【个人整理】faster-RCNN的关键点(区域推荐网络RPN)详解


前言:faster-RCNN是区域卷积神经网络的第三篇文章,是为了解决select search方法找寻region proposal速度太慢的问题而提出来的,整个faster-RCNN的大致框架依然是沿袭了fast-RCNN的基本能结构,只不过在region proposal的产生上面应用了专门的技术手段——区域推荐网络(region proposal network,即RPN),这是整个faster最难以理解的地方,本文也将以他为重点进行说明。
一、 faster-RCNN的背景
Faster R-CNN 发表于 NIPS 2015,其后出现了很多改进版本,后面会进行介绍.
R-CNN - Rich feature hierarchies for accurate object detection and semantic segmentation 是 Faster R-CNN 的启发版本. R-CNN 是采用 Selective Search 算法来提取(propose)可能的 RoIs(regions of interest) 区域,然后对每个提取区域采用标准 CNN 进行分类.
出现于 2015 年早期的 Fast R-CNN 是 R-CNN 的改进,其采用兴趣区域池化(Region of Interest Pooling,RoI Pooling) 来共享计算量较大的部分,提高模型的效率.
Faster R-CNN 随后被提出,其是第一个完全可微分的模型. Faster R-CNN 是 R-CNN 论文的第三个版本.
R-CNN、Fast R-CNN 和 Faster R-CNN 作者都有 Ross Girshick.
二、faster-RCNN的网络结构
Faster R-CNN 的结构是复杂的,因为其有几个移动部件. 这里先对整体框架宏观介绍,然后再对每个部分的细节分析.
问题描述:
针对一张图片,需要获得的输出有:
- 边界框(bounding boxes) 列表,即一幅图像有多少个候选框(region proposal),比如有2000个;
- 每个边界框的类别标签,比如候选框里面是猫?狗?等等;
- 每个边界框和类别标签的概率。
2.1 faster-RCNN的基本结构
除此之外,下面的几幅图也能够较好的描述发图尔-RCNN的一般结构:


2.2 faster-RCNN的大致实现过程
整个网络的大致过程如下:
(1)首先,输入图片表示为 Height × Width × Depth 的张量(多维数组)形式,经过预训练 CNN 模型的处理,得到卷积特征图(conv feature map)。即将 CNN 作为特征提取器,送入下一个部分。这种技术在迁移学习(Transfer Learning)中比较普遍,尤其是,采用在大规模数据集训练的网络权重,来对小规模数据集训练分类器. 后面会详细介绍.
(2)然后,RPN(Region Propose Network) 对提取的卷积特征图进行处理. RPN 用于寻找可能包含 objects 的预定义数量的区域(regions,边界框)。这是整个文章最核心的改进,也是本文会着重介绍的点。
基于深度学习的目标检测中,可能最难的问题就是生成长度不定(variable-length)的边界框列表. 在构建深度神经网络时,最后的网络输出一般是固定尺寸的张量输出(采用RNN的除外). 例如,在图片分类中,网络输出是 (N, ) 的张量,N 是类别标签数,张量的每个位置的标量值表示图片是类别 labeli{ label_i }labeli 的概率值.
在 RPN 中,通过采用 anchors 来解决边界框列表长度不定的问题,即,在原始图像中统一放置固定大小的参考边界框. 不同于直接检测 objects 的位置,这里将问题转化为两部分:
对每一个 anchor 而言,
- anchor 是否包含相关的 object?
- 如何调整 anchor 以更好的拟合相关的 object?
这里可能不容易理解,后面会深入介绍anchor以及RPN相关的实现原理。
(3)当获得了可能的相关objects 和其在原始图像中的对应位置之后,问题就更加直接了. 采用 CNN 提取的特征和包含相关 objects 的边界框,采用 RoI Pooling 处理,并提取相关 object 的特征,得到一个新的向量.
最后,基于 R-CNN 模块,得到:
- 对边界框内的内容进行分类,(或丢弃边界框,采用 background 作为一个 label.)
- 调整边界框坐标,以更好的使用 object.
