学习笔记|Pytorch使用教程11(nn网络层-卷积层)
学习笔记|Pytorch使用教程11
本学习笔记主要摘自“深度之眼”,做一个总结,方便查阅。
使用Pytorch版本为1.2
- 1d/2d/3d卷积
- 卷积–nn.Conv2d()
- 转置卷积–nn.ConvTranspose
一.1d/2d/3d卷积

AlexNet卷积可视化,发现卷积核学习到的是边缘,条纹,色彩这一些细节模式。

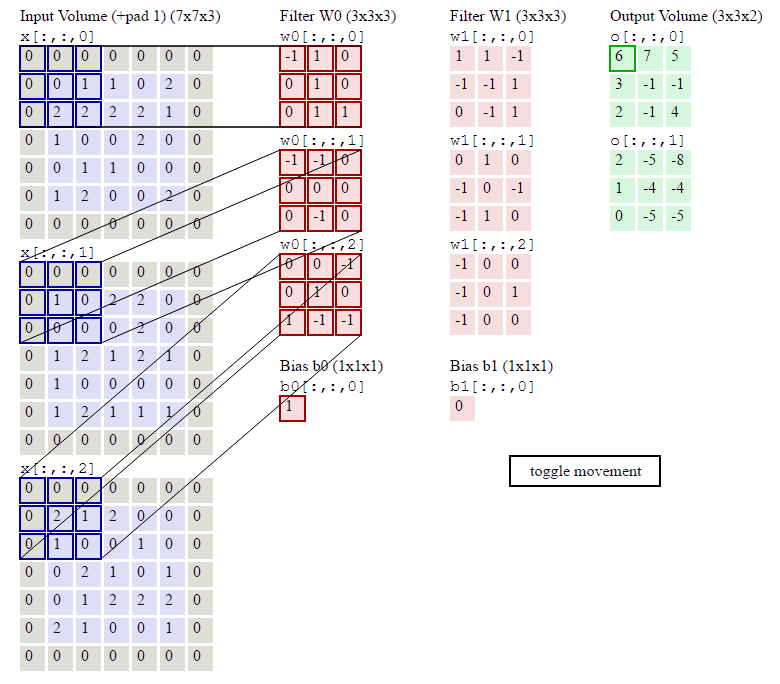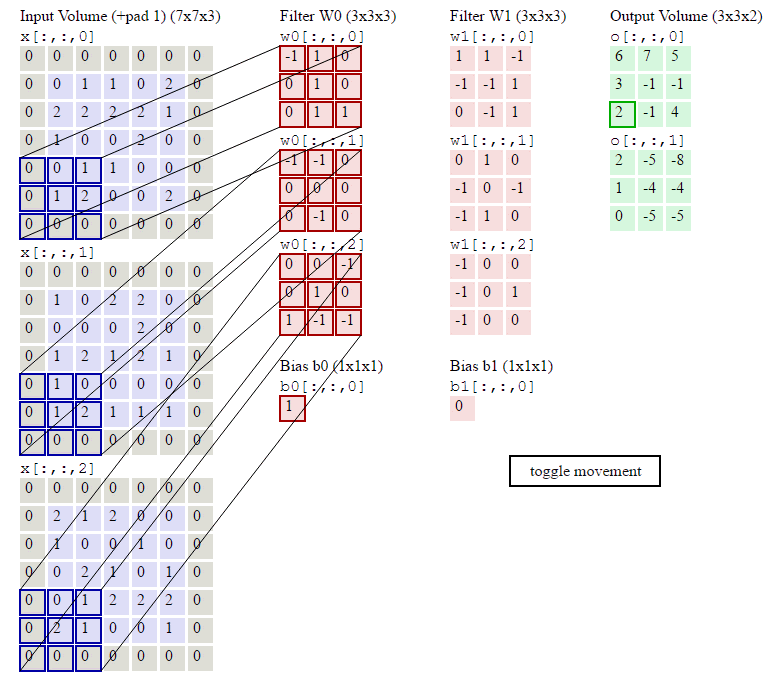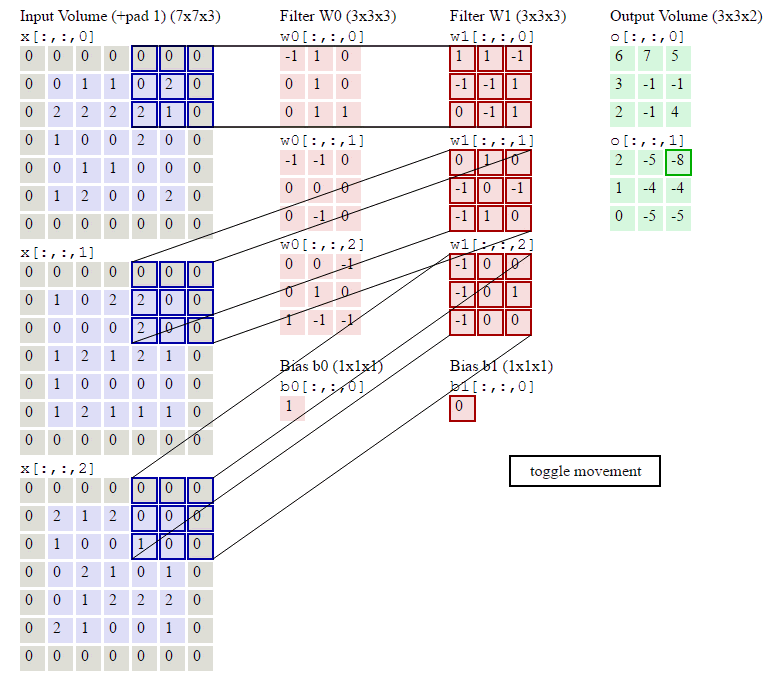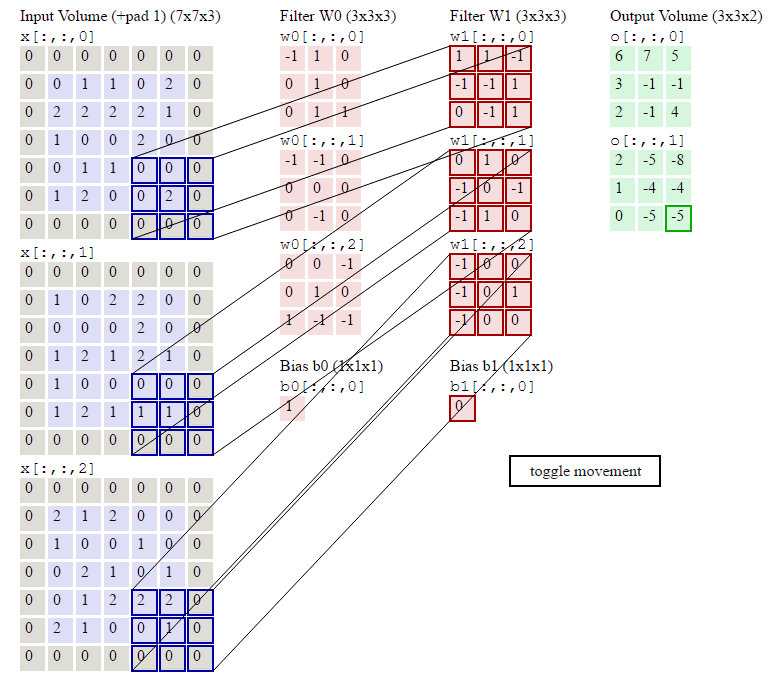
卷积维度:一般情况下,卷积核在几个维度上滑动,就是几维卷积。
- 一维卷积:
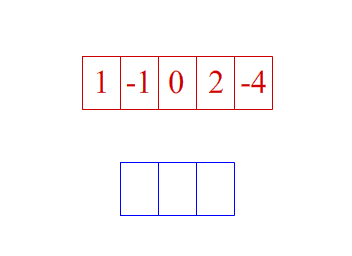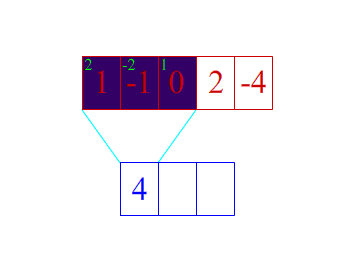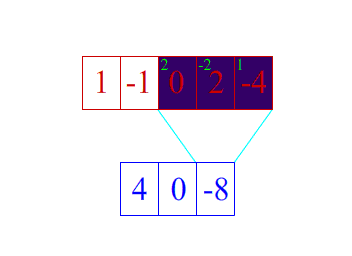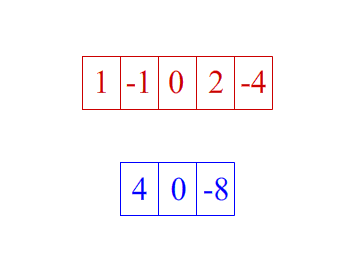
- 二维卷积:
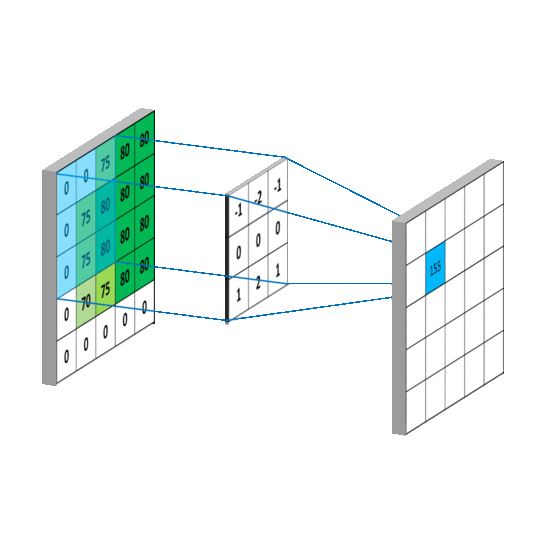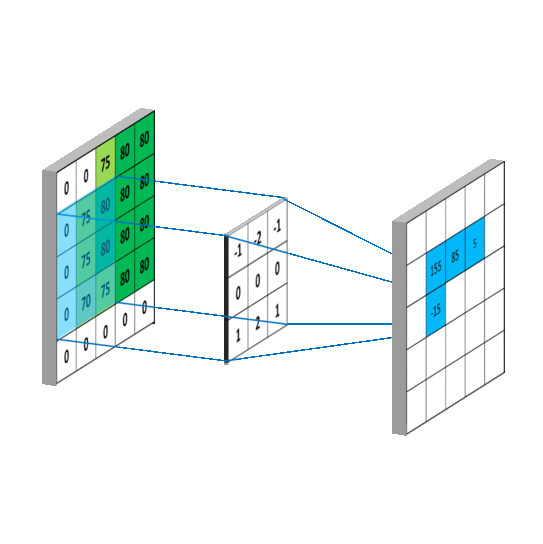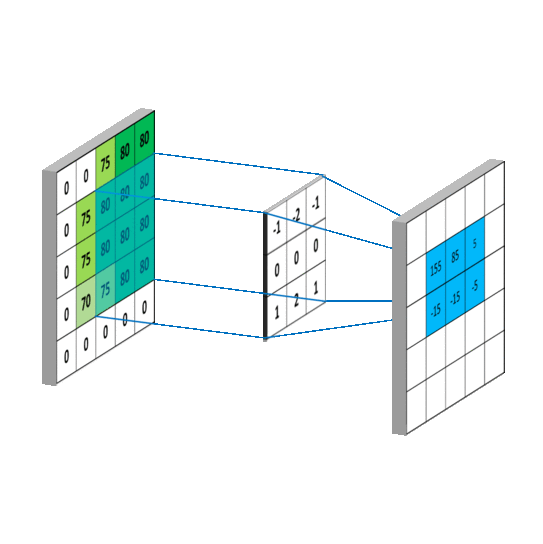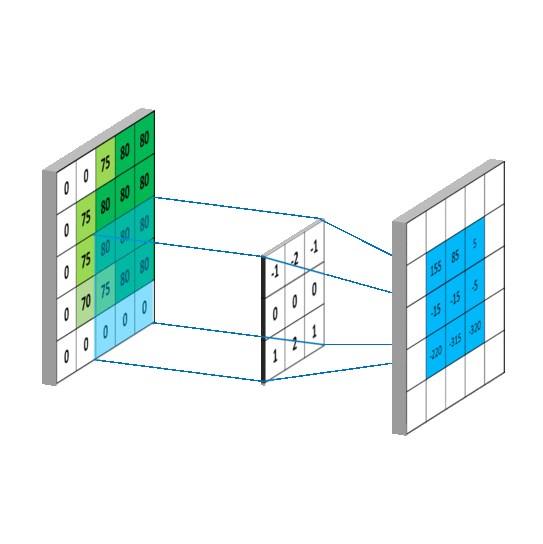
- 三维卷积:
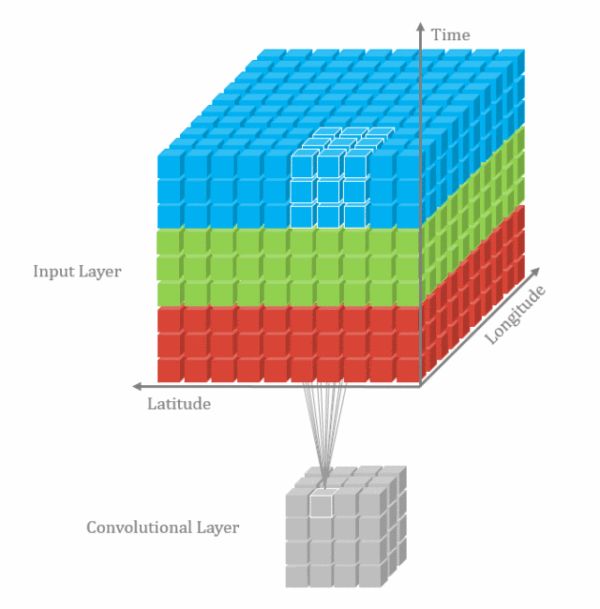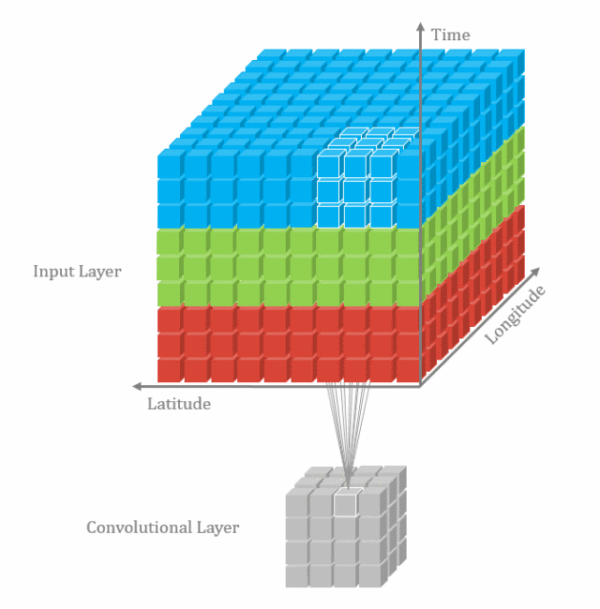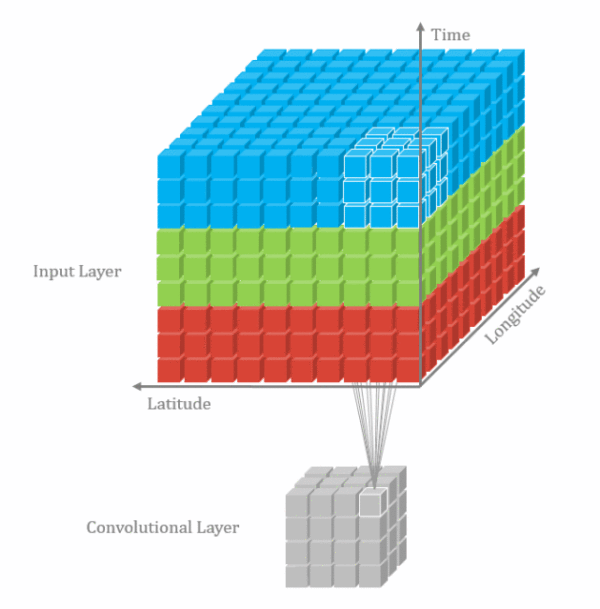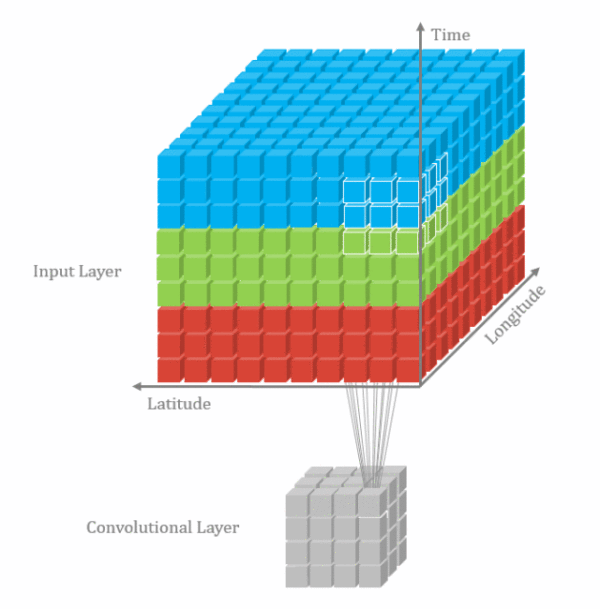
二.卷积–nn.Conv2d()
1.nn.Conv2d()
功能:对多个二维信号进行二维卷积
