第三章第二节 模型参数的访问、初始化和共享
在“线性回归的简洁实现”一节中,我们通过init模块来初始化模型的全部参数。我们也介绍了访问模型参数的简单方法。本节将深入讲解如何访问和初始化模型参数,以及如何在多个层之间共享一份模型参数。
我们先定义一个与上一节中相同的含单隐藏层的多层感知机。我们依然使用默认方式初始化它的参数,并做一次前向计算。与之前不同的是,在这里我们从MXNet中导入了init模块,它包含了多种模型初始化方法。

3.2.1 访问模型参数
对于使用Sequential类构造的神经网络,我们可以通过方括号[]来访问网络中的任一层。会议以下上一节中提到的Sequential类与Block类的继承关系。对于Sequential实例中含模型参数的层,我们可以通过Block类的params属性来访问该层包含的所有参数。下面,访问访问多层感知机net中隐藏层的所有参数。索引0表示隐藏层为Sequential实例最先添加的层。

可以看到,我们得到了一个由参数名称映射到参数实例的字典(类型为ParameterDict类)。其中权重参数的名称为dense0_weight,它由net[0]的名称(dense0_)和自己的变量名(weight)组成。而且可以看到,该参数的形状为(256,20),且数据类型为32位浮点数(float32)。为了访问特定参数,我么既可以通过名字来访问字典里的元素,也可以直接使用它的变量名。下面两种方法是等价的,但通常后者的代码可读性更好。

Gluon里参数类型为Parameter类,它包含参数和梯度的数值,可以分别通过data函数和grad函数来访问。因为我们我们随机初始化了权重,所以权重参数是一个由随机数组成的形状为(256,220)的NDArray。
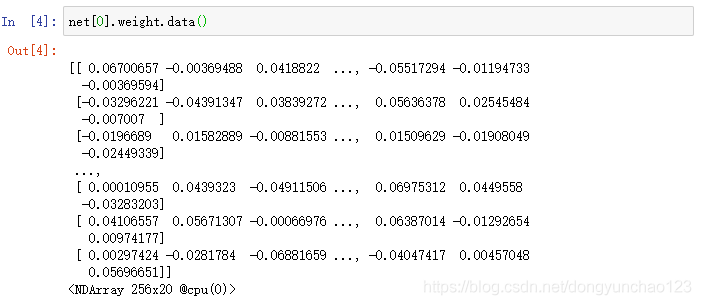
权重梯度的形状和权重的形状一样。因为我们还没有进行反向传播计算,所以梯度的值全为0。
类似地,我么可以访问其它层的参数,如输出层的偏差值。

最后,我么可以使用collect_params函数来获取net变量所有嵌套(例如通过add函数嵌套)的层所包含的所有参数。它返回的同样是一个由参数名称到参数实例的字典。
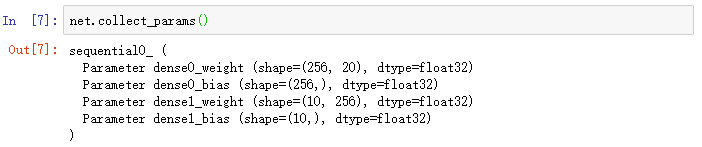
这个函数可以通过正则表达式来匹配参数名,从而筛选需要的参数。

3.2.2 初始化模型参数
我们在“数值稳定性和模型初始化”一节中描述了模型的默认初始化方法:权重参数元素为[-0.07,0.07]之间均匀分布的随机数,偏差参数则全为0.但我们经常需要使用其他方法来初始化权重。MXNet的init模块里提供了多种预设的初始化方法。在下面的例子中,我们将权重参数初始化成均值为0、标准差为0.01的正太分布随机数,并依然将偏差参数清零。

下面使用常数来初始化权重参数

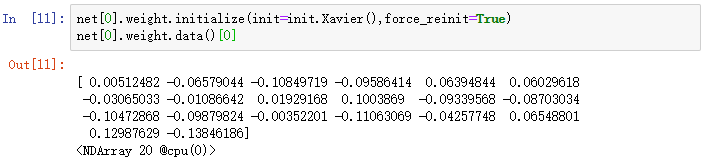
如果只想对某个特定参数进行初始化,我们可以调用Parameter类的initialize函数,它与Block类提供的initialize函数使用方法一致。下例中我们对隐藏层的权重使用Xavier随机初始化方法。
3.2.3 自定义初始化方法
有时候我们需要的初始化方法并没有在init模块中提供。这时,可以实现一个Initializer类的子类,从而能够像使用其他初始化方法那样使用它。通常,我们只需要实现_init_weight这个函数,并将其传入的NDArray修改成初始化的结果。在下面的例子里,我们令权重有一半概率初始化为0,有另一半概率初始化为[-10,-5]和[5,10]两个区间里均匀分布的随机数。
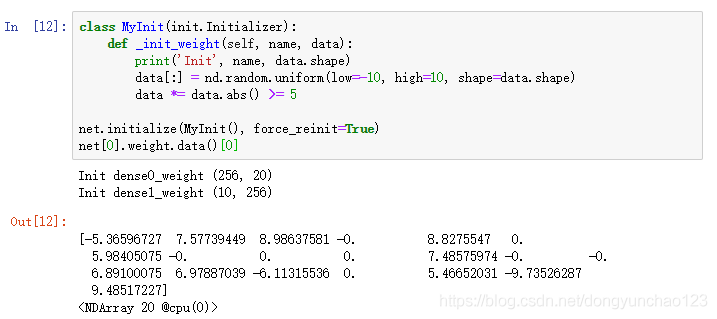
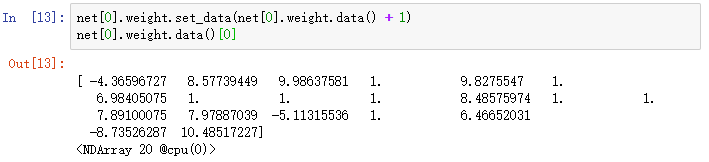
此外,我们还可以通过Parameter类的set_data函数来直接改写模型参数。例如,在下例中我们将隐藏层参数在现有基础上加1。
3.2.4 共享模型参数
在有些情况下,我们希望在多个层之间共享模型参数。“模型构造”一节介绍了如何在Block类的forward函数里多次调用同一个层来计算。这里再介绍另外一种方法,它在构造层的时候指定使用特定的参数。如果不同层使用同一份参数,那么它们在前向计算和反向传播时都会共享模型参数。在下面的例子里,我们让模型的第二隐藏层(shared变量)和第三隐藏层共享模型参数。

我们在构造第三隐藏层时通过params来指定它使用第二隐藏层的参数。因为模型参数里包含了梯度,所以在反向传播计算时,第二隐藏层和第三隐藏层的梯度都会被累加在shared.params.grad()里。