darknet框架YOLO+VOC使用笔记
一、darknet框架配置
github网址
https://github.com/pjreddie/darknet
Linux终端操作
git clone https://github.com/pjreddie/darknet
cd darknet
make
在windows操作系统上跑YOLO可以使用cygwin
下载预训练权重
wget https://pjreddie.com/media/files/yolov3.weights
使用data文件夹下的dog.jpg文件测试
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg
终端输出:
layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs
1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BFLOPs
.......
105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BFLOPs
106 detection
truth_thresh: Using default '1.000000'
Loading weights from yolov3.weights...Done!
data/dog.jpg: Predicted in 0.029329 seconds.
dog: 99%
truck: 93%
bicycle: 99%
darknet文件夹下会产生“prediction.jpg”:
注意上面的命令是下面的命令的缩写:
./darknet detector test cfg/coco.data cfg/yolov3.cfg yolov3.weights data/dog.jpg
命令中也可以先不写图片的路径,会产生如下的输出:
./darknet detect cfg/yolov3.cfg yolov3.weights
layer filters size input output
0 conv 32 3 x 3 / 1 416 x 416 x 3 -> 416 x 416 x 32 0.299 BFLOPs
1 conv 64 3 x 3 / 2 416 x 416 x 32 -> 208 x 208 x 64 1.595 BFLOPs
.......
104 conv 256 3 x 3 / 1 52 x 52 x 128 -> 52 x 52 x 256 1.595 BFLOPs
105 conv 255 1 x 1 / 1 52 x 52 x 256 -> 52 x 52 x 255 0.353 BFLOPs
106 detection
Loading weights from yolov3.weights...Done!
Enter Image Path:
此时可以再输入如 data/dog.jpg 的图片路径
改变threshold
YOLO默认输出confidence大于等于0.25的物体,以下命令可以输出所有检测到的物体(不论confidence是多少):
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg -thresh 0
Tiny YOLOv3 与其他版本的YOLO
yolo3-tiny是yolo3的简化版本,网络结构简单,速度快精度低,关于网络结构可以看https://blog.csdn.net/weixin_42754237/article/details/86548262
darknet下的cfg文件夹有tiny YOLO与YOLOv1,YOLOv2的配置文件,如果要使用其他版本,需要下载相应的权重文件,并将上面命令中的 “yolov3.cfg” 与 “yolov3.weights”改掉。
如下载Tiny YOLOv3权重文件:
wget https://pjreddie.com/media/files/yolov3-tiny.weights
使用Tiny YOLOv3:
./darknet detect cfg/yolov3-tiny.cfg yolov3-tiny.weights data/dog.jpg
二、VOC数据集
数据集下载:
http://host.robots.ox.ac.uk:8080
一般目标检测常用的是 VOC2007 和 VOC2012 数据集,因为二者是互斥的,而VOC2012test没有公布,所以一般使用 VOC2007 和 VOC2012 的 train+val 训练,然后使用 VOC2007 的 test 测试。
VOC2007数据集下载解压后包含的内容如下所示:
(1)Annotations文件夹
包含所有文件的标注信息,以.xml文件组织,如:
>
>VOC2007 > #文件夹名
>000001.jpg > # 文件名
>
>The VOC2007 Database >
>PASCAL VOC2007 >
>flickr >
>341012865 >
>
>
>Fried Camels >
>Jinky the Fruit Bat >
>
> # 图像尺寸, 用于对 bbox 左上和右下坐标点做归一化操作
>353 >
>500 >
>3 >
>
>0 > # 是否用于分割
>
>dog > # 物体类别
>Left > # 拍摄角度:front, rear, left, right, unspecified
>1 > # 目标是否被截断(比如在图片之外),或者被遮挡(超过15%)
>0 > # 检测难易程度,这个主要是根据目标的大小,光照变化,图片质量来判断
> #bound box位置
>48 >
>240 >
>195 >
>371 >
>
>
>
>person >
>Left >
>1 >
>0 >
>
>8 >
>12 >
>352 >
>498 >
>
>
>
(2)ImageSets文件夹
ImagesSets文件夹下有三个文件夹:

Layout文件夹

train.txt中保存用于训练的图片的名称,val.txt中保存用于验证的图片的名称,trainval.txt中保存所有用于训练和验证的图片名称。
Main文件夹
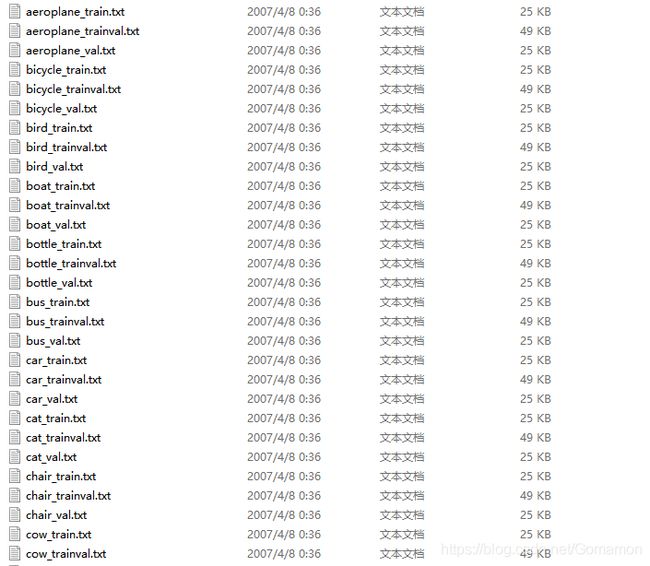
保存所有20种种类在训练、验证图片中是否存在的信息,1表示存在,-1表示不存在,如:
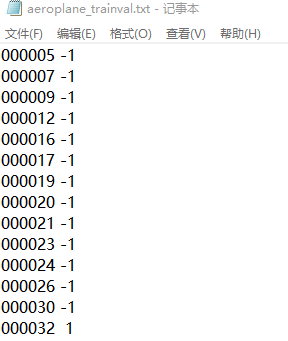
表示 飞机 在上面所有图片中不存在,在000032中存在。
Segmentation文件夹
内容与Layout文件夹基本一致,不过是图像分割的信息而不是图像识别的信息。
(3)JPEGImages文件夹
保存数据集中所有图片。
SegmentationClass文件夹与SegmentationObject文件夹是关于图像分割的内容
VOC2012数据集在20种类别之外新增了10种动作信息(Action),因此Annotations文件夹下的标注信息多了动作信息,ImageSets文件夹多了Action文件夹,其余内容与VOC2007相同。
三、YOLO训练VOC数据集
将VOC2007、VOC2007 test与VOC2012下载解压并都放入VOCdevkit文件夹内(解压后会自动产生)注意VOC2007 test与VOC2007解压后会有相同的文件名VOC2007,需要将测试数据的文件名修改为VOC2007_test(也可以改成别的)。
wget https://pjreddie.com/media/files/VOCtrainval_11-May-2012.tar
wget https://pjreddie.com/media/files/VOCtrainval_06-Nov-2007.tar
wget https://pjreddie.com/media/files/VOCtest_06-Nov-2007.tar
tar xf VOCtrainval_11-May-2012.tar
tar xf VOCtrainval_06-Nov-2007.tar
tar xf VOCtest_06-Nov-2007.tar
建议将VOC数据放入darknet文件夹下的data文件夹中。
找到scipts文件夹中的voc_label.py文件,放至VOCdevkit同一目录下。
打开voc_label.py文件,修改第7行,将列表的最后一个元组修改为(‘2007_test’,‘test’);修改第58行,将2007_test,改为2007_test_test。运行voc_label.py文件,darknet目录下会生成7个文件,分别为
2007_train.txt,2007_val.txt,2007_test_test.txt,2012_train.txt,2012_val.txt,train.txt,train.all.txt。
每一个txt文件中都存放着训练所需的文件的路径。除此之外,voc_label.py文件为每一副图片生成了一个存放label的txt文件。例如,在VOC2007/labels目录下,便存放着VOC2007数据集的label文件。label文件每一行的信息如下:
<object-class> <x> <y> <width> <height>
注意此处的x,y,w,h都是归一化后的。
下载预训练好的卷积权重:
wget https://pjreddie.com/media/files/darknet53.conv.74
修改cfg文件夹下的voc.data文件:

第二第三行改为自己的train.txt和2007_test.txt的路径
修改cfg文件夹下的yolo3-voc.cfg文件:
将文件开头的batch和subdivisions改成合适的值。
最后输入以下命令开始训练:
./darknet detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74