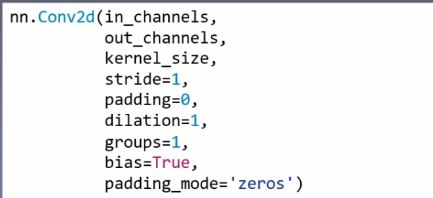
主要参数:
- in_channels:输入通道
- out_channels:输出通道,等价于卷积核个数
- kernel_size:卷积核尺寸
- stride:步长
- padding:填充个数
- dilation:空洞卷积大小
- groups:分组卷积设置
- bias:偏置
空洞卷积:
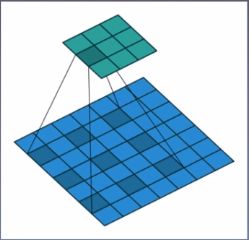
- 尺寸计算:
简化版:
out size = I n size − kernel size stride + 1 _{\text {size }}=\frac{I n_{\text {size }}-\text {kernel}_{\text {size}}}{\text {stride}}+1 size =strideInsize −kernelsize+1
完整版:
H o u t = ⌊ H i n + 2 × padding [ 0 ] − dilation [ 0 ] × ( kerneL size [ 0 ] − 1 ) − 1 stride [ 0 ] + 1 ⌋ H_{o u t}=\left\lfloor\frac{H_{i n}+2 \times \text { padding }[0]-\text { dilation }[0] \times(\text { kerneL size }[0]-1)-1}{\text { stride }[0]}+1\right\rfloor Hout=⌊ stride [0]Hin+2× padding [0]− dilation [0]×( kerneL size [0]−1)−1+1⌋
测试代码:
import os
import torch.nn as nn
from PIL import Image
from torchvision import transforms
from matplotlib import pyplot as plt
from tools.common_tools import transform_invert#, set_seed
import random
random.seed(1)
