python编程从入门到实践——数据可视化之下载数据(第16章)
项目2:数据可视化之下载数据
摘要
这个章节主要讲怎样去下载和处理一些网上的数据,格式涉及有csv和json,涉及的模块有matplotlib、datatime、Pygal、json、requests、math、itertools、urllib、csv等等。这章主要做数据处理和简单分析,简单介绍下,csv数据下载后获取范围值以日期绘制折线图可观察两条线之间波动范围大小。json大量的数据分析走势,就分析某公司某一年股票收盘来说,观察图表每一天的数据大多不同波动范围,有时直观感觉某些线段很类似,类于周期涨幅(感觉炒股人员会关注吧)会需要将数据的非线性消除,有的又想看按照月份/按照星期/按周等等来看日均值的涨幅,这些都需要对数据进行一些处理更方便我们去观察获取我们需要的信息。
书本里的第一个取的是天气的表,我这边自己在网上找了一些数据来用,推荐一个大佬给的下载数据的地址
某个评论里出现的
优矿我下载数据的地方
像这么玩就成:


目录
代码
有些不太好理解的我都打了注释方便回顾。
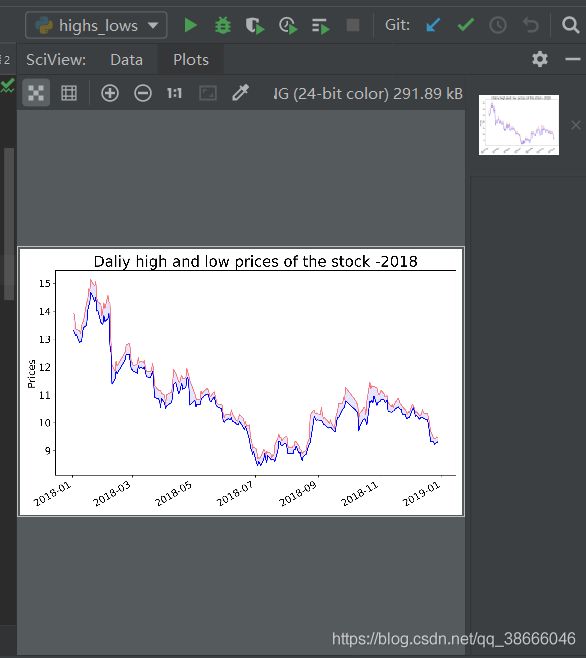
csv折线图,highs_lows.py(prices.csv是我自己下载的数据)
//
"""
读取csv表格中值的范围并绘制某股票2018年走势图
红线:high
蓝线:low
"""
import csv
from matplotlib import pyplot as plt
from datetime import datetime
file_name = "price.csv"
with open(file_name) as f_obj:
reader = csv.reader(f_obj)
header_row = next(reader)
# 使用函数把索引和值对应打印出来
for index, colum_header in enumerate(header_row):
print(index, colum_header)
# 从打印的值5 date,9 high,10 low可以看出高低值
highs, lows, dates = [], [], []
for row in reader:
# 规避异常数据
try:
# str转数字来绘图
high = float(row[9])
low = float(row[10])
current_date = datetime.strptime(row[5], "%Y-%m-%d")
except ValueError:
print(current_date, 'data missing')
else:
highs.append(high)
lows.append(low)
dates.append(current_date)
# 查看数据没问题lows<=highs
print(highs)
print(lows)
# 绘制股票价钱走势表
fig = plt.figure(dpi=300, figsize=(10, 6))
plt.plot(dates, highs, c='red', alpha=0.5)
plt.plot(dates, lows, c='blue')
plt.fill_between(dates, highs, lows, facecolor='blue', alpha=0.1)
# 设置图表属性
plt.title("Daliy high and low prices of the stock -2018", fontsize=24)
plt.xlabel('', fontsize=16)
# 设置斜的日期标签
fig.autofmt_xdate()
plt.ylabel("Prices", fontsize=16)
plt.tick_params(axis='both', which='major', labelsize=16)
plt.show()
json折线图,btc_close_2017.py(btc_close_2017_urllib.json是书本给的url下载保存的文件)
//
"""
说明:
S1.下载收盘数据:
使用urllib模块实现
从某个指定url download数据后保存成json格式文件
requests模块下载的方法也有 已注释
S2.用pygal绘制收盘价的折线图,和数据处理,包含求均值,分组,对数处理等等。
s1.无处理的简单收盘价的折线图
s2.总体趋势是非线性, 类于指数分布,细看6、9月有点类似的涨幅,验证周期性的假设需要
先将非线性的趋势消除math模块的对数变换解决semi-logarithmic 半对数变换math.log10()
s3.1-11月份的月日均值折线图
s4.前49星期的周日均值折线图
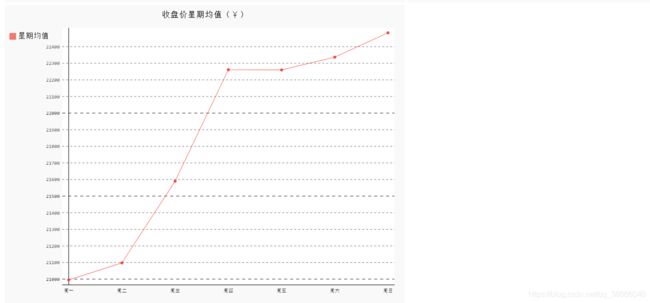
s5.前49星期的星期均值折线图
s6.绘制一个简单html界面,呈现所有表格
"""
from __future__ import (absolute_import, division,
print_function, unicode_literals)
try:
# python2.X版本
from urllib2 import urlopen
except ImportError:
# python3.X版本
from urllib.request import urlopen
import json
import requests
import pygal
import math
from itertools import groupby
JSON_URL = \
'https://raw.githubusercontent.com/muxuezi/btc/master/btc_close_2017.json'
FILE_NAME = 'btc_close_2017_urllib.json'
def load_data_from_url(json_url, file_name, method='requests'):
"""指定url下载数据并返回json格式数据,默认requests模块"""
if method == 'urllib':
response = urlopen(json_url)
# 读取数据
req = response.read()
# 将数据写入文件
with open(file_name, 'wb') as f:
f.write(req)
# 加载json 格式
file_urllib = json.loads(req)
print(file_urllib)
