pytorch 实现SSD详细理解 (三)loss的定义和训练
摘要
在目标检测中loss的定义也是相当重要的一部分,SSD的loss定义是比较基础的,学习基础之后在去学restinanet的loss定义就轻松很多,定义loss是为了训练,让计算机知道自己的预测和真实标签的差距,通过不断的修改权重来达到loss值的缩小,就是预测准确度的提升。
SSD的loss定义
class MultiBoxLoss(nn.Module):
def __init__(self, num_classes, overlap_thresh, prior_for_matching,
bkg_label, neg_mining, neg_pos, neg_overlap, encode_target, use_gpu=True):
super(MultiBoxLoss, self).__init__()
self.use_gpu = use_gpu
self.num_classes= num_classes # 列表数
self.threshold = overlap_thresh # 交并比阈值, 0.5
self.background_label = bkg_label # 背景标签, 0
self.use_prior_for_matching = prior_for_matching
self.do_neg_mining = neg_mining
self.negpos_ratio = neg_pos # 负样本和正样本的比例, 3:1
self.neg_overlap = neg_overlap # 0.5 判定负样本的阈值.
self.encode_target = encode_target
self.variance = cfg["variance"]
def forward(self, predictions, targets):
loc_data, conf_data, priors = predictions
# loc_data: [batch_size, 8732, 4]
# conf_data: [batch_size, 8732, 21]
# priors: [8732, 4] default box 对于任意的图片, 都是相同的, 因此无需带有 batch 维度
num = loc_data.size(0) # num = batch_size
priors = priors[:loc_data.size(1), :] # loc_data.size(1) = 8732, 因此 priors 维持不变
num_priors = (priors.size(0)) # num_priors = 8732
num_classes = self.num_classes # num_classes = 21 (默认为voc数据集)
# 将priors(default boxes)和ground truth boxes匹配
loc_t = torch.Tensor(num, num_priors, 4) # shape:[batch_size, 8732, 4]
conf_t = torch.LongTensor(num, num_priors) # shape:[batch_size, 8732]
for idx in range(num):
# targets是列表, 列表的长度为batch_size, 列表中每个元素为一个 tensor,
# 其 shape 为 [num_objs, 5], 其中 num_objs 为当前图片中物体的数量, 第
#二维前4个元素为边框坐标, 最后一个元素为类别编号(1~20)
truths = targets[idx][:, :-1].data # [num_objs, 4]
labels = targets[idx][:, -1].data # [num_objs] 使用的是 -1, 而不是
# -1:, 因此, 返回的维度变少了
defaults = priors.data # [8732, 4]
# from ..box_utils import match
# 关键函数, 实现候选框与真实框之间的匹配, 注意是候选框而不是预测结果框!
# 这个函数实现较为复杂, 会在后面着重讲解
match(self.threshold, truths, defaults, self.variance, labels, loc_t, conf_t, idx)
if self.use_gpu:
loc_t = loc_t.cuda()
conf_t = conf_t.cuda()
# 用Variable封装loc_t, 新版本的 PyTorch 无需这么做, 只需要将
#requires_grad 属性设置为 True 就行了
loc_t = Variable(loc_t, requires_grad=False)
conf_t = Variable(conf_t, requires_grad=False)
pos = conf_t > 0 # 筛选出 >0 的box下标(大部分都是=0的)
num_pos = pos.sum(dim=1, keepdim=True) # 求和, 取得满足条件的box的数量,
#[batch_size, num_gt_threshold]
# 位置(localization)损失函数, 使用 Smooth L1 函数求损失
# loc_data:[batch, num_priors, 4]
# pos: [batch, num_priors]
# pos_idx: [batch, num_priors, 4], 复制下标成坐标格式, 以便获取坐标值
pos_idx = pos.unsqueeze(pos.dim()).expand_as(loc_data)
loc_p = loc_data[pos_idx].view(-1, 4)# 获取预测结果值
loc_t = loc_t[pos_idx].view(-1, 4) # 获取gt值
loss_l = F.smooth_l1_loss(loc_p, loc_t, size_average=False) # 计算损失
