强劲的Linux Trace工具:bpftrace (DTrace 2.0) for Linux 2018
译者: 姜弋
译者注:原作者是大名鼎鼎的性能分析专家:Brendan Gregg,现在工作在Netflix,之前工作在Sun,在Sun公司的时候,他就做了大量的性能分析和tracing相关的工作,在Sun的Solaris上存在一种传说中的性能分析和Debug神器: Dtrace,然而,可惜的是,在我们现在的Linux操作系统上并没有Dtrace神器(这可能是因为Dtrace是从Soloris操作系统的衍生品无法迁移到别的操作系统上),Brendan Gregg 在Netflix后,继续利用他的业余时间,利用他曾经在Soloris上的性能分析经验,和对Dtrace工具的理解,研发基于Linux操作系统上的上类似于Dtrace的工具,曾经他在早期的kernel版本上基于perf研发了perf-tools工具,后面在eBPF进入kernel后,开始基于eBPF做性能工具研发的工作,比如bcc工具集,最近又参与了bpftrace的工具。本文主要是Brendan Gregg在介绍 bpftrace在2018年的开发进展,以及对bpftrace的介绍和对Dtrace的区别介绍。
bpftrace (DTrace 2.0) for Linux 2018
告诉大家一个好消息,bpftrace开源啦,这对DTrace粉丝来说是一个绝对的好消息,其项目作者依然是Alastair Robertson, bpftrace是一个开源的高级的tracing(跟踪)工具(high-level tracing front-end),可以让你自定义的方式跟踪。它就像是DTrace version 2.0:实用,从eBPF virtual machine中编译出来。eBPF (extended Berkeley Packet Filter) 是近期kernel上比较热门的一个工程。也正在为兼容BSD而开发,BSD项目也是BPF项目的发源地。
截图:追踪PID 181的read系统调用的延迟:
其他单行命令操作(one-liners):
1# New processes with arguments
2bpftrace -e 'tracepoint:syscalls:sys_enter_execve { join(args->argv); }'
3
4# Files opened by process
5bpftrace -e 'tracepoint:syscalls:sys_enter_open { printf("%s %s\n", comm, str(args->filename)); }'
6
7# Syscall count by program
8bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] = count(); }'
9
10# Syscall count by syscall
11bpftrace -e 'tracepoint:syscalls:sys_enter_* { @[probe] = count(); }'
12
13# Syscall count by process
14bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[pid, comm] = count(); }'
15
16# Read bytes by process:
17bpftrace -e 'tracepoint:syscalls:sys_exit_read /args->ret/ { @[comm] = sum(args->ret); }'
18
19# Read size distribution by process:
20bpftrace -e 'tracepoint:syscalls:sys_exit_read { @[comm] = hist(args->ret); }'
21
22# Disk size by process
23bpftrace -e 'tracepoint:block:block_rq_issue { printf("%d %s %d\n", pid, comm, args->bytes); }'
24
25# Pages paged in by process
26bpftrace -e 'software:major-faults:1 { @[comm] = count(); }'
27
28# Page faults by process
29bpftrace -e 'software:faults:1 { @[comm] = count(); }'
30
31# Profile user-level stacks at 99 Hertz, for PID 189:
32bpftrace -e 'profile:hz:99 /pid == 189/ { @[ustack] = count(); }'
怎么样?看起来很眼熟吧?没错,灵感就是从Solaris上的Dtrace工具而来(传承Dtrace的一行搞定(专业术词:one-liners)的精神),bpftrace将会继续沿袭Dtrace的思想,在后面的milestone中。
bpftrace
我第一次提及 bpftrace (aka BPFtrace)工作计划,是在曾经的一次演讲上:DTrace for Linux 2016, 当时,我也介绍了Linux Kernel的eBPF的孵化过程,同时也介绍了我当时在做的bcc (BPF Complier Collection)项目,一个让我在新的架构上重写Dtrace工具集的项目。bcc虽然很强大,但是要实现一个小工具就需要写一个小脚本,还是有点小麻烦(写一个小脚本要写的代码太多,不能用一行命令表达),因此,我准备额外分享另外一个高级工具bpftrace给大家。bpftrace特点在于,当希望编写小工具的时候,可以一行命令表达完整。
Alastair最近在开发一些框架,并且适配了tracepoints(可以做到one-linner),昨天把kprobes也适配好了,举个例子:
1# cat path.bt
2#include path.h>
3#include
4
5kprobe:vfs_open
6{
7 printf("open path: %s\n", str(((path *)arg0)->dentry->d_name.name));
8}
9
10# bpftrace path.bt
11Attaching 1 probe...
