深度学习入门之PyTorch学习笔记:卷积神经网络
深度学习入门之PyTorch学习笔记
- 绪论
- 1 深度学习介绍
- 2 深度学习框架
- 3 多层全连接网络
- 4 卷积神经网络
- 4.1 主要任务及起源
- 4.2 卷积神经网络的原理和结构
- 4.2.1 卷积层
- 1.概述
- 2.局部连接
- 3.空间排列
- 4.零填充的使用
- 5.步长限制
- 6.参数共享
- 7.总结
- 4.2.2 池化层
- 4.2.3 全连接层
- 4.2.4 卷积神经网络的基本形式
- 1.小滤波器的有效性
- 2.网络的尺寸
- 4.3 PyTorch卷积模块
- 4.3.1 卷积层
- 4.3.2 池化层
- 4.3.3 提取层结构
- 4.3.4 如何提取参数及自定义初始化
- 4.4 卷积神经网络案例分析
- 4.4.1 LeNet
- 4.4.2 AlexNet
- 4.4.3 VGGNet
- 4.4.4 GoogLeNet
- 4.4.5 ResNet
- 4.5 实现MNIST手写数字分类
- 4.6 图像增强的方法
- 4.7 实现cifar10分类
绪论
- 深度学习如今已经称为科技领域最炙手可热的技术,帮助你入门深度学习。
- 本文从机器学习与深度学习的基础理论入手,从零开始学习PyTorch以及如何使用PyTorch搭建模型。
- 学习机器学习中的线性回归、Logistic回归、深度学习的优化方法、多层全连接神经网络、卷积神经网络、循环神经网络、以及生成对抗网络,最后通过实战了解深度学习前沿的研究成果。
- 将理论与代码结合,帮助更好的入门机器学习。
1 深度学习介绍
https://hulin.blog.csdn.net/article/details/107733777
2 深度学习框架
https://hulin.blog.csdn.net/article/details/107746239
3 多层全连接网络
https://hulin.blog.csdn.net/article/details/107757088
4 卷积神经网络
- 图像分类问题是计算机视觉中的一个核心问题,虽然问题描述很简单,却有着很广泛的使用价值,很多独立的计算机视觉任务如目标检测、分割等,都可以简化为图像分类问题。
- 卷积神经网络于1998年由Yann Lecun提出。2012年,Alex凭借卷积神经网络赢得了ImageNet挑战赛,震惊了世界,如今卷积神经网络已经成为计算机视觉领域最具影响力的一部分。
4.1 主要任务及起源
- 人类获取外界信息,主要依靠视觉、听觉、触觉、嗅觉、味觉等感觉器官,其中80%的信息来自于视觉,而且视觉获取的信息也是最丰富、最复杂的。人的生理构造决定了能够看清楚并理解身边的场景,而要让计算机看懂这个世界却是一件非常困难的事情,即使在很多人看来,现在的计算机技术已经足够先进了,但是要达到看懂并自主分析各种复杂信息的程度,还有很长的一段路要走,这也是计算机视觉这门学科要解决的事情。
- 计算机视觉的核心任务之一是图像识别,人类对于图片的识别相当容易,然而机器却面临了很多问题,如视角变换,光照条件,背景干扰,物体变形,正是由于这些问题的干扰,使得计算机在图像识别时候的准确率较低。
- 如何实现一个算法来分类图片呢?人们不可能制定一个规则决定哪张图片属于哪一类,所以要通过学习算法让机器知道如何分类,这就是机器学习的核心。机器学习算法是依赖于数据集的,所以也称为数据驱动算法。
- 在卷积神经网络流行起来之前,图像处理使用的都是一些传统的方法,比如提取图像中的边缘、纹理、线条、边界等特征,依据这些特征再进行下一步处理,这样的处理不仅效率特别低,准确率也不高。随着计算机视觉的快速发展,在某些图像集上机器的识别准确率已经超过了人类,这一切都要归公于卷积神经网络。
4.2 卷积神经网络的原理和结构
- 以下三个观点使得卷积神经网络真正起作用,分别对应着卷积神经网络中的三种思想。
(1)局部性
对于一张图片而言,需要检测图片中的特征来决定图片的类别,通常情况下这些特征都不是由整张图片决定的,而是由一些局部的区域决定的。

(2)相同性
对于不同的图片,如果它们具有相同的特征,这些特征会出现在图片不同的位置,也就是说可以用同样的检测模式去检测不同图片的相同特征,只不过这些特征处于图片中不同的位置,但是特征检测所做的操作几乎一样。两张图片的鸟喙处于不同的位置,但是可以用相同的检测模式去检测。

(3)不变性
对于一张大图片,如果进行下采样,那么图片的性质基本保持不变。

- 卷积神经网络和全连接神经网络是相似的,也是由一些神经元构成。这些神经元中,有需要学习的参数,通过网络输入最后输出结果,通过损失函数来优化网络中的参数。
- 卷积神经网络与全连接神经网络的不同之处在于网络的层结构不同。全连接神经网络由一系列隐藏层构成,每个隐藏层由若干个神经元构成,其中每一个神经元都和前一层的所有神经元相连,但是每一层中的神经元是相互独立的。如下图所示。
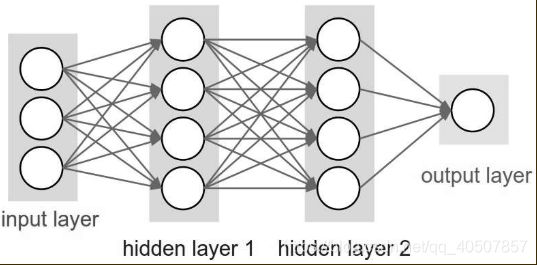
- 全连接神经网络在处理图片上存在诸多问题。比如在MNIST数据集上,图片大小是2828,那么第一个隐藏层的单个神经元的权重数目就是2828=784个,这似乎还不是特别大,但这只是一张小图片,且是灰度图。对于一张较大的图片而言,比如2002003,就会导致权重数目是2002003=120000,如果设置几个隐藏层中神经元数目,就会导致参数增加特别快。其实这样的图片在现实中并不算是大图片,所以全连接神经网络对于处理图片并不是一个好的选择。
- 卷积神经网络的处理过程不同于一般的全连接神经网络,卷积神经网络是一个3D容量的神经元,也就是说神经元是以三个维度来排列的:宽度、高度、深度。比如输入的图片是32323,那么这张图片的宽度就是32,高度也是32,深度是3.