# 计算最大的置信度, 以进行难负样本挖掘
# conf_data: [batch, num_priors, num_classes]
# batch_conf: [batch, num_priors, num_classes]
batch_conf = conf_data.view(-1, self.num_classes) # reshape
# conf_t: [batch, num_priors]
# loss_c: [batch*num_priors, 1], 计算每个priorbox预测后的损失
loss_c = log_sum_exp(batch_conf) - batch_conf.gather(1, conf_t.view(-1,1))
# 难负样本挖掘, 按照loss进行排序, 取loss最大的负样本参与更新
loss_c[pos.view(-1, 1)] = 0 # 将所有的pos下标的box的loss置为0(pos指示的是
#正样本的下标)
# 将 loss_c 的shape 从 [batch*num_priors, 1] 转换成 [batch, num_priors]
loss_c = loss_c.view(num, -1) # reshape
# 进行降序排序, 并获取到排序的下标
_, loss_idx = loss_c.sort(1, descending=True)
# 将下标进行升序排序, 并获取到下标的下标
_, idx_rank = loss_idx.sort(1)
# num_pos: [batch, 1], 统计每个样本中的obj个数
num_pos = pos.long().sum(1, keepdim=True)
# 根据obj的个数, 确定负样本的个数(正样本的3倍)
num_neg = torch.clamp(self.negpos_ratio*num_pos, max=pos.size(1)-1)
# 获取到负样本的下标
neg = idx_rank < num_neg.expand_as(idx_rank)
# 计算包括正样本和负样本的置信度损失
# pos: [batch, num_priors]
# pos_idx: [batch, num_priors, num_classes]
pos_idx = pos.unsqueeze(2).expand_as(conf_data)
# neg: [batch, num_priors]
# neg_idx: [batch, num_priors, num_classes]
neg_idx = neg.unsqueeze(2).expand_as(conf_data)
# 按照pos_idx和neg_idx指示的下标筛选参与计算损失的预测数据
conf_p = conf_data[(pos_idx+neg_idx).gt(0)].view(-1, self.num_classes)
# 按照pos_idx和neg_idx筛选目标数据
targets_weighted = conf_t[(pos+neg).gt(0)]
# 计算二者的交叉熵
loss_c = F.cross_entropy(conf_p, targets_weighted, size_average=False)
# 将损失函数归一化后返回
N = num_pos.data.sum()
loss_l = loss_l / N
loss_c = loss_c / N
return loss_l, loss_c
这一步便写出了完整的loss定义,在来对应论文loss的定义,

坐标点的损失函数

交叉熵函数,分类的损失函数,
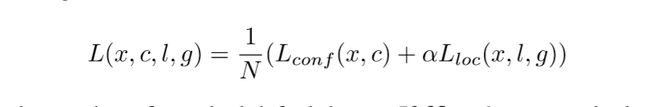 总的损失函数,有一点细节就是训练分类的时候加入了负样本,比例为1:3正负比,这样的好处是训练出来的检测器能够更好的区分背景和目标框。
总的损失函数,有一点细节就是训练分类的时候加入了负样本,比例为1:3正负比,这样的好处是训练出来的检测器能够更好的区分背景和目标框。
nn.CrossEntropyLoss
loss配合一个简单的操作应该理解更深刻一点,目前都是直接使用别人写好的loss函数使用,到后面需要自己去构造loss来符合赛事要求。
import torch.nn.functional as F
weight = torch.Tensor([1,2,1,1,2])
loss_fn = torch.nn.CrossEntropyLoss(reduce=True, size_average=False, weight=weight)
input = Variable(torch.randn(3, 5)) # (batch_size, C)
target = Variable(torch.LongTensor(3).random_(5))
loss = loss_fn(input, target)
print(input); print(target); print(loss)
交叉熵loss是多分类的损失函数,这里讲解一下reduce和size_average的使用
如果 reduce = False,那么 size_average 参数失效,直接返回向量形式的 loss;
如果 reduce = True,那么 loss 返回的是标量
如果 size_average = True,返回 loss.mean();
如果 size_average = False,返回 loss.sum();
面对一般情况数据集不平衡问题可以使用加入权重的操作来减少,不过效果最好的还是focal loss这个是restinanet核心要点,每个loss对输入和标签也不一样,细节点也有很多。
match代码
def intersect(box_a, box_b):
""" We resize both tensors to [A,B,2] without new malloc:
[A,2] -> [A,1,2] -> [A,B,2]
[B,2] -> [1,B,2] -> [A,B,2]
Then we compute the area of intersect between box_a and box_b.
Args:
box_a: (tensor) bounding boxes, Shape: [A,4].
box_b: (tensor) bounding boxes, Shape: [B,4].