#set_seed(3) # 设置随机种子
# ================================= load img ==================================
path_img = os.path.join(os.path.dirname(os.path.abspath(__file__)), "lena.png")
img = Image.open(path_img).convert('RGB') # 0~255
# convert to tensor
img_transform = transforms.Compose([transforms.ToTensor()])
img_tensor = img_transform(img)
img_tensor.unsqueeze_(dim=0) # C*H*W to B*C*H*W
# ================================= create convolution layer ==================================
# ================ 2d
flag = 1
# flag = 0
if flag:
conv_layer = nn.Conv2d(3, 1, 3) # input:(i, o, size) weights:(o, i , h, w)
nn.init.xavier_normal_(conv_layer.weight.data)
# calculation
img_conv = conv_layer(img_tensor)
# ================ transposed
# flag = 1
flag = 0
if flag:
conv_layer = nn.ConvTranspose2d(3, 1, 3, stride=2) # input:(i, o, size)
nn.init.xavier_normal_(conv_layer.weight.data)
# calculation
img_conv = conv_layer(img_tensor)
# ================================= visualization ==================================
print("卷积前尺寸:{}\n卷积后尺寸:{}".format(img_tensor.shape, img_conv.shape))
img_conv = transform_invert(img_conv[0, 0:1, ...], img_transform)
img_raw = transform_invert(img_tensor.squeeze(), img_transform)
plt.subplot(122).imshow(img_conv, cmap='gray')
plt.subplot(121).imshow(img_raw)
plt.show()
import numpy as np
import torch
import torchvision.transforms as transforms
from PIL import Image
import random
def set_seed(seed=1):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
def transform_invert(img_, transform_train):
"""
将data 进行反transfrom操作
:param img_: tensor
:param transform_train: torchvision.transforms
:return: PIL image
"""
if 'Normalize' in str(transform_train):
norm_transform = list(filter(lambda x: isinstance(x, transforms.Normalize), transform_train.transforms))
mean = torch.tensor(norm_transform[0].mean, dtype=img_.dtype, device=img_.device)
std = torch.tensor(norm_transform[0].std, dtype=img_.dtype, device=img_.device)