12open path: dev
13open path: if_inet6
14open path: retrans_time_ms
我,Willian Gaspar, 和 Matheus Marchini,也提供了一些拓展和bugfix的patch,查看没有处理的问题issue list,查看指南, 查看之前的提交。
bpftrace使用了已有的Linux kernel中的基础设施(eBPF, kprobes, uprobes, tracepoints, perf_events),同时也有bcc的库,至于bpftrace内部实现,使用了 lex/yacc parser 把程序转化为AST,再到 llvm IR actions, 最后变成BPF。
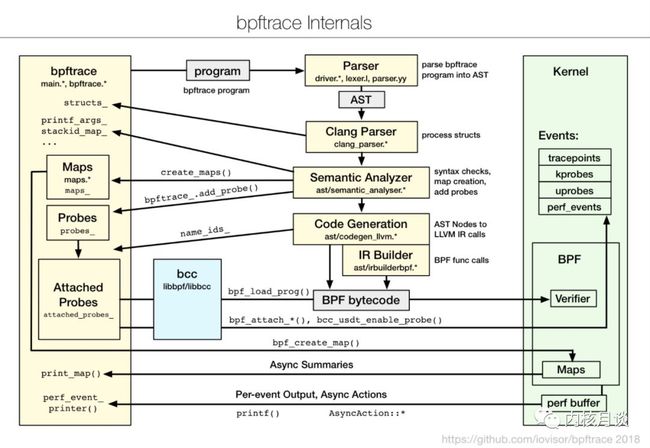
帮助大家学习bpftrace,我创建了几个“参考”
one-liners tutorial
reference guide
bpftrace的“单行命令手册” 是基于 FreeBSD DTrace Tutorial, 我觉得这是一个非常高效的方法去学习bpftrace。
自从我帮助参与开发bpftrace,我发现我也会时不时的引入一些bugs,可能bpftrace会SIGSEGV,或者,coredump?也许吧,我们已经尽力的修复了好多这些问题。也有可能bpftrace会输出一些因为和LVM 或者 BPF verifier不兼容,不适配导致的错误提示(用-v了)?如果是的话,请让我知晓,也许bpftrace会让kernel panic?呵呵,这个很少很少了,我都没有见过,自从使用了eBPF组件到现在这么多年来。如果出现了用户态的bugs,bpftrace的crash或者stuck,hang之类的,需要被killed才可以的情况,请在github上提交一个issue,让我们也知道此事,当然,如果你可以,也欢迎你可以帮我们修复这些bug。bpftrace到现在我们的测试集里已经有200多个test case了。
bpftrace/eBPF vs DTrace equivalency
这一个章节,我会写一些“例子”,来对比“bpftrace/eBPF” 和 “Dtrace”,但是,注意一点,并不是说kernel中的eBPF就是仅仅实现了一个 “Linux版的Dtrace” 哦,eBPF还有很多的用处。
eBPF是其作者 Alexei Starovoitov 在PLUMgrid工作的时候(现在在Facebook)创建,是打算做成一个 Kernel中 通用的 “虚拟机”的,可以帮助实现软件定义网络的场景。很明显,它还有很多其他的场景,比如:eXpress Data Path, container security and networking, iptables, infrared decoding, intrusion detection, hyperupcalls, 和 FUSE performance. 实际上,eBPF直接使用是很费劲的,所以,才产生了bcc上层的python库。
bpftrace就是希望可以成为一个更加高级的,可以达到“手到擒来”的工具,bpftrace参考了Dtrace的实现,我们已经往bpftrace中添加了很多功能,我也知道,我们还没有做到Dtrace的所有功能,比如:custom aggregation printing, shell arguments, translators, sizeof(), speculative tracing, and forced panic,我们现在添加的,只是我们现在需要的。
Dtrace同样也并不是包含了bpftrace的所有功能,比如:bpftrace的参数,可以在shell中使用,如果有些功能bpftrace做不到,那就用bcc,它们的关系就像是:

同样,也有一些事儿,eBPF可以做到,但是Dtrace不能的。尤其是,可以保存和接受stack trace作为变量的能力。我已经耦合到bpftrace中了,并且使用这个工具,尝试分析了几个fd泄漏的问题,这个工具大概是这样(fdleak.bt):
1kretprobe:__alloc_fd
2{
3 $fd = retval;
4 @alloc_stack[comm, pid, $fd] = ustack;
5}
6
7kprobe:__close_fd
8{
9 $fd = arg1;
10 delete(@alloc_stack[comm, pid, $fd]);
11}
它会打印那些分配但是没有被释放的fd的user-level stacks, 它是在分配fd的时候保存栈信息,在free fd的时候,将对应的栈信息删除。当bpftrace退出的时候,它会打印剩下的@ alloc_stack: 也就是没有被释放掉的fd的stack信息。我还写了一个更长的脚本,包含了timestamp信息的,所以我抓取更长的数据,你可以将这个技术复用到任何一种object分配的场景,或者给你自己的泄漏检测工具增添色彩。如果是Dtrace,这需要dump出所有的stacks到一个文件中,然后事后处理,这个会引起更大的处理开销。eBPF可以在kernel中做这些事情,在kernel中对数据进行过滤,这样效率更高。