Return:
(tensor) intersection area, Shape: [A,B].
""" #计算二个面积相交的部分,
A = box_a.size(0)
B = box_b.size(0)
max_xy = torch.min(box_a[:, 2:].unsqueeze(1).expand(A, B, 2),
box_b[:, 2:].unsqueeze(0).expand(A, B, 2))
min_xy = torch.max(box_a[:, :2].unsqueeze(1).expand(A, B, 2),
box_b[:, :2].unsqueeze(0).expand(A, B, 2))
inter = torch.clamp((max_xy - min_xy), min=0)
return inter[:, :, 0] * inter[:, :, 1]
def jaccard(box_a, box_b):
#计算iou的面积 A ∩ B / A ∪ B = A ∩ B / (area(A) + area(B) - A ∩ B)
inter = intersect(box_a, box_b)
area_a = ((box_a[:, 2]-box_a[:, 0]) *
(box_a[:, 3]-box_a[:, 1])).unsqueeze(1).expand_as(inter) # [A,B]
area_b = ((box_b[:, 2]-box_b[:, 0]) *
(box_b[:, 3]-box_b[:, 1])).unsqueeze(0).expand_as(inter) # [A,B]
union = area_a + area_b - inter
return inter / union # [A,B]
def match(threshold, truths, priors, variances, labels, loc_t, conf_t, idx):
overlaps = jaccard(truths, point_form(priors))#先转化形式成xyxy,在计算iou的面积
# 二部图匹配(Bipartite Matching)
# [num_objs,1], 得到对于每个 gt box 来说的匹配度最高的 prior box, 前者存储交并比, 后者存储prior box在num_priors中的位置
best_prior_overlap, best_prior_idx = overlaps.max(1, keepdim=True) # keepdim=True, 因此shape为[num_objs,1]
# [1, num_priors], 即[1,8732], 同理, 得到对于每个 prior box 来说的匹配度最高的 gt box
best_truth_overlap, best_truth_idx = overlaps.max(0, keepdim=True)
best_prior_idx.squeeze_(1) # 减少一个维度
best_prior_overlap.squeeze_(1)
best_truth_idx.squeeze_(0)
best_truth_overlap.squeeze_(0)
best_truth_overlap.index_fill_(0, best_prior_idx, 2)
# 该语句会将与gt box匹配度最好的prior box 的交并比置为 2, 确保其最大, 以免防止某些 gtbox 没有匹配的 priorbox.
# 因为 gt box 的数量要远远少于 prior box 的数量, 因此, 同一个 gt box 会与多个 prior box 匹配.
for j in range(best_prior_idx.size(0)): # range:0~num_obj-1
best_truth_idx[best_prior_idx[j]] = j
# best_prior_idx[j] 代表与box_a的第j个box交并比最高的 prior box 的下标, 将与该 gtbox
# 匹配度最好的 prior box 的下标改为j, 由此,完成了该 gtbox 与第j个 prior box 的匹配.
# 这里的循环只会进行num_obj次, 剩余的匹配为 best_truth_idx 中原本的值.
# 这里处理的情况是, priorbox中第i个box与gtbox中第k个box的交并比最高,
# 即 best_truth_idx[i]= k
# 但是对于best_prior_idx[k]来说, 它却与priorbox的第l个box有着最高的交并比,
# 即best_prior_idx[k]=l
# 而对于gtbox的另一个边框gtbox[j]来说, 它与priorbox[i]的交并比最大,
# 即但是对于best_prior_idx[j] = i.
# 那么, 此时, 我们就应该将best_truth_idx[i]= k 修改成 best_truth_idx[i]= j.
# 即令 priorbox[i] 与 gtbox[j]对应.
# 这样做的原因: 防止某个gtbox没有匹配的 prior box.
mathes = truths[best_truth_idx]
# truths 的shape 为[num_objs, 4], 而best_truth_idx是一个指示下标的列表, 列表长度为 8732,
# 列表中的下标范围为0~num_objs-1, 代表的是与每个priorbox匹配的gtbox的下标
# 上面的表达式会返回一个shape为 [num_priors, 4], 即 [8732, 4] 的tensor, 代表的就是与每个priorbox匹配的gtbox的坐标值.
conf = labels[best_truth_idx]+1 # 与上面的语句道理差不多, 这里得到的是每个prior box匹配的类别编号, shape 为[8732]
conf[best_truth_overlap < threshold] = 0 # 将与gtbox的交并比小于阈值的置为0 , 即认为是非物体框
loc = encode(matches, priors, variances) # 返回编码后的中心坐标和宽高.