上面的过程没有涉及到一些重要的细节信息. 但包括了 Faster R-CNN 的大致实现过程。
2.3 faster-RCNN的基本组成
faster-RCNN其实就是油几个基本的网络架构组成的。
Faster R-CNN的整体流程如下图所示。
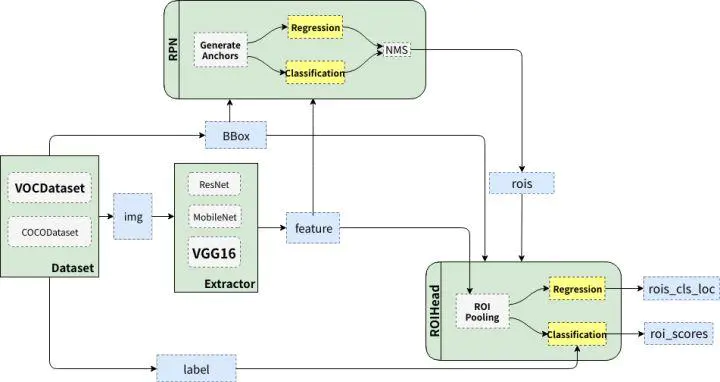
从上面的图形中可以看出,Faster R-CNN主要分为四部分(图中四个绿色框)
(1)Dataset数据。提供符合要求的数据格式(目前常用数据集是VOC和COCO);
(2)Extractor卷积神经网络。 利用CNN提取图片特征features(原始论文用的是ZF和VGG16,后来人们又用ResNet101);
(3)RPN(Region Proposal Network)。 负责提供候选区域rois(每张图给出大概2000个候选框);
(4)RoIHead。 负责对由RPN产生的ROI进行分类和微调。对RPN找出的ROI,判断它是否包含目标,并修正框的位置和座标。
Faster R-CNN整体的流程可以分为三步:
(1)提特征。 图片(img)经过预训练的网络(Extractor),提取到了图片的特征(feature)
(2)Region Proposal。 利用提取的特征(feature),经过RPN网络,找出一定数量的rois(region of interests)。
(3)分类与回归。将rois和图像特征features,输入到RoIHead,对这些rois进行分类,判断都属于什么类别,同时对这些rois的位置进行微调。
就是第二步是关键所在,第一步和第三部同fast-RCNN一样。
三、区域推荐网络RPN详解
3.1 边框的位置到底用什么表示?
目标检测之所以难,是因为每一个物体的区域大小是不一样的,每一个区域框有着不同的大小size(也称之为scale)和不同的长宽比(aspect ratios)
现在假设,已经知道图片中有两个 objects,首先想到的是,训练一个网络,输出 8 个值:两对元组 (xmin,ymin,xmax,ymax)、(xmin,ymin,xmax,ymax)分别定义了每个 object 的边界框.。这种方法存在一些基本问题. 例如,
(1)当图片的尺寸和长宽比不一致时,良好训练模型来预测,会非常复杂;(这里不是很理解,望有大神告知!)
(2)另一个问题是无效预测:预测 xmin和xmax 时,需要保证 xmin 事实上,有一种更加简单的方法来预测 objects 的边界框,即,学习相对于参考boxes 的偏移量. 假设参考 box的位置由以下确定:(xcenter,ycenter,width,height),则需要预测量为:( Δxcenter,Δycenter,Δwidth,Δheight),它们的取值一般都是很小的值,以调整参考 box 更好的拟合所需要的。 3.2 RPN网络的基本结构 首先看到这幅图的时候我是一脸懵逼,看了半天又是一知半解,后面我会结合这幅图详细来说,这里暂且先放一副结构图。我们发现,其实整个RPN的网络很浅很简单,但是为什么要这样设计呢?这样设计能达到什么样的效果呢? 3.3 RPN的核心概念——anchor anchor,中文意思是锚点的意思,那到底什么是anchor?有很多不同的解释,其实不能说那种解释完全标准,主要是站在不同的角度进行解释的,都有道理,本文会将各种解释综合起来,尽量说得易懂一点。 3.3.1 知识回顾 要理解什么是anchor,就要知道我们为什么搞出一个RPN这种东西,回顾一下前面三种目标检测架构RCNN、SPPNet、fast-RCNN, (1)RCNN是在原始图像中使用select search方法选择大约2000个候选框,然后对每个候选框进行卷积运算; (2)SPPNet和fast-RCNN是先让整个图片经过CNN,然后在得到的特征图上使用select search选择2000个左右的候选框,其实我们真正需要的还是在原始图像上的候选区域,那为什么在卷积之后的特征图上也可以这么做呢?