独家 | 3步将深度学习应用到你的商业中

原文标题:Here's how you can leverge Deep Learning in your bussiness
翻译:申利彬
校对:白静
作者:George Seif
本文约2000字,建议阅读5分钟。
本文带大家三步了解深度学习在商业中的应用方法。

深度学习是大家谈论的热门话题,利用深度学习不仅解决了很多现实难题,还让很多新的创新成为可能。强有力的盈利商业模式正是以给人们解决问题、为客户带来价值为基础的。
深度学习在很多任务上表现的很好,例如,语音识别、图像分类、聊天机器人,等等。但是,我们该怎样使用这种技术?如何把它应用在自己的商业中呢?下面我会指导你如何做到,并用流程图直观表达这个过程。
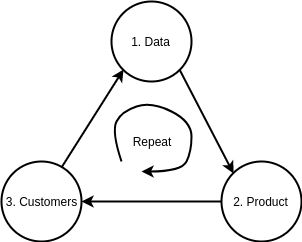
第一步:获取数据
深度学习融入商业的第一步是获取极其重要的数据。深度学习发挥作用,能够很好解决有价值的问题,主要归功于数据。最好的深度学习模型是基于监督学习,也就是说,这些模型达到很好的性能需要大量标记数据。简而言之,我们需要给深度学习“机器”很多“燃料”,它才能很好的工作,这种“燃料”就是数据。
告诉你一个好消息,大多数情况下数据都是现成的。有很多公开可用的标记数据集,这些数据集被收集起来用于训练深度学习模型,再应用到普通的应用程序。有很多关于图像分类、语言翻译、聊天机器人、自动驾驶的数据,可以用在应用程序上。
这是深度学习数据集的快速学习资源:
http://bit.do/Deep-Learning-Datasets(资料很全,值得收藏)
假如你遇到不常见的情形,有个特定的应用,很具体,但是没有公开的大数据集,该怎么办呢?我们可以制作自己的数据集,数据收集不再像以前那么具有挑战性。在这种情况下,网络爬虫工具可以发挥绝佳作用。Adrian Rosebrock有一个很好的教程,关于如何自动爬取Google图片并建立自己的数据集。
http://bit.do/Scrape-Your-Dataset. (教程地址)
可以用群智工具标记大量数据,例如,亚马逊的Mechanical Turk,它的目标是获取足够的数据,建立一个极简可用的产品 (MVP)。
你肯定好奇,到底需要多少数据。这儿有一个不错的方法可以做出估计:找一个相似的任务,看看别人处理问题用了多少数据。除此之外,通常情况下数据越多越好,只要你不是得到负反馈。
第二步:开发深度学习产品
有了标记数据,可以全力开发产品。使用之前的数据训练深度学习模型,并用该模型完成特定任务,最终给客户带来价值。深度学习最擅长处理那些重复的任务,这些任务呈现出多种多样的模式。因此需要关注在必要知识和执行方面重复率都很高的自动化任务,通常情况下这些任务还需要大量人类努力或特定技能。这样,你把提供给客户的价值最大化,如果客户不使用你的深度学习产品,那就不能享受到这些价值。
第三步:客户驱动的正反馈循环
在这个阶段,通过几个关键步骤把深度学习应用在商业中。你已经收集了数据并用它来训练一个深度学习模型,然后用这个模型助力产品,产品性能表现很好并给客户带来价值。现在是最重要的部分,正反馈循环。
开始把产品交付客户使用,有的客户喜欢用,也有的不喜欢,但这都是一个学习过程。非常重要的是,一个新的客户也就是一个新的数据来源,它可以进一步提高深度学习模型的准确率,进而优化产品。所以,关键是有效率的获取新数据。
第一次开发一个极简可用的产品(MVP)时,你可能会为你的定制产品使用公开的数据集或自己爬取数据集,不管是哪种情况,你的数据都足够训练一个好的模型并开发出MVP。但如果想优化产品,数据可能是不够的。比如,你使用了公开的数据集,这些数据可能不包含特殊场景。你可能在家里安装了人脸识别系统,系统识别出人脸时才会把门打开。如果你使用的数据集只有清晰的人脸图片,那系统可能会在雨天或者晚上失效,顾客也就会被锁在门外。另一种情况是你自己爬取数据集,你的目标是获得足够数据,开发出一款极简可用产品(MVP)。这两种情况都表明:更多的数据有可能优化你的模型。也有研究证明,更多的数据有助于改进深度学习模型:
https://arxiv.org/abs/1707.02968v2(论文地址)
既然你的产品掌握在付费客户手中,那么他们就是你获取新数据的最佳资源。客户会定期使用产品,这样就可以获得更多的数据。还记得那个在雨中人脸识别失败的例子吗?为什么不把这些失败的数据加入训练集,帮助训练提高深度学习模型的精度!可以收集那些在雨中和夜晚失败的数据,并标记它们,用这些新数据优化模型。每当系统出错,就有得到新数据的机会,标记这些新数据,重新训练模型,可以实现从错误中学习。当然。也可以在成功的数据中运用这些方法,收集数据并使模型在那些情况下的表现更加稳定。
整个流程创造了正反馈循环,顾客就是驱动循环的人。数据越多,产品越好。产品越好,客户越多,客户创造更多有价值的数据助力深度学习产品。
结束语
现在了解了整个流程,可以开发一个产品,既能实现自我防御,还能由连续循环的数据和深度学习驱动,给客户带来巨大的价值。
原文地址:https://towardsdatascience.com/heres-how-to-leverage-deep-learning-in-your-startup-9204666a3272

申利彬,研究生在读,主要研究方向大数据机器学习。目前在学习深度学习在NLP上的应用,希望在THU数据派平台与爱好大数据的朋友一起学习进步。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:datapi),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。


点击“阅读原文”加入组织~