loc_t[idx] = loc # 设置第idx张图片的gt编码坐标信息
conf_t[idx] = conf # 设置第idx张图片的编号信息.(大于0即为物体编号, 认为有物体, 小于0认为是背景)
这一步主要还是去除大多数重复的框和不满足阙值得框,然后又要确保每一个真实框都有最大iou比的预测框来对应,
训练代码
from data import *
from utils.augmentations import SSDAugmentation
from layers.modules import MultiBoxLoss
from ssd import build_ssd
import os
import sys
import time
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.optim as optim
import torch.backends.cudnn as cudnn
import torch.nn.init as init
import torch.utils.data as data
import numpy as np
import argparse
def str2bool(v):
return v.lower() in ("yes", "true", "t", "1")
#引进parser的好处就是linux系统方便操作,不需要在里面修改数据集信息,在外面通过语句就行,window系统要进入代码里修改信息
parser = argparse.ArgumentParser(
description='Single Shot MultiBox Detector Training With Pytorch')
train_set = parser.add_mutually_exclusive_group()
parser.add_argument('--dataset', default='VOC', choices=['VOC', 'COCO'],
type=str, help='VOC or COCO')
parser.add_argument('--dataset_root', default=VOC_ROOT,
help='Dataset root directory path')
parser.add_argument('--basenet', default='vgg16_reducedfc.pth',
help='Pretrained base model')
parser.add_argument('--batch_size', default=32, type=int,
help='Batch size for training')
parser.add_argument('--resume', default=None, type=str,
help='Checkpoint state_dict file to resume training from')
parser.add_argument('--start_iter', default=0, type=int,
help='Resume training at this iter')
parser.add_argument('--num_workers', default=4, type=int,
help='Number of workers used in dataloading')
parser.add_argument('--cuda', default=True, type=str2bool,
help='Use CUDA to train model')
parser.add_argument('--lr', '--learning-rate', default=1e-3, type=float,
help='initial learning rate')
parser.add_argument('--momentum', default=0.9, type=float,
help='Momentum value for optim')
parser.add_argument('--weight_decay', default=5e-4, type=float,
help='Weight decay for SGD')
parser.add_argument('--gamma', default=0.1, type=float,
help='Gamma update for SGD')
parser.add_argument('--visdom', default=False, type=str2bool,
help='Use visdom for loss visualization')
parser.add_argument('--save_folder', default='weights/',
help='Directory for saving checkpoint models')
args = parser.parse_args()
if torch.cuda.is_available():
if args.cuda:
torch.set_default_tensor_type('torch.cuda.FloatTensor')
if not args.cuda:
print("WARNING: It looks like you have a CUDA device, but aren't " +
"using CUDA.\nRun with --cuda for optimal training speed.")
torch.set_default_tensor_type('torch.FloatTensor')
else:
torch.set_default_tensor_type('torch.FloatTensor')
if not os.path.exists(args.save_folder):
os.mkdir(args.save_folder)
def train():
if args.dataset == 'COCO':
if args.dataset_root == VOC_ROOT:
if not os.path.exists(COCO_ROOT):
parser.error('Must specify dataset_root if specifying dataset')
print("WARNING: Using default COCO dataset_root because " +
"--dataset_root was not specified.")
args.dataset_root = COCO_ROOT
cfg = coco
dataset = COCODetection(root=args.dataset_root,
transform=SSDAugmentation(cfg['min_dim'],
MEANS))
elif args.dataset == 'VOC':
if args.dataset_root == COCO_ROOT:
parser.error('Must specify dataset if specifying dataset_root')
cfg = voc
dataset = VOCDetection(root=args.dataset_root,
transform=SSDAugmentation(cfg['min_dim'],
MEANS))
if args.visdom:
import visdom
viz = visdom.Visdom()
ssd_net = build_ssd('train', cfg['min_dim'], cfg['num_classes'])
net = ssd_net
if args.cuda:
net = torch.nn.DataParallel(ssd_net)
cudnn.benchmark = True
if args.resume:
print('Resuming training, loading {}...'.format(args.resume))
ssd_net.load_weights(args.resume)
else:
vgg_weights = torch.load(args.save_folder + args.basenet)
print('Loading base network...')
ssd_net.vgg.load_state_dict(vgg_weights)
if args.cuda:
net = net.cuda()
if not args.resume:
print('Initializing weights...')