这是因为卷积之后的特征图和原始图像之间存在的映射关系,在特征图上的候选区可以映射到原始图像上。 总而言之:我们要使用RPN的目的也就是要产生(原始图像上的)候选框。而且这里有一个重要的信息,就是卷积之后的feature map和原始图像之间是有一个映射关系的,如果我能够在feature map上面找到响应候选框,也就代表了在原始图像上找到了候选框。 3.3.2 RPN的输入与输出 输入:RPN是接在feature map之后的,因此它的输入是feature map; 输出:我希望得到的是候选区域,因此输出的是候选区域,这样说没错,但是在网络中其实流动的都是数据啊,这一个框框嗯么表示呢?当然也是通过数据的形式来表示了,还有一点就是这个框框里面有目标还是没有目标,这也是通过数据来表示的。 3.3.3 到底什么是anchor? 有很多文献中这样说道:Anchor是大小和尺寸固定的候选框,个人感觉这种说法是很不准确的,只是一个表象而已。在回答什么 是anchor之前,我们先看一下RPN网络的一个第一步运算,RPN的第一步运算实际上就是一个3*3*256的卷积运算,我们称3*3为一个滑动窗口(sliding window)。假设RPN的输入是13*13*256的特征图,然后使用3*3*256的卷积核进行卷积运算,最后依然会得到一个a*a*256的特征图,这里的a与卷积的步幅有关。 在原始论文中,我们选定了3种不同scale、3种不同长宽比(aspect ratios)的矩形框作为“基本候选框(这是我起的名字)”, 三种scale/size是{128,256,512} 三种比例{1:1 , 1:2 , 2:1} 故而一共是3x3=9种,有很多文献说这就是9个anchors,之所以我觉得不准确是因为下面的两个方面 (1)anchor顾名思义为锚点,这这是一个矩形框,与锚点本身的含义是不符合的; (2)很明显,这9个基本候选框的长宽远远大于特征图的长宽,所以这9个指的应该是原始图像,结合论文中要对原始图像进行缩放到600*1000左右的大小,更加确定了这一点,有的人说锚点是特征图上的某一个点或者是候选框,既然这9个根本就不是特征图上的候选框,那自然不存在锚点之说了。 3.3.4 anchor锚点的本质 锚点的真实含义:应该是特征图的某一个像素与对应在原始图像的某一个像素,即它本质上指的是特征图上当前滑窗的中心在原像素空间的映射点称为anchor,即anchor是在原始图像上的 然后以这个锚点为中心,配上规定的9个基本候选框,这就正确了,所以在原始图像上的图像大致如下: 其中每一个黑色的点是anchor锚点,以及画出的以这些锚点为中心的9个基本候选框。 3.3.5 为什么这样子设计可行? 依然以上面的例子进行说明,假定输出特征图为13*13*256,然后在该特征图上进行3*3*256的卷积,默认进行了边界填充 那么每一个特征图上一共有13*13=169个像素点,由于采用了边界填充,所以在进行3*3卷积的时候,每一个像素点都可以做一次3*3卷积核的中心点,那么整个卷积下来相当于是有169个卷积中心,这169个卷积中心在原始图像上会有169个对应的锚点,然后每个锚点会有9个默认大小的基本候选框,这样相当于原始图像中一共有169*9=1521个候选框,这1521个候选框有9种不同的尺度,中心又到处都分布,所以足以覆盖了整个原始图像上所有的区域,甚至还有大量的重复区域。 这个映射过程如下所示(自己画的,不好请包涵): 补充: 关于特征图和原始图像的映射关系,这里有一点需要补充,假定原始的图像长宽分别是W*H,特征图的长宽是w*h,则有如下关系: w=W/r h=W/r 这里的r称之为下采样率,即各个卷积层和池化层步幅的乘积,在VGG中,r=19. 但是我们说了,网络学习的是数据,这里的候选框是抽象的结果,数据到底是怎样的呢? 