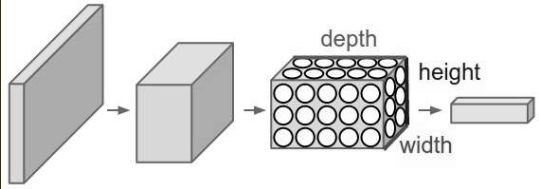
- 卷积神经网络中的主要层结构有三个:卷积层、池化层和全连接层,通过堆叠这些层结构形成了一个完整的卷积神经网络结构。卷积神经网络将原始图片转化为最后的类别得分,其中一些层包含参数,一些层没有包含参数,比如卷积层和全连接层拥有参数,而激活层和池化层不含有参数,这些参数通过梯度下降法来更新,最后使得模型尽可能正确的识别出图片类别。
4.2.1 卷积层
1.概述
- 首先介绍卷积神经网络的参数。这些参数是由一些可学习的滤波器集合构成的,每个滤波器在空间上(宽度和高度)都比较小,但是深度和输入数据的深度保持一致。例如,卷积神经网络的第一层卷积一个典型的滤波器的尺寸可以是553(宽和高都是5),或者333,宽度和高度可以任意定义,但深度必须是3,因为深度要和输入一致,而输入的图片是3通道的。在前向传播的时候,让每个滤波器都在输入数据的宽度和高度上滑动(卷积),然后计算整个滤波器和输入数据任意一处的内积。
- 当滤波器沿着输入数据的宽度和高度滑动时,会生成一个二维的激活图,激活图上的每个空间位置表示了原图片对于该滤波器的反应。直观来看,网络会让滤波器学习到当它看到某些类型的视觉特征的时候就激活,具体的视觉特征可以是边界、颜色、轮廓,甚至可以是网络更高层上的蜂窝状或者车轮状图案。
- 在每个卷积层上,会有一整个集合的滤波器,比如20个,这样就会形成20张二维的、不同的激活图,将这些激活图在深度方向上层叠起来,就形成了卷积层的输出。
- 如果用大脑和生物神经元做比喻,那么输出的3D数据中的每个数据都可以看成是神经元的一个输出,而该神经元只是观察输入数据中的一种特征,并且和空间上左右两边的所有神经元共享参数,因为这些输出都是使用同一个滤波器得到的结果。
2.局部连接
- 在处理图像这样高维度输入的时候,让每个神经元与它那一层中的所有神经元,进行全连接是不现实的。相反,让每个神经元只与输入数据的一个局部区域连接是可行的。这是因为图片特征的局部性,所以只需要通过局部就能提取出相应的特征。
- 与神经元连接的空间大小叫做神经元的感受野(Receptive Field),它的大小是一个人为设置的超参数,这其实就是滤波器的宽和高。在深度方向上,其大小总是和输入的深度相等。最后对待空间维度(宽和高)和深度维度是不同的,连接在空间上是局部的,但是在深度上总是和输入的数据深度保持一致。
- 下图展示了感受野在空间和深度上的大小,左边表示输入数据,中间是感受野,右边每个小圆点表示一个神经元。

- 例如,输入的数据尺寸是32323,如果感受野(滤波器尺寸)是55,卷积层中每个神经元会有输入数据中553区域的权重,一共553=75个权重。感受野的深度大小必须是3,和输入数据保持一致。比如输入数据尺寸是161620,感受野是33,卷积层中每个神经元和输入数据体之间就有3320=180个连接,这里的深度必须是20,和输入数据保持一致。
3.空间排列
- 前面介绍了每个神经元只需要与输入数据的局部区域相连接,但是没有介绍卷积层中神经元的数量和它们的排列方式、输出深度、滑动步长,以及边界填充控制着卷积层的空间排布。
- 首先,卷积层的输出深度是一个超参数,它与使用的滤波器数量一致,每种滤波器所做的就是在输入数据中寻找一种特征。比如说,输入一张原始图片,卷积层输出的深度是20,这说明有20个滤波器对数据进行处理,每种滤波器寻找一种特征进行激活。
- 其次,在滑动滤波器的时候,必须指定步长。比如步长为1,说明滤波器每次移动一个像素点。当步长为2时,滤波器会滑动两个像素点。滑动的操作会使输出的数据在空间上变得更小。