还有一个更重要的案例,在我的另外一个文章off-wake time中有所展示。
DTrace和bpftrace对比清单
如果你已经了解Dtrace,这里会花费你10分钟时间,看看Dtrace和bpftrace之间的对比,这里列出主要的区别,截止到2018.08:

这个清单当然没有罗列bpftrace的所有的功能,比如 access aggregation elements, user-level tracing system wide, save stacks as variables, 更多可以看这里reference_guide
Dtrace和bpftrace的脚本对比
这里,我以我在Dtrace上曾经实现的工具(seeksize.d)为例子, 比较一下Dtrace和bpftrace的脚本在实现上的差异:
1DTrace
2
3#pragma D option quiet
4
5/*
6 * Print header
7 */
8dtrace:::BEGIN
9{
10 printf("Tracing... Hit Ctrl-C to end.\n");
11}
12
13self int last[dev_t];
14
15/*
16 * Process io start
17 */
18io:genunix::start
19/self->last[args[0]->b_edev] != 0/
20{
21 /* calculate seek distance */
22 this->last = self->last[args[0]->b_edev];
23 this->dist = (int)(args[0]->b_blkno - this->last) > 0 ?
24 args[0]->b_blkno - this->last : this->last - args[0]->b_blkno;
25
26 /* store details */
27 @Size[pid, curpsinfo->pr_psargs] = quantize(this->dist);
28}
29
30io:genunix::start
31{
32 /* save last position of disk head */
33 self->last[args[0]->b_edev] = args[0]->b_blkno +
34 args[0]->b_bcount / 512;
35}
36
37/*
38 * Print final report
39 */
40dtrace:::END
41{
42 printf("\n%8s %s\n", "PID", "CMD");
43 printa("%8d %S\n%@d\n", @Size);
44}
1bpftrace
2
3/*
4 * Print header
5 */
6BEGIN
7{
8 printf("Tracing... Hit Ctrl-C to end.\n");
9}
10
11/*
12 * Process io start
13 */
14tracepoint:block:block_rq_insert
15/@last[args->dev]/
16{
17 // calculate seek distance
18 $last = @last[args->dev];
19 $dist = (args->sector - $last) > 0 ?
20 args->sector - $last : $last - args->sector;
21
22 // store details
23 @size[pid, comm] = hist($dist);
24}
25
26tracepoint:block:block_rq_insert
27{
28 // save last position of disk head
29 @last[args->dev] = args->sector + args->nr_sector;
30}
31
32/*
33 * Print final report
34 */
35END
36{
37 printf("\n@[PID, COMM]:\n");
38 print(@size);
39 clear(@size);
40 clear(@last);
41}
将功能从Soloris上移植到Linux上的主要工作可不是简简单单的语法上移植,而是研究和测试以找到等效的Linux跟踪点及其参数。主要的工作与追踪语言无关。
既然我移植了它到Linux上,但是我觉得有点奇怪。我猜想这就回答了一个问题:磁盘在寻找吗?但它实际上回答了一个棘手的问题:应用程序是否导致磁盘搜索?我在2004年写了seeksize.d,所以我必须回想一下那个时候才能理解它。当时,我已经可以通过解释iostat(1)输出来判断磁盘是否正在寻找:看到高磁盘延迟,但I/O很小。iostat(1)无法告诉我的是,这是因为使用磁盘的应用程序相互竞争,还是应用程序本身正在应用随机工作负载。这就是我写的seeksize.d要回答的问题,一个指导进一步优化的答案:您是需要在不同的磁盘上分离应用程序,还是调整一个应用程序的磁盘工作负载。
为何我花那么久时间做这件事?