# initialize newly added layers' weights with xavier method
ssd_net.extras.apply(weights_init)
ssd_net.loc.apply(weights_init)
ssd_net.conf.apply(weights_init)
optimizer = optim.SGD(net.parameters(), lr=args.lr, momentum=args.momentum,
weight_decay=args.weight_decay)
criterion = MultiBoxLoss(cfg['num_classes'], 0.5, True, 0, True, 3, 0.5,
False, args.cuda)
net.train()
# loss counters
loc_loss = 0
conf_loss = 0
epoch = 0
print('Loading the dataset...')
epoch_size = len(dataset) // args.batch_size
print('Training SSD on:', dataset.name)
print('Using the specified args:')
print(args)
step_index = 0
if args.visdom:
vis_title = 'SSD.PyTorch on ' + dataset.name
vis_legend = ['Loc Loss', 'Conf Loss', 'Total Loss']
iter_plot = create_vis_plot('Iteration', 'Loss', vis_title, vis_legend)
epoch_plot = create_vis_plot('Epoch', 'Loss', vis_title, vis_legend)
data_loader = data.DataLoader(dataset, args.batch_size,
num_workers=args.num_workers,
shuffle=True, collate_fn=detection_collate,
pin_memory=True)
# create batch iterator
batch_iterator = iter(data_loader)
for iteration in range(args.start_iter, cfg['max_iter']):
if args.visdom and iteration != 0 and (iteration % epoch_size == 0):
update_vis_plot(epoch, loc_loss, conf_loss, epoch_plot, None,
'append', epoch_size)
# reset epoch loss counters
loc_loss = 0
conf_loss = 0
epoch += 1
if iteration in cfg['lr_steps']:
step_index += 1
adjust_learning_rate(optimizer, args.gamma, step_index)
# load train data
images, targets = next(batch_iterator)
if args.cuda:
images = Variable(images.cuda())
targets = [Variable(ann.cuda(), volatile=True) for ann in targets]
else:
images = Variable(images)
targets = [Variable(ann, volatile=True) for ann in targets]
# forward
t0 = time.time()
out = net(images)
# backprop
optimizer.zero_grad()
loss_l, loss_c = criterion(out, targets)
loss = loss_l + loss_c
loss.backward()
optimizer.step()
t1 = time.time()
loc_loss += loss_l.data[0]
conf_loss += loss_c.data[0]
if iteration % 10 == 0:
print('timer: %.4f sec.' % (t1 - t0))
print('iter ' + repr(iteration) + ' || Loss: %.4f ||' % (loss.data[0]), end=' ')
if args.visdom:
update_vis_plot(iteration, loss_l.data[0], loss_c.data[0],
iter_plot, epoch_plot, 'append')
if iteration != 0 and iteration % 5000 == 0:
print('Saving state, iter:', iteration)
torch.save(ssd_net.state_dict(), 'weights/ssd300_COCO_' +
repr(iteration) + '.pth')
torch.save(ssd_net.state_dict(),
args.save_folder + '' + args.dataset + '.pth')
def adjust_learning_rate(optimizer, gamma, step):
"""Sets the learning rate to the initial LR decayed by 10 at every
specified step
# Adapted from PyTorch Imagenet example:
# https://github.com/pytorch/examples/blob/master/imagenet/main.py
"""
lr = args.lr * (gamma ** (step))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
def xavier(param):
init.xavier_uniform(param)
def weights_init(m):
if isinstance(m, nn.Conv2d):
xavier(m.weight.data)
m.bias.data.zero_()
def create_vis_plot(_xlabel, _ylabel, _title, _legend):
return viz.line(
X=torch.zeros((1,)).cpu(),
Y=torch.zeros((1, 3)).cpu(),
opts=dict(
xlabel=_xlabel,
ylabel=_ylabel,
title=_title,
legend=_legend
)
)
def update_vis_plot(iteration, loc, conf, window1, window2, update_type,
epoch_size=1):
viz.line(
X=torch.ones((1, 3)).cpu() * iteration,
Y=torch.Tensor([loc, conf, loc + conf]).unsqueeze(0).cpu() / epoch_size,
win=window1,
update=update_type
)
# initialize epoch plot on first iteration
if iteration == 0:
viz.line(
X=torch.zeros((1, 3)).cpu(),
Y=torch.Tensor([loc, conf, loc + conf]).unsqueeze(0).cpu(),
