 BI 统计等(做每个时间段的聚合计算)
- 滑动窗口(Sliding Windows)
滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成。
特点:时间对齐,窗口长度固定,有重叠。
滑动窗口分配器将元素分配到固定长度的窗口中,与滚动窗口类似,窗口的大小由窗口大小参数来配置,另一个窗口滑动参数控制滑动窗口开始的频率。因此,滑动窗口如果滑动参数小于窗口大小的话,窗口是可以重叠的,在这种情况下元素会被分配到多个窗口中。 例如,你有 10 分钟的窗口和 5 分钟的滑动,那么每个窗口中 5 分钟的窗口里包含着上个 10 分钟产生的数据。
如下图所示:
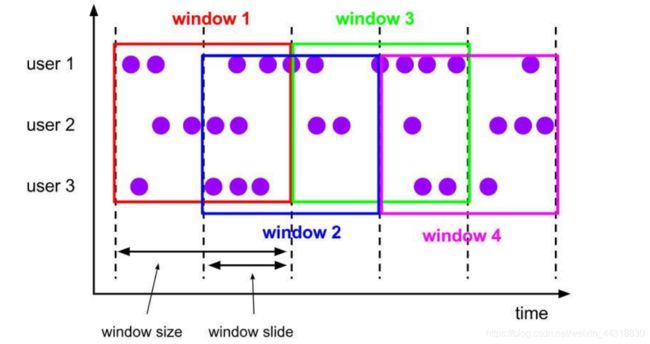
适用场景:对最近一个时间段内的统计(求某接口最近 5min 的失败率来决定是否要报警)
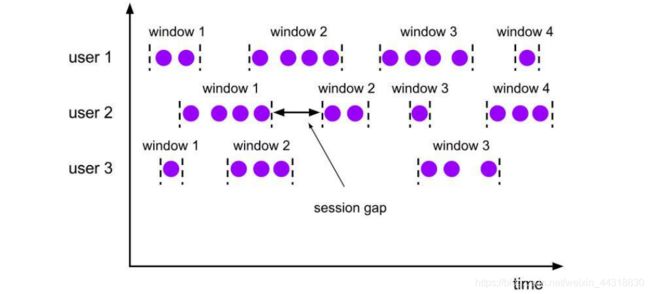
- 会话窗口(Session Windows)
由一系列事件组合一个指定时间长度的 timeout 间隙组成,类似于 web 应用的 session, 也就是一段时间没有接收到新数据就会生成新的窗口。
特点:时间无对齐。
session 窗口分配器通过 session 活动来对元素进行分组,session 窗口跟滚动窗口和滑动窗口相比,不会有重叠和固定的开始时间和结束时间的情况,相反,当它在一个固定的时间周期内不再收到元素,即非活动间隔产生,那个这个窗口就会关闭。一个 session 窗口通过一个 session 间隔来配置,这个 session 间隔 定义了非活跃周期的长度,当这个非活跃周期产生,那么当前的 session 将关闭并且后续的元素将被分配到新的 session 窗口中去。
1.3 Window API
下面介绍一些流数据处理中常用的一些Window API。
1.3.1 CountWindow
CountWindow 根据窗口中相同 key 元素的数量来触发执行,执行时只计算元素数量达到窗口大小的 key 对应的结果。
默认的 CountWindow 是一个滚动窗口,只需要指定窗口大小即可,当元素数量达到窗口大小时,就会触发窗口的执行。
步骤:
1.获取执行环境
2.创建 SocketSource
3.对 stream 进行处理并按 key 聚合
4.countWindow 操作
5.执行聚合操作
6.将聚合数据输出
7.执行程序
- 参考代码
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.streaming.api.scala.{DataStream, KeyedStream, StreamExecutionEnvironment, WindowedStream}
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow
/*
* @Author: Alice菌
* @Date: 2020/7/10 09:22
* @Description:
*/
object StreamCountWindow {
def main(args: Array[String]): Unit = {
// 1、创建执行环境
val senv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 2、 构建数据源 , 创建 SocketSource
val socketSource: DataStream[String] = senv.socketTextStream("node01",9999)
// 3、 对 stream 进行处理并按 key 聚合
import org.apache.flink.api.scala._
val keyByStream: KeyedStream[(String, Int), Tuple] = socketSource.flatMap(x=>x.split(" ")).map((_, 1)).keyBy(0)
// 4、 引入 countWindow 操作
// 这里的 5 指的是 5 个相同的 key 的元素计算一次
val streamWindow: WindowedStream[(String, Int), Tuple, GlobalWindow] = keyByStream.countWindow(5)
// 执行聚合操作
val reduceStream: DataStream[(String, Int)] = streamWindow.reduce((v1,v2) => (v1._1,v1._2 + v2._2))
// 将聚合数据输出
reduceStream.print(this.getClass.getSimpleName)
// 执行程序
senv.execute("StreamCountWindow")
}
}
- 演示效果
我们打开node01节点上的9999通信端口。
nc -lk 9999
然后制造一些信息。