其实我们需要的并不是这个候选框本身,我们需要的数据是每一个候选框的位置信息(x,y,w,h)和目标信息(有,没有),我们可以这样理解,每一个候选框都包含这6个信息,也可以说成是是6个特征,特征图上的每一个像素都对应于原始图像上的一个“锚点anchor”,而每一个anchor又包含了9个尺寸比例各不相同的标准候选框,每一个候选框又包含着这6个基本信息,所以现在相当于是对每一个特征像素进行学习,也就间接的学习到了原始图像上大量的锚点以及大量的候选框的信息,这样理解不就更好了吗(个人理解,有错误请大佬纠正!) 总结归纳: 当前滑窗的中心在原像素空间的映射点称为anchor,以此anchor为中心,生成k(paper中default k=9, 3 scales and 3 aspect ratios)个proposals。虽然 anchors 是基于卷积特征图定义的,但最终的 anchos 是相对于原始图片的. RPN的本质是 “ 基于滑窗的无类别obejct检测器 ” 。 3.4 生成anchor的作用和目的 3.5 RPN的训练过程 上面只讨论了RPN的第一步运算——实际上就是卷积运算,接下来考虑后面的运算步骤,如下: 上面的用黑色圈出来的部分是第一步运算,用红色圈圈圈出来的是第二步运算,我们将第二步运算单独拿出来看,如下图所示: 注意:这里图片的和上面的稍微有所区别,但是没关系,只要能理解清楚意思就好。 RPN 是全卷积(full conv) 网络,其采用基础网络输出的卷积特征图作为输入. 首先,采用 512 channel,3×3 kernel 的卷积层(上面的例子采用的是256个channel,但是不影响理解),然后是两个并行的 1×1 kernel 的卷积层,该卷积层的 channels 数量取决每个点(每个anchor)所对应的的 标准候选框K 的数量,在这两个并行的1x1卷积中,左侧的是进行分类的,这里的分类只是分有和无两类,即候选框中有目标还是没有目标,至于目标到底是什么先不管,由于每一个anchor对应k个候选框,每一个候选框有两个取值(即有和无,用概率大小表示)所以每一个anchor对应的输出应该为一个2K维度的向量,故而左侧的分类卷积使用2K个channel; 同样的道理,右侧是获取边框位置信息的卷积网络,由于每一个anchor对应k个候选框,每一个候选框有4个位置取值(x,y,w,h)所以每一个anchor对应的输出应该为一个4K维度的向量,故而右侧的卷积使用4K个channel; 这里的理解是很重要的。 那究竟RPN网络是如何进行训练的呢? 3.6 RPN是如何产生ROI的? RPN在自身训练的同时,还会提供RoIs(region of interests)给Fast RCNN(RoIHead)作为训练样本。RPN生成RoIs的过程(ProposalCreator)如下: (1)对于每张图片,利用它的feature map, 计算 (H/16)× (W/16)×9(大概20000)个anchor属于前景的概率,以及对应的位置参数。(这里的W、H表示原始图像的宽和高,前面已经有说过了) (2)选取概率较大的12000个anchor,利用回归的位置参数,修正这12000个anchor的位置,得到RoIs,利用非极大值((Non-maximum suppression, NMS)抑制,选出概率最大的2000个RoIs 注意:在inference的时候,为了提高处理速度,12000和2000分别变为6000和300. 注意:这部分的操作不需要进行反向传播,因此可以利用numpy/tensor实现。 RPN的输出:RoIs(形如2000×4或者300×4的tensor) 3.7 RPN网络与Fast R-CNN网络的权值共享 一个是迭代的,先训练RPN,然后使用得到的候选区域训练Fast R-CNN,之后再使用得到的Fast R-CNN中的CNN去初始化RPN的CNN再次训练RPN(这里不更新CNN,仅更新RPN特有的层),最后再次训练Fast R-CNN(这里不更新CNN,仅更新Fast R-CNN特有的层)。 RPN只是给出了2000个候选框,RoI Head在给出的2000候选框之上继续进行分类和位置参数的回归。其实所谓的ROIHead就是对生成的候选框进行处理,这个地方与前面的fast-RCNN是一样的。 