3.2 详解优化器的选择
文章目录
- 1. 什么是优化器
- 2. 梯度下降算法
- 3. 基于动量的梯度下降
- 4. 实用优化器的选择
- 4.1 Adagrad优化器
- 4.2 Rmsprop
- 4.3 AdaDelta优化器
- 4.4 Adam优化器
- 5. 总结
本章大量内容来自:《深度学习轻松学:核心算法与视觉实践》 一书的第八章,非常感谢作者。
1. 什么是优化器
要型对各种优化的选择游刃有余,得先理解什么是优化器。
深度学习的目标是通过不断改变网络参数,使得参数能够对输入做各种非线性变换拟合输出,本质上就是一个函数去寻找最优解,所以如何去更新参数是深度学习研究的重点。通常将更新参数的算法称为优化器,字面理解就是通过什么算法去优化网络模型的参数。常用的优化器就是梯度下降。
2. 梯度下降算法
梯度下降算法特别容易理解,函数的梯度方向表示了函数值增长速度最快的方向,那么和它相反的方向就可以看作是函数值减少速度最快的方向。对机器学习模型优化的问题,当目标设定为求解目标函数最小值时,只要朝着梯度下降的方向前进,就能不断逼近最优值。
先来实现一个梯度下降的算法:
def gd(x_start , step, g) : #gd代表了Gradient Descent
x = x_start
for i in range(20) :
grad = g(x)
x - = grad * step
print('epoch:%d, grad=%f, x ='%(i,grad), x)
if abs (grad) < le-6 :
break ;
return x
根据用多少样本量来更新参数将梯度下降分为三类:BGD,SGD,MBGD
(1)BGD:Batch gradient descent
每次使用整个数据集计算损失后来更新参数,很显然计算会很慢,占用内存大且不能实时更新,优点是能够收敛到全局最小点,对于异常数据不敏感。
(2)SGD:Stochastic gradient descent
这就是常说的随机梯度下降,每次更新度随机采用一个样本计算损失来更新参数,计算比较快,占用内存小,可以随时新增样本。这种方式对于样本中的异常数据敏感,损失函数容易震荡。容易收敛到局部极小值,但由于震荡严重,会跳出局部极小,从而寻找到接近全局最优的解。
(3)MBGD: Mini-batch gradient descent
最小批梯度更新,很好理解,将BGD和SGD结合在一起,每次从数据集合中选取一小批数据来计算损失并更新网络参数。
tensorflow中对应的函数是:
train_step = tf.train.GradientDescentOptimizer(learning_rate=lr).minimize(loss)
3. 基于动量的梯度下降
动量是,在优化求解的过程中,动量代表了之前迭代优化量,它将在后面的优化过程中持续发戚,推动目标值前进。拥有了动量, 一个已经结束的更新量不会立刻消失,只会以一定的形式衰减,剩下的能量将继续在优化中发挥作用。它反映的是梯度持续影响能能力。
首先看一下基于动量的梯度下降的代码:

绿框中pre_grad代表之前所有梯度之和,grad是当前梯度。红框中表明对之前梯度只和进行了一个discount的衰减,和step(或者说是学习率的作用是一样的)
它的功效主要表现在优化函数的梯度下降最快的方向不一定是接近函数最小值的方向,有个经典的例子: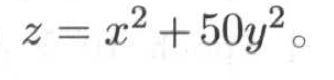
y方向的梯度一直占据主要优势,函数的等高线图为:
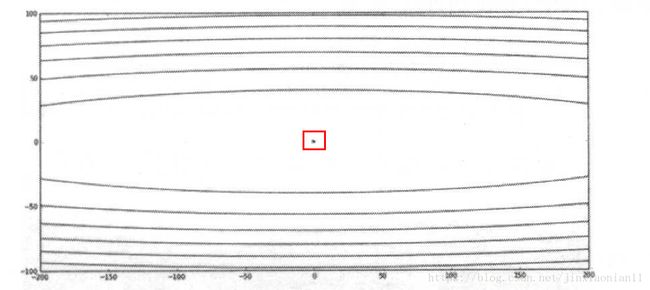
其中中心的点表示了最优值。把等高线上的图像想象成地形图,从等高线的疏密程度可以看出,这个函数在u 轴方向十分陡峭,在z 轴方向则相对平缓。也就是说,函数在u 轴的方向导数比较大,在z 轴的方向导数比较小。在使用2中的梯度下降的时候,肯定会在y方向上不断的跳跃。例如:

这样的优化效果很不明显,这是由于在优化的过程中,朝向正确优化方向前进的步伐比较小,而无效的重复步伐比较多,优化的效率就很低。
如果在梯度下降中加入动量,这样y方向带来的震荡的梯度就会抵消,而x方向的梯度持续增强(因为x方向没有震荡),优化速度就会越来越快。效果如下:

但是优化效果还不是想的那么好,研究人员提出了Nesterov算法:
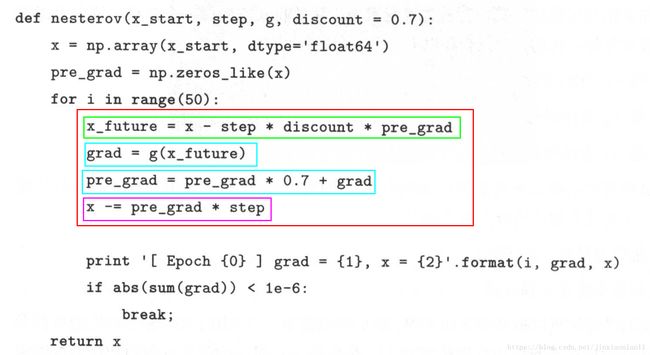
这个就有意思了,当前点的优化不仅依赖当前点和以前点的梯度信息,还利用了下一个点的梯度信息。通过以下一个点的位置来确定当前点对优化无用的梯度信息并减去它,从未增加优化速度。优化效果:

tensorflow中对应的函数是:
train_step = tf.train.MomentumOptimizer(learning_rate=lr).minimize(loss)
在实际应用中很少用前面两个,因为有各种变种,效果会更好。
4. 实用优化器的选择
4.1 Adagrad优化器
它的核心思想是对于常见的数据给予比较小的学习率去调整参数,对于不常见的数据给予比较大的学习率调整参数。它可以自动调节学习率,但迭代次数多的时候,学习率也会下降。
代码为:

tensorflow中的函数为:
train_step = tf.train.AdagradOptimizer(learning_rate=lr).minimize(loss)
4.2 Rmsprop
前面的Adagrad 算法有一个很大的问题,那就是随着优化的迭代次数不断增加,更新公式的分母项会变得越来越大。所以理论上更新量也会越来越小,这对优化十分不利。下面的算法Rmsprop就试图解决这个问题。在它的算法中, 分母的梯度平方和不再随优化而递增,而是做加权平均。
代码为:

tensorflow中函数为:
train_step = tf.train.RMSPropOptimizer(learning_rate=lr).minimize(loss)
在优化表现上和Adagrad差不多,但是它的学习率比Ada grad 要小很多,而更新的速度也比A dagrad 快。
4.3 AdaDelta优化器
在之前的一些优化算法中,更新量都是由学习率乘以梯度向量组成,而Ada grad 方法在更新量计算的公式中除以了梯度累积量,这相当于打破了之前的更新量组成部分的平衡性,因此算法的作者认为如果分母加上了梯度累积量,那么分子也应该加上一些内容,这样的更新量才会和之前的算法一样保持平衡。更新量的“单位”才能恢复
正常。
代码为:


tensorflow中的函数为:
train_step = tf.train.AdadeltaOptimizer(learning_rate=lr).minimize(loss)
4.4 Adam优化器
Adam优化器即包含了动量算法的思想,也包含了Rm sProp 的自适应梯度的思想。
代码示意:

tensorflow中的函数为:train_step = tf.train.AdamOptimizer(learning_rate=lr).minimize(loss)
以上几种优化器对应的数学公式可以在原文中找找看看,能加深理解。在实际使用中,优化器的不同可能直接导致结果的不一样。我一般优先选择最后Adam,再选择其他优化器。RmsProp优化器的表现也十分的稳定。
5. 总结
在实际的使用过程中,一般会选择Adam和RmsProp两个优化器。另外,选用什么样的算法很大程度上取决于自己的损失函数,所以需要对自己的网络结构和损失函数的特点有一些了解。