此时观察控制台,可以发现将key的个数等于5的结果展示了出来。

1.3.2 TimeWindow
TimeWindow 是将指定时间范围内的所有数据组成一个 window,一次对一个 window 里面的所有数据进行计算。
Flink 默认的时间窗口根据 Processing Time 进行窗口的划分,将 Flink 获取到的数据 根据进入 Flink 的时间 划分到不同的窗口中。
步骤:
1.获取执行环境
2.创建你 socket 链接获取数据
3.进行数据转换处理并按 key 聚合
4.引入 timeWindow
5.执行聚合操作
6.输出打印数据
7.执行程序
- 参考代码
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.streaming.api.scala.{DataStream, KeyedStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
/*
* @Author: Alice菌
* @Date: 2020/8/10 23:53
* @Description:
*/
object StreamTimeWindow {
def main(args: Array[String]): Unit = {
//1.获取执行环境
val senv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//2.创建socket链接获取数据
val socketSource: DataStream[String] = senv.socketTextStream("node01", 9999)
//3.进行数据转换处理并按 key 聚合
val keyByStream: KeyedStream[(String, Int), Tuple] = socketSource.flatMap(x => x.split(" ")).map((_, 1)).keyBy(0)
//4.引入滚动窗口
val timeWindowStream: WindowedStream[(String, Int), Tuple, TimeWindow] = keyByStream.timeWindow(Time.seconds(5))
//5.执行聚合操作
val reduceStream: DataStream[(String, Int)] = timeWindowStream.reduce(
(item1, item2) => (item1._1, item1._2 + item2._2)
)
//6.输出打印数据
reduceStream.print()
//7.执行程序
senv.execute("StreamTimeWindow")
}
}
- 演示效果