4.1 ROIHead的网络结构 由于RoIs给出的2000个候选框,分别对应feature map不同大小的区域。首先利用ProposalTargetCreator 挑选出128个sample_rois, 然后使用了RoIPooling 将这些不同尺寸的区域全部pooling到同一个尺度(7×7)上。下图就是一个例子,对于feature map上两个不同尺度的RoI,经过RoIPooling之后,最后得到了3×3的feature map. RoIPooling,其实这里的ROIPooling跟fast-RCNN里面的是一样的。 RoI Pooling 是一种特殊的Pooling操作,给定一张图片的Feature map (512×H/16×W/16) ,和128个候选区域的座标(128×4),RoI Pooling将这些区域统一下采样到 (512×7×7),就得到了128×512×7×7的向量。可以看成是一个batch-size=128,通道数为512,7×7的feature map。 为什么要pooling成7×7的尺度?是为了能够共享权重。在之前讲过,除了用到VGG前几层的卷积之外,最后的全连接层也可以继续利用。当所有的RoIs都被pooling成(512×7×7)的feature map后,将它reshape 成一个一维的向量,就可以利用VGG16预训练的权重,初始化前两层全连接。最后再接两个全连接层,分别是: FC 21 用来分类,预测RoIs属于哪个类别(20个类+背景) FC 84 用来回归位置(21个类,每个类都有4个位置参数) 4.2 训练 前面讲过,RPN会产生大约2000个RoIs,这2000个RoIs不是都拿去训练,而是利用ProposalTargetCreator 选择128个RoIs用以训练。选择的规则如下: RoIs和gt_bboxes 的IoU大于0.5的,选择一些(比如32个) 选择 RoIs和gt_bboxes的IoU小于等于0(或者0.1)的选择一些(比如 128-32=96个)作为负样本 为了便于训练,对选择出的128个RoIs,还对他们的gt_roi_loc 进行标准化处理(减去均值除以标准差) 对于分类问题,直接利用交叉熵损失. 而对于位置的回归损失,一样采用Smooth_L1Loss, 只不过只对正样本计算损失.而且是只对正样本中的这个类别4个参数计算损失。举例来说: 一个RoI在经过FC 84后会输出一个84维的loc 向量. 如果这个RoI是负样本,则这84维向量不参与计算 L1_Loss 如果这个RoI是正样本,属于label K,那么它的第 K×4, K×4+1 ,K×4+2, K×4+3 这4个数参与计算损失,其余的不参与计算损失。 4.3 生成预测结果 测试的时候对所有的RoIs(大概300个左右) 计算概率,并利用位置参数调整预测候选框的位置。然后再用一遍极大值抑制(之前在RPN的ProposalCreator用过)。 注意: 在RPN的时候,已经对anchor做了一遍NMS,在RCNN测试的时候,还要再做一遍 在RPN的时候,已经对anchor的位置做了回归调整,在RCNN阶段还要对RoI再做一遍 在RPN阶段分类是二分类,而Fast RCNN阶段是21分类 4.4 模型架构图 最后整体的模型架构图如下: 整体网络结构 需要注意的是: 蓝色箭头的线代表着计算图,梯度反向传播会经过。而红色部分的线不需要进行反向传播(论文了中提到了ProposalCreator生成RoIs的过程也能进行反向传播,但需要专门的算法)。 5.1 四类损失 虽然原始论文中用的4-Step Alternating Training 即四步交替迭代训练。然而现在github上开源的实现大多是采用近似联合训练(Approximate joint training),端到端,一步到位,速度更快。 在训练Faster RCNN的时候有四个损失: (1)RPN 分类损失:anchor是否为前景(二分类) (2)RPN位置回归损失:anchor位置微调 (3)RoI 分类损失:RoI所属类别(21分类,多了一个类作为背景) (4)RoI位置回归损失:继续对RoI位置微调 四个损失相加作为最后的损失,反向传播,更新参数。 