Python实战之——机械化操作股票与基金1——获取基金数据
一.前言
学完了基本的Python以后,打算做点自己想做的事情。刚好最近学习投资,觉得对于股票和基金的投资,个人化情绪的存在很大程度上影响了基金和股票的回报率(当然最好的情况下是市场上的其他人有情绪,然而只有你机械化地操作,这样你就可以获取到利润了)。当然要在投资中做到完全的无情绪化那是不可能的,不过对于机器(代码)来说,这就是可能存在的了。因此准备自己谢谢代码看看。这系列的文章可能分为如下:获取基金/股票数据——选择投资方案——模拟投资方案并计算利润——对比不同的投资方案并实践
二.获取基金数据思路
本篇文章我们先获取基金数据,之所以获取基金的数据而不是股票的数据,是因为获取股票的话一般要实时获取,那么对于被爬取数据的网站一般有反爬虫机制,对于我们这种Pyhon刚入门的人来说太不友好了。
思路如下:
1.选择获取数据的网站——天天基金
2.通过观察找到数据源——谷歌浏览器调试查看
3.解析数据源——正则表达
4.数据处理并输出——日期以及对应日期的值
三.获取基金实际操
1.首先我选择数据源网站是天天基金,因为网上其他例子大多数也是来着天天基金的。而且天天基金可以有一个基金成立以来的历史价格变化。所以基本符合了我的要求
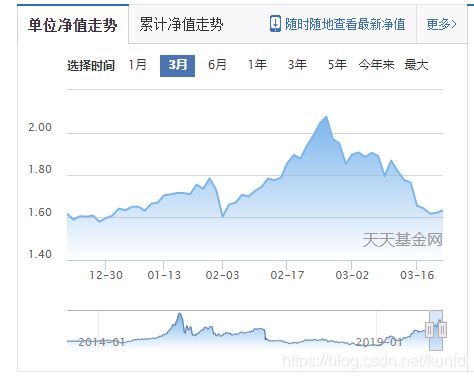
2.我们通过谷歌浏览器开发者模式,找到了一条请求。发现其返回的数据刚好有涉及到 “单位净值走势”,也就是上图相呼应
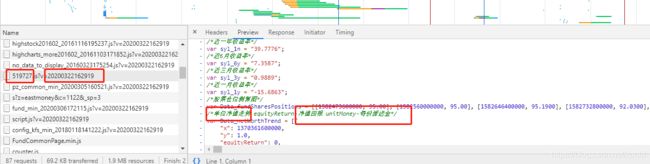
2.1.接着我们再往先看看,看看Data_netWorthTrend这变量的数据,我们发现其装了大量的数据,这里我们初步怀疑这个的数据就是该基金的历史数据其中y应该就是该基金的净值,为了验证这个想法。我们找到了Data_netWorthTrend变量的最后几个值和页面的值进行对比,看看是不是符合。——一开始我以为这是该基金的部分数据,不过后来我在调试模式下通过选择查看该基金的1个月,3个月,6个月…的数据,发现并没有再发送请求。因此基本就可以判断Data_netWorthTrend的数据就是该基金的历史数据了
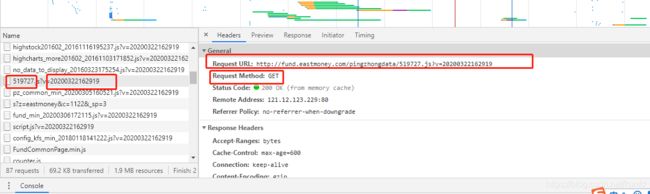
2.2.现在我们来看看请求链接。这个分析起来比较简单。就是
http://fund.eastmoney.com/pingzhongdata/+基金代码+.js?v=时间戳
3.解析数据源——正则表达
这个数据比较容易解析,所有的数据实际上只是在Data_netWorthTrend里面,也就是如下格式:
Data_netWorthTrend = [{.....},{.....},{......}]
对于每一条独特的数据,我们来看看。y明显是净值。那么时间会是哪一个,这里看来只有可能是x。不过x这种表达方式,是什么?如果是时间的话,那么应该是对比某个时间点,然后不断累积,看后面的x的确是不断增加。于是想到了——时间戳。接着上网找个时间戳的转化,将x的值转化,猜想正确
{
"x": 1370361600000,
"y": 1.0,
"equityReturn": 0,
"unitMoney": ""
}, {
"x": 1370534400000,
"y": 1.0,
"equityReturn": 0.0,
"unitMoney": ""
}, {
"x": 1371139200000,
"y": 1.0,
"equityReturn": 0.0,
"unitMoney": ""
},

4.数据处理并输出——日期以及对应日期的值
既然我们已经有了数据源以及知道如何解析数据源了,那么接下来就是将数据包装成我们想要的了。其实对于我们来说,只要该基金某天对应的净值,也就是日期+净值。所以我们这里只需要将日期进行格式转化,然后将日期和净值分别封装在两个列表中并汇集到一个列表输出就可以了。
四.代码实现
import requests
import re
import time
#时间戳转化为对应的时间
def changeDate(timestamp):
timeArray = time.localtime(int(timestamp))
formatDate = time.strftime("%Y-%m-%d", timeArray)
return formatDate
#获取数据(数组以及对应的日期)
def getFundData(fundcode,time):
#文件头模拟,模拟是浏览器发起的
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3",}
#网页地址
url='http://fund.eastmoney.com/pingzhongdata/'+fundcode+'.js?v='+time
#模拟浏览器发出
response = requests.get(url,headers=headers)
response.encoding = 'utf-8'
#通过查看网页代码,可以知道主要的数据在......之间,
html = response.text
Data_netWorthTrend = re.findall(r'Data_netWorthTrend = \[.*?\];',html)
Daily_Datas = re.findall(r'{(.*?)}',Data_netWorthTrend[0])
Daily_Values = []
Daily_Times = []
Daily_All = []
for single_data in Daily_Datas:
#获取值
Daily_Values.append(float(single_data.split(",")[1].split(":")[1].replace("'",'')))
#获取对应的日期时间
Daily_Times.append(changeDate(single_data.split(",")[0].split(":")[1].replace("'",'')[0:10]))
Daily_All.append(Daily_Values)
Daily_All.append(Daily_Times)
return Daily_All