Python从入门到入土---字典和合集(directory and set)
info = {
"key1":"value1", "key2":"value2","key3":"value3"
}key值不可重复,value可以。各个key之间用“,”隔开。value可以为list列表。
info2 = {
'龙婷':['设计部','UI',23283],'nihao':['shh','fyi',56880],2:3
}如果像上表,value是一个列表,首先要注意格式,不能忘了前面的tab,其次如果是查询龙婷里面的数据,命令行如下,如果想要修改数据,直接info[key][0]=' '

字典的特性:
- key-value结构
- key必须可被hash,且为不可变数据类型,必须唯一
- 可以存放任意多个值,可修改,可以不唯一
- 无序(没有索引,不占内存)
- 查找速度快
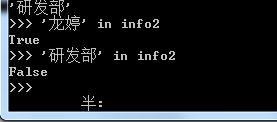
查key值是否存在的标准用法是'key' in info。获取内容的话是info.get('key')或者info['key'],二者存在差别,info['key']如果是一个null,程序会报错keyerror,因此常用get。
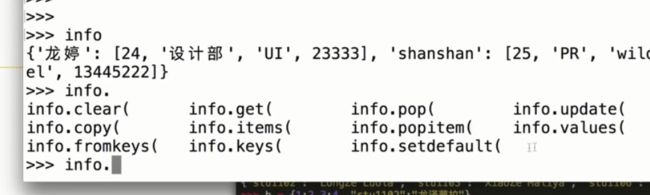
删除
- info.pop('key')删除某一特定的值,return被删除的value。
- info.popitem()不用指定key,随机删除一项,并返回整项。
- del info['value'],但是不返回值。
item() 将directory的每个项转换成元组。
info1.update(info2) 将两个字典合并到一个。其中如果两者有相同的key,info2 的value会覆盖掉info1的值
info.setdefault('key','value'),如果key存在,返回已存在的value;否则,生成一行字典,key为‘key’,value为‘value’,并返回‘value’
info.fromkeys(‘key1’,'key2',key3') ,字典会生成一大串key值,切各个value为null。适用于数据库前期的批量新建。
循环
for k in info
print(k,info[k])
输出结果为key,value
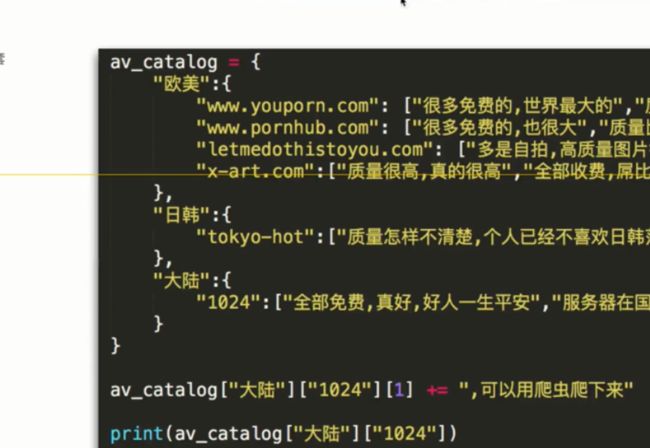
多级字典的嵌套
集合
集合set的格式有点像字典。用法也很简单,就离散数学的哪几个简单的集合的概念。
set1.union(set2) set1和set2 合并到同一个set中,消除重复的值
set1-set2 = set1-(交集)

s.pop()随机删除,返回被删除的值
s.remove('value'),不返回值
s.discard(value),不返回值。但是如果value不存在,不报错。
s.update(s2),或者直接s.update([2,3.33,])
交集:set1.intersection(set2) // set1 & set2
差集:set1.difference(set2) //set1-set2
并集:set1.union(set2) //set1|set2
并集减交集:set1.symmetric_difference(set2)
set1.isdisjoint(set2) 是不是不相交
set1.isuperset(set2) 是不是包含set2,相当于set1>=set2
set1.issubset(set2) 是不是set2 的子集,相当于set1<=set2