我曾经告诉很多工程师和一些公司关于做一个在Linux上的高级trace工具,我认为这个是Linux商业环境下一个比较有趣的课题,所以,我才花那么长的时间来完成它:
1. Linux isn't a company
在开发DTrace时,Sun Microsystems的首席执行官Scott McNealy喜欢说“一箭双雕”。如此之多,以至于员工们曾经在他的办公室窗户上安装了一个巨大的箭头,就像愚人节的笑话一样。在Linux中,所有的工作都没有落后于一个跟踪箭头,而是分成14个(systemtap、lttng、ftrace、perf_events、dtrace4linux、oel dtrace、ktap、sysdig、intel pin、bcc、shark、ply和bpftrace)。如果Linux是一家公司,管理层可以合并重叠的项目,并专注于一个或两个跟踪程序。但事实并非如此。
2. Linux won
Linux放弃了自己的动态跟踪实现(DProbes,2000年),为Sun创造了一个开发自己的竞争特性的机会。Sun拥有数十亿的收入,无数员工致力于使DTrace成功(包括销售、营销、教育服务等),Linux不存在这种情况。Linux已经赢了,而且没有公司提供任何真正的资源来构建一个有竞争力的跟踪程序,只有一个例外:RedHat。
3. Most funding went into SystemTap
询问一位RHEL客户有关Dtrace的情况,他们可能会说他们几年前就有了:systemtap。然而,SystemTap从来没有完全合并到Linux内核中(部分是这样的,比如uprobes),所以作为一个脱离树的项目,它需要维护才能工作,而RedHat只为RHEL做了这一点。作为一个Ubuntu用户,试着向RedHat抱怨:他们经常会说“切换到RHEL”。你能怪他们吗?问题是,这是唯一真正的钱在桌上建立一个LinuxDTrace(特别是自从红帽拿起曾经Sun公司的帐户,谁想要DTrace),它进入了SystemTap。
4. Good-enough solutions
另一个障碍是足够好的解决方案。一些公司已经知道如何让SystemTap(或LTTNG、FTrace或Perf)工作得足够好,并且很高兴。他们希望ebpf/bcc/bpftrace完成吗?当然。但它们不会帮助开发它们,因为它们已经有了足够好的解决方案。一些公司很乐意使用我的ftrace性能工具或我的BCC工具,所以我自己以前的工程工作给了他们一个不帮助构建更好的东西的理由。
5. CTF/BTF
Dtrace是在Solaris上构建的,它已经有了紧凑的类型格式来提供所需的结构信息。Linux有dwarf和debuginfo,与ctf不同的是,它并不常见。这阻碍了开发真正的类似DTrace的跟踪器。直到最近,在Linux4.18版本中,我们是否已经有了Linux:BPF类型格式(BTF)的CTF技术。
默认安装
值得一提的是,Dtrace是Solaris上的默认安装。这确实有助于采用,因为客户没有选择!现在想象一下,要使bpftrace成为所有Linux发行版上的默认安装,需要做什么。我认为这是一个长期的尝试,这意味着Linux可能永远不会拥有与Solaris上DTrace相同的体验。但这是一个可以帮助您的领域:请让您的发行版维护人员在默认情况下包括bpftrace(加上bcc和sysstat)。这些是危机工具,通常用于分析遇到紧急性能问题的系统,安装它们的时间(“apt-get-update;apt-get-install…”)可能意味着问题在您有机会看到之前就消失了。
Dtrace工具如何?
