主动学习(Active Learning)系列介绍(二)不确定度采样(Uncertainty Sampling)
本文介绍主动学习Active Learning中的第一种query selection framework—— 不确定度采样Uncertainty Sampling。
文章目录
- 压缩边界 (Pushing the Boundaries)
- 一个例子 (An Example)
- 不确定度的测量 (Measure of Uncertainty)
- 最小可信度 (Least Confidence)
- 间隔法 (Margin)
- 熵方法 (Entropy)
- 不止分类任务 (Beyond Classification)
- 讨论 (Discussion)
- 参考文献
压缩边界 (Pushing the Boundaries)
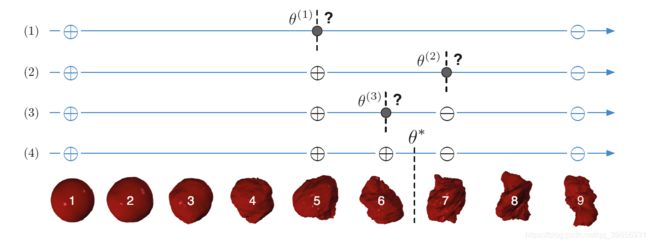
我们回顾一下之前的“探索外星植被问题”:我们想要有效地判断植被是 ⨁ \bigoplus ⨁ 安全的,还是 ⨀ \bigodot ⨀有毒的。我们可以利用有监督学习的方法,如下图所示,将植被按照规则程度排列起来,然后选择safe和noxious中间的那个 θ \theta θ*作为阈值。

然而这种二分查找只能解决这种比较简单的问题,我们想要找出一种更普遍的方法,来处理一些更复杂的问题,找出阈值 θ \theta θ*。
一个比较可以接受的办法是:
让 θ \theta θ*设定为已知的 ⨁ \bigoplus ⨁ 安全的和 ⨀ \bigodot ⨀有毒的植被的 θ \theta θ的中间位置,类似于最大间隔(max-margin)的思想。这样我们的分类模型对距离分隔平面 θ \theta θ较远的示例比较有信心(confident),而对分隔平面较近的示例不是很确定(uncertain)。我们每次就可以选择最不确定的示例,即距离分割平面 θ \theta θ最近的示例作为query instance进行判断。
将以上思想运用在我们的“探索外星植被”问题中,query过程如下所示,利用 ∣ θ − x ∣ |\theta-x| ∣θ−x∣作为实值函数,每次选择 m i n ∣ θ − x ∣ min|\theta-x| min∣θ−x∣作为我们的query instance,这就类似于逐渐压缩我们的边界(pushing the boundaries)。
一个例子 (An Example)
为了展示uncertainty sampling方法如何处理稍微复杂一点的问题,我们设计了如下的实验:
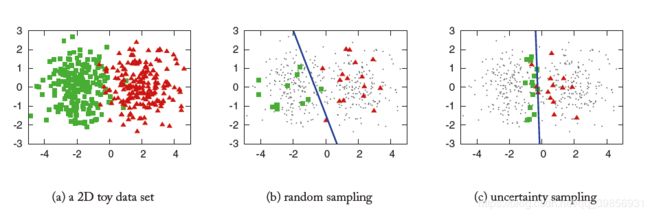
图( a )表示一个随机生成的二维数据集,绿色代表正例,红色代表负例。
图( b )采用随机采用random sampling的方法,随机选择30个样本进行训练,最终生成的模型预测精度为70%。
图( c )采用不确定性采样uncertainty sampling的方法,随机选择30个样本进行训练,最终生成的模型预测精度为90%。
可见uncertainty sampling的策略取得了不错的效果。
该过程算法伪代码如下:

不确定度的测量 (Measure of Uncertainty)
不确定性采样的核心就是不确定度的测量,本文介绍三种测量不确定度的方法,来获得query instance。
主要利用了后验概率 P θ ( Y ∣ x ) P_\theta(Y|x) Pθ(Y∣x)进行相关计算。
最小可信度 (Least Confidence)
此方法选择预测值中可信度最小的示例作为query instance,表达式如下:
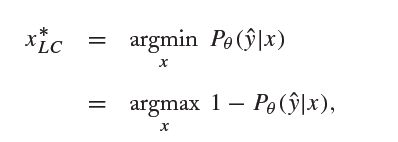
此方法的缺点是只考虑了最优的一种预测效果。
间隔法 (Margin)
此方法表达式如下:
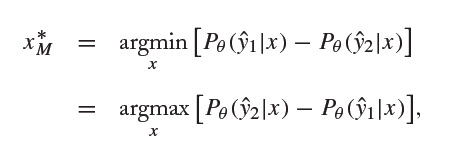
y ^ 1 \hat{y}_1 y^1和 y ^ 2 \hat{y}_2 y^2分别表示示例 x x x所预测的两个最大结果。选择相差最小的,即前两个结果若相差越接近,则此示例越难判断,令其为query instance。
此方法的缺点是只考虑了最优的两种预测结果。
熵方法 (Entropy)
熵是判断一个整理混乱程度的物理量,用于此方法时计算表达式如下:

此方法可以考虑所有的预测结果。
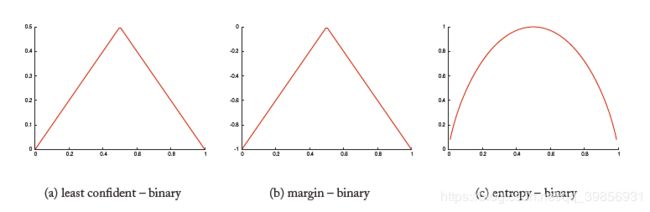
在处理二分类问题时,以上三种测量函数的 P θ ( ⨁ ∣ x ) P_\theta(\bigoplus|x) Pθ(⨁∣x)函数值如下:
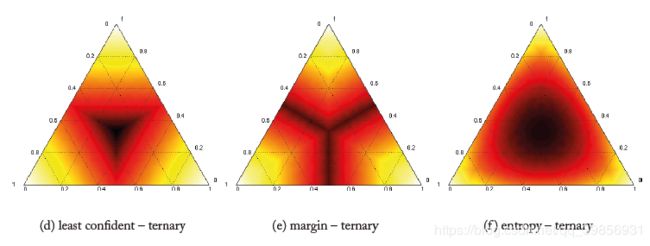
在处理三分类问题时热度图如下:
颜色越深则越不确定uncertain,一般都选取位于中间位置的示例作为query instance。
不止分类任务 (Beyond Classification)
机器学习中不光是分类任务,我们有时还需要训练模型,来预测结构化的输出 —— 一系列的标记label sequences或树形结构trees。
比如 x = < x 1 , . . . , x T > x =

利用uncertainty sampling方法可以有效地减少时间复杂度。
除此之外,uncertainty sampling方法还可以用于回归任务regression。我们通过选择输出方差最大highest output variance的示例作为query instance。下图是回归任务的一个例子:
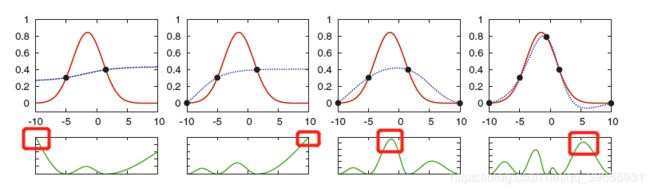
红线为我们的目标函数,虚线为我们目前的模型,绿线为各示例方差大小。
通过选择方差最大的instance,经过四轮训练,我们的模型已经和目标函数相差无几。
讨论 (Discussion)
不确定度采样uncertainty sampling是目前最流行的主动学习策略。事实上,只要模型可以输出一系列的估计值predictions,就可以使用此方法。
以上的讨论都是基于pool-based sampling的思想,其实对于stream-based selective sampling的设定也可以用此方法。
对于每一个示例instance,我们可以用测量函数得出一个uncertainty的值,再设置一个阈值 θ \theta θ判断是否丢弃此instance,这样就形成了一个不确定的区域a region of uncertainty,选择区域内的示例作为query instance即可。此思路大致流程如下:

黑色区域表示正例,白色区域表示负例,黄色区域表示不确定的区域a region of uncertainty
图( a )是目标函数;
图( b )是随机产生的样本点;
图( c )分别是训练20,60,100个instance后产生的模型。
可见黄色面积越来越小,最终训练模型趋近于目标函数。
然而,不确定度采样uncertainty sampling也存在一定的问题:
它计算较为简单,因此考虑的因素比较少;同时不确定度函数仅依据前一状态的假设空间a single hypothesis,因此有时会出错。下面的例子具体表现了这一点:
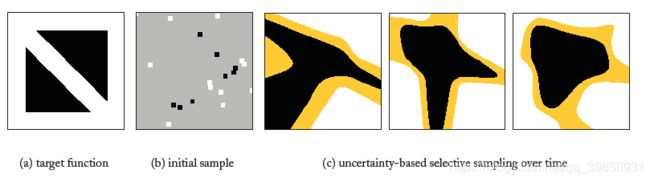
同样,黑色区域表示正例,白色区域表示负例,黄色区域表示不确定的区域a region of uncertainty
图( a )是目标函数;
图( b )是随机产生的样本点(两个三角形中的白色区域处样本较少);
图( c )在训练的过程中,不知道这是两个三角形,根据训练样本以为是一个在中心处的凸多边形,从而导致我们的模型越来越偏离目标函数。
以下介绍的策略会尽量避免以上这些问题。
参考文献
Active Learning, B Settles, 2012.