img_.mul_(std[:, None, None]).add_(mean[:, None, None])
img_ = img_.transpose(0, 2).transpose(0, 1) # C*H*W --> H*W*C
if 'ToTensor' in str(transform_train):
#img_ = np.array(img_) * 255
img_ = img_.cpu().detach().numpy() * 255
if img_.shape[2] == 3:
img_ = Image.fromarray(img_.astype('uint8')).convert('RGB')
elif img_.shape[2] == 1:
img_ = Image.fromarray(img_.astype('uint8').squeeze())
else:
raise Exception("Invalid img shape, expected 1 or 3 in axis 2, but got {}!".format(img_.shape[2]) )
return img_
输出:
卷积前尺寸:torch.Size([1, 3, 512, 512])
卷积后尺寸:torch.Size([1, 1, 510, 510])
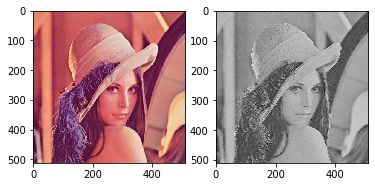
修改随机种子:
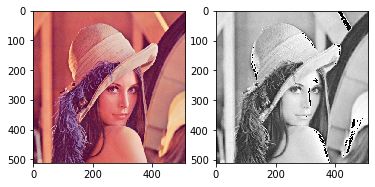
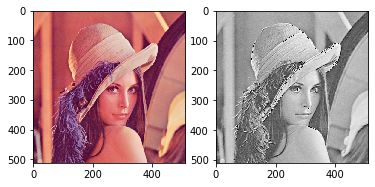
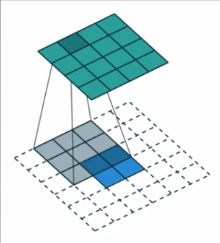
运算过程参考图示:
三.转置卷积–nn.ConvTranspose
转置卷积又称反卷积(Deconvolution)和部分跨越卷积(Fractionally-strided Convolution),用于对图像进行上采样(Upsample)。
参见知乎高票答案。
理解卷积
以及Github


1.nn.ConvTranspose2d
功能:转置卷积实现上采样

主要参数:
- in_channels:输入通道
- out_channels:输出通道,等价于卷积核个数
- kernel_size:卷积核尺寸
- stride:步长
- padding:填充个数
- dilation:空洞卷积大小
- groups:分组卷积设置
- bias:偏置
- 尺寸计算:
简化版(与正常卷积想法):
out size = ( in size − 1 ) ∗ =\left(\text { in }_{\text {size }}-1\right) * =( in size −1)∗ stride + + + kernel size _{\text {size }} size
完整版:
H out = ( H in − 1 ) × H_{\text {out}}=\left(H_{\text {in}}-1\right) \times Hout=(Hin−1)× stride [ 0 ] − 2 × [0]-2 \times [0]−2× padding [ 0 ] + [0]+ [0]+ dilation [ 0 ] × [0] \times [0]× (kernel size [ 0 ] − 1 [0]-1 [0]−1 ) + + + output-padding [ 0 ] + 1 [0]+1 [0]+1
测试代码:
# ================ transposed
flag = 1
# flag = 0
if flag:
conv_layer = nn.ConvTranspose2d(3, 1, 3, stride=2) # input:(i, o, size)
nn.init.xavier_normal_(conv_layer.weight.data)
# calculation
img_conv = conv_layer(img_tensor)
输出:
卷积前尺寸:torch.Size([1, 3, 512, 512])
卷积后尺寸:torch.Size([1, 1, 1025, 1025])
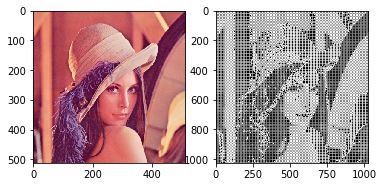
棋盘效应:推荐文章《DeconOlutioN and Checkerboard Artifacts.》