观察程序的控制台,发现每达到5秒,就会计算一个窗口内的数据。

1.3.3 Window Reduce
这意味着 WindowedStream → DataStream:给 window 赋一个 reduce 功能的函数,并返回一个聚合的结果。
- 参考代码
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.streaming.api.scala.{DataStream, KeyedStream, StreamExecutionEnvironment, WindowedStream}
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
/*
* @Author: Alice菌
* @Date: 2020/8/11 09:38
* @Description:
*/
object StreamReduceWindow {
def main(args: Array[String]): Unit = {
// 1、 获取执行环境
val senv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 创建 SocketSource
val stream: DataStream[String] = senv.socketTextStream("node01",9999)
// 对 stream 进行处理并按 key 聚合
val streamKeyBy: KeyedStream[(String, Int), Tuple] = stream.flatMap(x => x.split("0")).map(item => (item,1)).keyBy(0)
// 引入时间窗口
val streamWindow: WindowedStream[(String, Int), Tuple, TimeWindow] = streamKeyBy.timeWindow(Time.seconds(5))
// 执行聚合操作
val streamReduce: DataStream[(String, Int)] = streamWindow.reduce(
(item1, item2) => (item1._1, item1._2 + item2._2)
)
// 将聚合数据写入文件
streamReduce.print()
// 执行程序
senv.execute("StreamReduceWindow")
}
}
因为效果和上边介绍的TimeWindow是一样的,所以这里就不做演示了。
1.3.4 Window Apply
apply 方法可以进行一些自定义处理,通过匿名内部类的方法来实现。当有一些复杂计算时使用。
用法
-
实现一个 WindowFunction 类
-
指定该类的泛型为 [输入数据类型, 输出数据类型, keyBy 中使用分组字段的类型, 窗 口类型]
示例
使用 apply 方法来实现单词统计
步骤
1) 获取流处理运行环境
2) 构建 socket 流数据源,并指定 IP 地址和端口号
3) 对接收到的数据转换成单词元组
4) 使用 keyBy 进行分流(分组)
5) 使用 timeWinodw 指定窗口的长度(每 3 秒计算一次)
6) 实现一个 WindowFunction 匿名内部类
■ apply 方法中实现聚合计算
■ 使用 Collector.collect 收集数据
7) 打印输出
8) 启动执行
9) 在 Linux 中,使用 nc -lk 端口号 监听端口,并发送单词
参考代码
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.scala.function.RichWindowFunction
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
/*
* @Author: Alice菌
* @Date: 2020/8/11 09:58
* @Description:
使用 apply 实现单词统计
apply 方法可以进行一些自定义处理,通过匿名内部类的方法来实现。
当有一些复杂计算时使用。
*/
object StreamApplyWindow {
def main(args: Array[String]): Unit = {
// 1、获取流处理运行环境
val senv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 2、构建 socket 流数据源,并指定 IP 地址和端口
val textDataStream: DataStream[String] = senv.socketTextStream("node01",9999).flatMap(_.split(" "))
// 3、对接收到的数据转换成单词元组
val wordDataStream: DataStream[(String, Int)] = textDataStream.map((_,1))
// 4、使用 keyBy 进行分流(分组)
val groupedDataStream: KeyedStream[(String, Int), String] = wordDataStream.keyBy(_._1)
// 5、使用 timeWindow 指定窗口的长度(每3秒计算一次)
val windowDataStream: WindowedStream[(String, Int), String, TimeWindow] = groupedDataStream.timeWindow(Time.seconds(3))
// 6、实现一个 WindowFunction 匿名内部类
/*
@tparam IN The type of the input value. 输入值的类型
* @tparam OUT The type of the output value. 输出值的类型
* @tparam KEY The type of the key. key值的类型
* @tparam W The type of Window that this window function can be applied on. 可以应用此窗口功能的窗口类型
*/
val reduceDataStream: DataStream[(String, Int)] = windowDataStream.apply(new RichWindowFunction[(String, Int), (String, Int), String, TimeWindow] {
// 自定义操作,在apply 方法中实现数据的聚合
override def apply(key: String, window: TimeWindow, input: Iterable[(String, Int)], out: Collector[(String, Int)]): Unit = {
val tuple: (String, Int) = input.reduce((t1, t2) => {
(t1._1, t1._2 + t2._2)
})
// 将要返回的数据收集起来,发送回去
out.collect(tuple)
}
})
// 打印结果
reduceDataStream.print()
// 执行程序
senv.execute("StreamApplyWindow")
}
}
同上,效果和上边介绍的TimeWindow是一样的,所以这里就不做演示了。
1.3.5 Window Fold
WindowedStream → DataStream:给窗口赋一个 fold 功能的函数,并返回一个 fold 后的结果。
参考代码
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
/*
* @Author: Alice菌
* @Date: 2020/8/11 10:31
* @Description:
*/
object StreamFoldWindow {
def main(args: Array[String]): Unit = {
// 1、获取执行环境
val senv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 创建 SocketSource
val stream: DataStream[String] = senv.socketTextStream("node01",9999)
// 对 stream 进行处理并按 key 聚合
val streamKeyBy: KeyedStream[(String, Int), Tuple] = stream.flatMap(x => x.split(" ")).map((_,1)).keyBy(0)
// 引入滚动窗口
val streamWindow: WindowedStream[(String, Int), Tuple, TimeWindow] = streamKeyBy.timeWindow(Time.seconds(3))
// 执行 fold 操作
val streamFold: DataStream[Int] = streamWindow.fold(100) {
(begin, item) => begin + item._2
}
// 将聚合数据写入文件
streamFold.print()
// 执行程序
senv.execute("StreamFoldWindow")
}
}
演示效果
客户端

程序控制台

1.3.6 Aggregation on Window
WindowedStream → DataStream:对一个 window 内的所有元素做聚合操作。min 和 minBy 的区别是 min 返回的是最小值,而 minBy 返回的是包含最小值字段的元素(同样的原理适 用于 max 和 maxBy)。
参考代码
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
/*
* @Author: Alice菌
* @Date: 2020/8/11 16:21
* @Description:
*/
object StreamAggregationWindow {
def main(args: Array[String]): Unit = {
// 获取执行环境
val senv: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
// 创建 SocketSource
val socketStream: DataStream[String] = senv.socketTextStream("node01",9999)
// 对 stream 进行处理并按 key 聚合
val keyByStream: KeyedStream[(String, String), Tuple] = socketStream.map(item => (item.split(" ")(0),item.split(" ")(1))).keyBy(0)
// 引入滚动窗口
val streamWindow: WindowedStream[(String, String), Tuple, TimeWindow] = keyByStream.timeWindow(Time.seconds(5))
// 执行聚合操作
val streamMax: DataStream[(String, String)] = streamWindow.max(1)
// 将聚合数据输出
streamMax.print()
// 执行程序
senv.execute("StreamAggregationWindow")
}
}
演示效果
客户端

程序控制台

小结
本篇博客主要为大家介绍了Flink流处理DataStreamAPI 开发中,关于 【Time与Window】方面的知识内容,下一篇博客将为大家介绍同系列 【EventTime 与 Window】,敬请期待
如果以上过程中出现了任何的纰漏错误,烦请大佬们指正
受益的朋友或对大数据技术感兴趣的伙伴记得点赞关注支持一波
希望我们都能在学习的道路上越走越远