5.2 三个creator (1)AnchorTargetCreator : 负责在训练RPN的时候,从上万个anchor中选择一些(比如256)进行训练,以使得正负样本比例大概是1:1. 同时给出训练的位置参数目标。 即返回gt_rpn_loc和gt_rpn_label。 (2)ProposalTargetCreator: 负责在训练RoIHead/Fast R-CNN的时候,从RoIs选择一部分(比如128个)用以训练。同时给定训练目标, 返回(sample_RoI, gt_RoI_loc, gt_RoI_label) (3)ProposalCreator: 在RPN中,从上万个anchor中,选择一定数目(2000或者300),调整大小和位置,生成RoIs,用以Fast R-CNN训练或者测试。 其中AnchorTargetCreator和ProposalTargetCreator是为了生成训练的目标,只在训练阶段用到,ProposalCreator是RPN为Fast R-CNN生成RoIs,在训练和测试阶段都会用到。三个共同点在于他们都不需要考虑反向传播(因此不同框架间可以共享numpy实现) 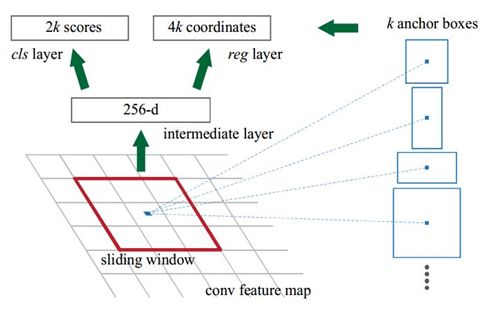


要知道,训练RPN网络是有监督训练,需要有数据、还要有相应的类标签,输入小网络的是512个通道的3*3滑窗,类标签没有给定,没有类标签就无法计算Loss损失函数,无法训练网络。以3*3滑窗中心对应原图的位置作为中心点,在原图生成9个不同尺度长宽比的anchor,然后每个anchor都会被分配到相应的类标签,有正样本(1)、负样本(0),也有不参与训练的框(not used),对正样本计算,就是回归的类标签,负样本不计算回归loss。0,1是二分类的标签。所以在原图生成anchor的目的之一是得到类标签。这里只得到了分类的标签(0,1),还有正样本的回归标签需要确定,该正样本的回归标签是其对应的ground truth计算出来的。负样本不计算回归损失没有回归标签。

RPN训练中对于正样本文章中给出两种定义。第一,与ground truth box有最大的IoU的anchors作为正样本;第二,与ground truth box的IoU大于0.7的作为正样本。文中采取的是第一种方式。文中定义的负样本为与ground truth box的IoU小于0.3的样本。
训练RPN的loss函数定义如下: ![]()
其中,i表示mini-batch中第i个anchor,pi表示第i个anchor是前景的概率,当第i个anchor是前景时pi为1反之为0,ti表示预测的bounding box的坐标,ti∗为ground truth的坐标。
看过Fast R-CNN文章详细解读文章的会发现,这部分的loss函数和Fast R-CNN一样,除了正负样本的定义不一样,其他表示时一样的。一个是交叉熵损失,一个是smooth_L1损失函数。
RPN最终目的是得到候选区域,但在目标检测的最终目的是为了得到最终的物体的位置和相应的概率,这部分功能由Fast R-CNN做的。因为RPN和Fast R-CNN都会要求利用CNN网络提取特征,所以文章的做法是使RPN和Fast R-CNN共享同一个CNN部分。
Faster R-CNN的训练方法主要分为两个,目的都是使得RPN和Fast R-CNN共享CNN部分,如下图所示 :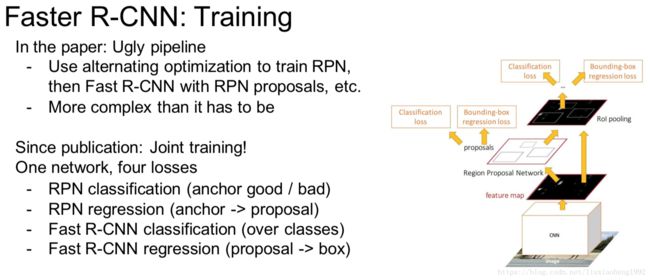
还有一个更为简单的方法,就是end-to-end的训练方法,将RPN和Fast R-CNN结合起来一起训练,tf版本的代码有这种方式的实现。四、RoIHead与Fast R-CNN的进一步训练
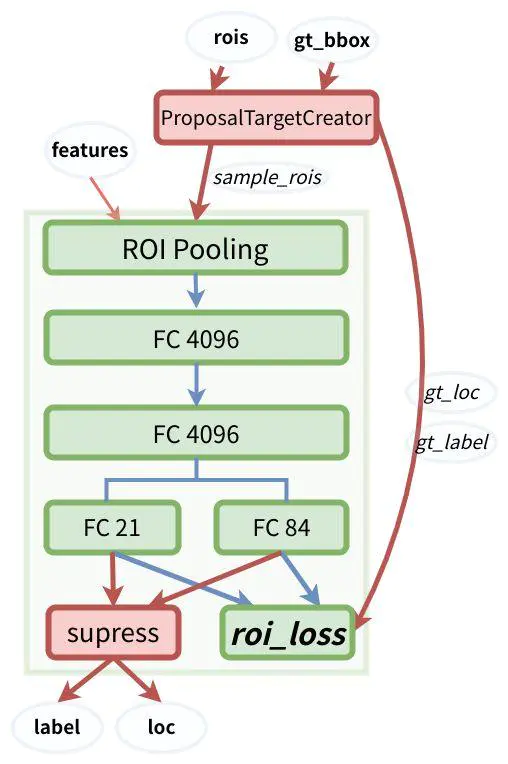


五、faster-RCNN里面的几个重要概念(四个损失三个creator)