[深度学习论文笔记][Depth Estimation] Predicting Depth, Surface Normals and Semantic Labels with a Common M
Eigen, David, and Rob Fergus. “Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture.” Proceedings of the IEEE International Conference on Computer Vision. 2015.(Citations: 95).
Architecture
In a Nutshell See Fig. 3.5. Compared to Fig. 3.4, it offers several improvements.
• We make the model deeper.
• We add a third scale at higher resolution, bringing the final output resolution up to half the input.
• Instead of passing output predictions from scale1 to scale2, we pass multichannel feature maps.![[深度学习论文笔记][Depth Estimation] Predicting Depth, Surface Normals and Semantic Labels with a Common M_第1张图片](http://img.e-com-net.com/image/info8/2ba7ee19ad934394b7cb85ea2fbeb17f.jpg)
Scale1
• The output of the last full layer is reshaped to 1/16-scale, and then upsampled by a factor of 4 to 1/4-scale.
• Use fc to capture a very large field of view, which is especially important for depth and normal masks.
Scale2
• Train scale1 and scale2 jointly using SGD.
Scale3
• We concatenate the scale2 outputs with feature maps generated from the original input at yet finer stride, thus incorporating a more detailed view of the image.
• The final output resolution is half the network input.
Depth Loss
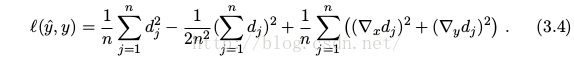
Where
![]()
The term (∇x d_j ) 2 + (∇y d_j ) 2 encourages predictions to have not only close-by values, but also similar local structure, which produces better ouputs.
Surface Normals We change the output from one channel to three, and predict the x, y and z components of the normal at each pixel. We also normalize the vector at each pixel to unit l 2 norm, and backpropagate through this normalization.
Loss
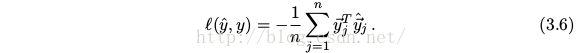
We sum over pixels, comparing the predicted normal at each pixel to the groundtruth by dot product.
Semantic Segmentation Suppose their are K classes, we change the output from one channel to K channels.
Loss is a pixelwise cross-entropy loss.
Training Details First, we jointly train both scale1 and scale2. Second, we fix the parameters of these scales and train scale3.