return file_urllib
elif method == 'requests':
# requests模块下载数据, .text属性是直接读取req的数据
req = requests.get(json_url)
with open(file_name, 'w') as f:
f.write(req.text)
# 加载json 格式
file_requests = req.json()
return file_requests
def draw_line(x_data, y_data, title, y_legend):
"""
绘制折线图,将x、y绑在一起排序后分成指定组
再在每组中给y求平均值再将x、y分开绘制图
"""
xy_map = []
# 注释:labmbda是匿名化函数 相当于key=x[0],两个列表会生一个元组列表,
# sort排序后groupby相当于取列表中每个元组的第一位用来分组 假如是星期,
# 那么group后就是7组 函数返回x就是所有星期,y就是所有组(我这里理解为元组)
# groupby返回类似[(1, (x,x,x,...)), (2, (x,x,x,...),...)
for x, y in groupby(sorted(zip(x_data, y_data)), key=lambda _: _[0]):
y_list = [v for _, v in y] # 元组转列表
xy_map.append([x, sum(y_list) / len(y_list)])
# 解绑 类于[[1,2], [2,3],...]->[1,2,...]和[2, 3,...]
x_unique, y_mean = [*zip(*xy_map)]
line_chart = pygal.Line()
line_chart.title = title
line_chart.x_labels = x_unique
line_chart.add(y_legend, y_mean)
line_chart.render_to_file(title + '.svg')
return line_chart
def __main__():
"""主函数"""
# 获取json数据
datas = load_data_from_url(JSON_URL, FILE_NAME)
print(datas)
# 创建5个列表存储日期和收盘价
dates, months, weeks, weekdays, closes = [], [], [], [], []
for data in datas:
dates.append(data['date'])
months.append(int(data['month']))
weeks.append(int(data['week']))
weekdays.append(data['weekday'])
closes.append(int(float(data['close'])))
# s1.绘制全天数的收盘价折线图,告诉图形不用显示所有的x轴标签
line_chart = pygal.Line(x_label_rotation=20, show_minor_x_labels=False)
line_chart.title = "收盘价(¥)"
line_chart.x_labels = dates
n = 20 # x轴坐标每隔20天显示一次
line_chart.x_labels_major = dates[::n]
line_chart.add('收盘价', closes)
line_chart.render_to_file('收盘价折线图(¥).svg')
# s2.绘制全天数的收盘价对数变换折线图
line_chart.title = "收盘价对数变换折线图(¥)"
closes_log = [math.log10(_) for _ in closes] # 对数据进行半对数变换
line_chart.add('收盘价', closes_log)
line_chart.render_to_file('收盘价对数变换折线图(¥).svg')
# s3.1月到11月的月日均值数据
idx_month = dates.index('2017-12-01')
draw_line(months[:idx_month], closes[:idx_month], '收盘价月日均值(¥)',
'月日均值')
# s4.前49周日均值数据,查日历应从2017.1.2-2.17.12.10为49个星期,起始是1月1日
idx_week = dates.index('2017-12-11')
draw_line(weeks[1:idx_week], closes[1:idx_week], '收盘价周日均值(¥)',
'周日均值')
# s5.前49周星期均值
wd = ['Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday',
'Sunday']
# 这里weekdays星期需要排序,按照wd的1-7来,weekdays从1开始
# weekdays返回的就会是[1,2,3,4,5,6,7,1,2,...] 注意函数里面比较的是数字
weekdays_int = [wd.index(w) + 1 for w in weekdays[1:idx_week]]
line_chart_weekday = draw_line(weekdays_int, closes[1:idx_week],
'收盘价星期均值(¥)', '星期均值')
# 另外加x周标签
line_chart_weekday.x_labels = ['周一', '周二', '周三', '周四', '周五',
'周六', '周日']
line_chart_weekday.render_to_file('收盘价星期均值(¥).svg')
# s6.将之前的5个表制成一个网页的仪表图
with open('收盘价DashBoard.html', 'w', encoding='utf8') as html_f:
html_f.write('收盘价DashBoard
'charset="utf-8">\n')
for svg in [
'收盘价折线图(¥).svg', '收盘价对数变换折线图(¥).svg',
'收盘价月日均值(¥).svg', '收盘价周日均值(¥).svg',
'收盘价星期均值(¥).svg'
]:
html_f.write(' \n'.format(svg))
html_f.write('')
__main__()
窝的代码格式还是有点乱, /_\ 。。。。。。
运行效果图