仅仅因为Linux有了ebpf,并不能使dtrace一夜之间成为一个糟糕的工具。它在拥有它的操作系统上仍然有用,并且任何具有它的操作系统都可以很好地为将来升级到ebpf做好准备,ebpf可以重用内部组件,比如提供者工具。工作已经开始将ebpf带到bsd,bpf就是在那里产生的。
值得让那些花时间学习dtrace的人放心的是,我不认为时间浪费了。使用dtrace或bpftrace最困难的部分是知道如何处理它,遵循解决问题的方法。一旦你进入了一些复杂软件的内部,对于一个紧迫的生产问题,无论你输入quantize()还是hist()都是最不重要的问题。在调试dtrace的问题时,也可以帮助bpftrace。
ply工具如何?
ply, 作者是: Tobais Waldekranz , 另外一种到BPF的后端(front-end), 我喜欢它,虽然这个项目还没有完成,但是,我发现了很多有意思的区别和bpftrace比较起来: ply执行指令很直接,bpftrace使用了llvm的IR API, ply使用了C语言,bpftrace是C++。
1# ply -A -c 'kprobe:SyS_read { @start[tid()] = nsecs(); }
2 kretprobe:SyS_read /@start[tid()]/ { @ns.quantize(nsecs() - @start[tid()]);
3 @start[tid()] = nil; }'
42 probes active
5^Cde-activating probes
6[...]
7@ns:
8
9 [ 512, 1k) 3 |######## |
10 [ 1k, 2k) 7 |################### |
11 [ 2k, 4k) 12 |################################|
12 [ 4k, 8k) 3 |######## |
13 [ 8k, 16k) 2 |##### |
14 [ 16k, 32k) 0 | |
15 [ 32k, 64k) 0 | |
16 [ 64k, 128k) 3 |######## |
17 [128k, 256k) 1 |### |
18 [256k, 512k) 1 |### |
19 [512k, 1M) 2 |##### |
20[...]
感谢
bpftrace是由 Alastair Robertson创建的项目,同时在eBPF和bcc项目中做了大量的贡献,可以看看DTrace for Linux 2016 里的感谢部分有另外对Dtrace和早期的tracing工作的对其他人的贡献和鸣谢。如果您在使用的是bpftrace,您使用了Alexei Starovoitov在(ebpf)中开发的代码、包括:Brendan Blanco(libbpf)、我自己、Sasha Goldshtein(USDT)和其他人开发的大量代码。有关代码的lib库疑问,请参阅bcc。Facebook还有许多工程师在BPF和BCC上工作,他们使其成为当今成熟的技术。
bpftrace本身有一种类似Dtrace的语言,以及awk和c。这不是eBPF上高级语言的第一次尝试:第一次是由Jovi Zangwei开发的Shark,然后是Tobais Waldekranz开发的ply,然后由Alastair Robertson开发的bpftrace。甚至在某种程度上,Richard Henderson正在开发基于eBPF作为SystemTap的后端的工作。感谢所有从事这些工作的人,以及我们使用的所有其他技术。
最后,感谢Netflix,它为我提供了一个很好的支持环境,帮助我开发和贡献各种技术,包括BPF。
结局
自从四年前eBPF开始并入内核以来,它改变了Linux跟踪技术的格局。我们现在有了lib、tools和为eBPF构建的high-level front-end:bpftrace。bpftrace是性能分析利器,可以帮助您分析其他工具做不到的事情。它是对BCC的补充:BCC非常适合于复杂的工具,而bpftrace非常适合于“一行可以表达的命令”(one-liners)。在这篇文章中,我描述了bpftrace以及它如何与Dtrace进行比较。在我的下一篇文章中,我将更加关注bpftrace。
更多阅读:
(https://github.com/iovisor/bpftrace)
(https://github.com/iovisor/bpftrace/blob/master/docs/tutorial_one_liners.md)
(https://github.com/iovisor/bpftrace/blob/master/docs/reference_guide.md)
(https://github.com/iovisor/bcc)
bpftrace的作者Alastair第一次关于 bpftrace 的演讲 Tracing Summit 在爱丁堡, Oct 25th.
如果想使用bpftrace,你需要使用比较新的内核版本(4.9以上) 关于安装可以看看bcc repo中的Install部分,或者看看:(https://github.com/iovisor/bpftrace/blob/master/INSTALL.md#ubuntu) 提供的安装包。(如果你是工作在Netflix,可以使用nflx-bpftrace安装包),最后,你会基于bpftrace做什么呢?

查看我们精华技术文章请移步:
Linux阅码场原创精华文章汇总
扫描二维码关注"Linux阅码场"