win=window2,
update=True
)
if __name__ == '__main__':
train()
测试代码
from __future__ import print_function
import sys
import os
import argparse
import torch
import torch.nn as nn
import torch.backends.cudnn as cudnn
import torchvision.transforms as transforms
from torch.autograd import Variable
from data import VOC_ROOT, VOC_CLASSES as labelmap
from PIL import Image
from data import VOCAnnotationTransform, VOCDetection, BaseTransform, VOC_CLASSES
import torch.utils.data as data
from ssd import build_ssd
parser = argparse.ArgumentParser(description='Single Shot MultiBox Detection')
parser.add_argument('--trained_model', default='weights/ssd_300_VOC0712.pth',
type=str, help='Trained state_dict file path to open')
parser.add_argument('--save_folder', default='eval/', type=str,
help='Dir to save results')
parser.add_argument('--visual_threshold', default=0.6, type=float,
help='Final confidence threshold')
parser.add_argument('--cuda', default=True, type=bool,
help='Use cuda to train model')
parser.add_argument('--voc_root', default=VOC_ROOT, help='Location of VOC root directory')
parser.add_argument('-f', default=None, type=str, help="Dummy arg so we can load in Jupyter Notebooks")
args = parser.parse_args()
if args.cuda and torch.cuda.is_available():
torch.set_default_tensor_type('torch.cuda.FloatTensor')
else:
torch.set_default_tensor_type('torch.FloatTensor')
if not os.path.exists(args.save_folder):
os.mkdir(args.save_folder)
def test_net(save_folder, net, cuda, testset, transform, thresh):
# dump predictions and assoc. ground truth to text file for now
filename = save_folder+'test1.txt'
num_images = len(testset)
for i in range(num_images):
print('Testing image {:d}/{:d}....'.format(i+1, num_images))
img = testset.pull_image(i)
img_id, annotation = testset.pull_anno(i)
x = torch.from_numpy(transform(img)[0]).permute(2, 0, 1)
x = Variable(x.unsqueeze(0))
with open(filename, mode='a') as f:
f.write('\nGROUND TRUTH FOR: '+img_id+'\n')
for box in annotation:
f.write('label: '+' || '.join(str(b) for b in box)+'\n')
if cuda:
x = x.cuda()
y = net(x) # forward pass
detections = y.data
# scale each detection back up to the image
scale = torch.Tensor([img.shape[1], img.shape[0],
img.shape[1], img.shape[0]])
pred_num = 0
for i in range(detections.size(1)):
j = 0
while detections[0, i, j, 0] >= 0.6:
if pred_num == 0:
with open(filename, mode='a') as f:
f.write('PREDICTIONS: '+'\n')
score = detections[0, i, j, 0]
label_name = labelmap[i-1]
pt = (detections[0, i, j, 1:]*scale).cpu().numpy()
coords = (pt[0], pt[1], pt[2], pt[3])
pred_num += 1
with open(filename, mode='a') as f:
f.write(str(pred_num)+' label: '+label_name+' score: ' +
str(score) + ' '+' || '.join(str(c) for c in coords) + '\n')
j += 1
def test_voc():
# load net
num_classes = len(VOC_CLASSES) + 1 # +1 background
net = build_ssd('test', 300, num_classes) # initialize SSD
net.load_state_dict(torch.load(args.trained_model))
net.eval()
print('Finished loading model!')
# load data
testset = VOCDetection(args.voc_root, [('2007', 'test')], None, VOCAnnotationTransform())
if args.cuda:
net = net.cuda()
cudnn.benchmark = True
# evaluation
test_net(args.save_folder, net, args.cuda, testset,
BaseTransform(net.size, (104, 117, 123)),
thresh=args.visual_threshold)
if __name__ == '__main__':
test_voc()
训练和测试代码这里就不多说了,这种代码风格比较老套,当时还没有tensorboardx可视化,所以代码学习性不是很好。掌握SSD的核心内容就够了,这里我没有下载SSD的权重,检测的使用在demo/demo.ipynb打开这个就可以使用预训练好的权重进行操作,这个SSD没有训练的必要,效果不如yolo3,下一部分就要开始学习restinanet,重点的学习是focal loss的定义,专门用于处理数据集不平衡问题。