- 最后是边界填充,可以将输入数据用0在边界进行填充,这里将0填充的尺寸作为一个超参数,由一个好处就是,可以控制输出数据在空间上的尺寸,最常用来保证输入和输出在空间上尺寸一致。
4.零填充的使用
- 零填充能够保证输入的数据和输出的数据具有相同的空间尺寸。
5.步长限制
- 在卷积神经网络的结构设计中,需要合理的设置网络的尺寸,使得所有维度都能正常工作。
6.参数共享
- 在卷积层使用参数共享,可以有效减少参数的个数。因为图像特征具有相同性,说明相同的滤波器能够检测出不同位置的相同特征。比如一个卷积层的输出是202032,那么其中神经元的个数就是202032=12800,如果窗口大小是33,而输入的数据深度是10,那么每个神经元就有3310=900个参数,这样合起来就有12800900=11520000个参数,单单一层卷积就有这么多参数,这样的运算速度显然特别慢。
- 一个滤波器能检测出一个空间位置(x1,y1)处的特征,那么也能够有效检测出(x2,y2)位置的特征,所以就可以用相同的滤波器来检测相同的特征。基于这个假设,就能够有效减少参数的个数。比如一共有32个滤波器,这使得输出体的厚度是32,每个滤波器的参数为3310=900,总共的参数就有32*900=28800个,极大减少了参数的个数。
- 由参数共享知道输出体数据在深度切片上所有的权重都使用同一个权重向量,那么卷积层在向前传播的过程中,每个深度切片都可以看成是神经元的权重对输入数据体做卷积,就是把这些3D的权重集合称为滤波器,或者卷积核。
- 参数共享之所以能够有效,是因为一个特征在不同位置的表现是相同的,比如一个滤波器检测到了水平边界这个特征,那么这个特征具有平移不变性,所以在其他位置也能够检测出来。但是有时候这样的假设是没有意义的,特别是当卷积神经网络的输入图像,呈现的是一些明确的中心结构的时候,希望在图片的不同位置学习到不同的特征。例如,人脸识别中,人脸一般位于图片的中心,希望不同的特征能在不同的位置被学习到,比如眼睛特征或者头发特征,正是这些特征在不同的地方,才能够对人脸进行识别。
7.总结
- 总结以下卷积层的性质。
(1)输入数据的尺寸是W1H1D1.
(2)4个超参数,滤波器数量K,滤波器空间尺寸F,滑动步长S,零填充的数量P。
(3)输出数据的尺寸为W2H2D2,D2=K。
(4)由于参数共享,每个滤波器包含的权重数目是FFD1,卷积层一共有FFD1K个权重和K个偏置。
(5)在输出体数据中,第d个深度切片(空间尺寸是W2H2),用d个滤波器和输入数据进行有效卷积运算的结果,再加上第d个偏置。
对于卷积神经网络的超参数,常见的设置是F=3,S=1,P=1,同时这些超参数也有一些约定俗称的惯例和经验。
4.2.2 池化层
- 卷积层是卷积神经网络的核心,通常会在卷积层之间周期性插入一个池化层,其作用是逐渐降低数据体的空间尺寸,这样就能减少网络中的参数数量,减少计算资源耗费,同时也能够有效的控制过拟合。
- 池化层和卷积层一样也有一个空间窗口,通常采用的是取这些窗口中的最大值作为输出结果,然后不断滑动窗口,对输入数据体每一个深度切片单独处理,减少它的空间尺寸。
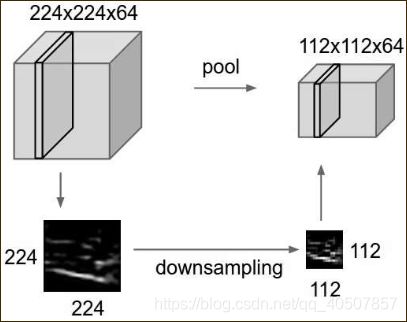
- 池化层之所以有效,是因为之前介绍的图片特征具有不变性,也就是通过下采样不会丢失图片拥有的特征,由于这种特性,可以将图片缩小再进行卷积处理,这样能大大降低卷积运算的时间。
- 最常用的池化层形式是尺寸为2*2的窗口,滑动步长为2,对图像进行下采样,将其中75%的激活信息都丢掉,选择其中最大的保存下来,这其实是因为希望能够更加激活里面数值大的特征,去除一些噪声信息。
- 池化层有一些与卷积层类似的性质。
(1)数据输入体的尺寸是W1H1D1.
(2)有两个需要设置的超参数,空间大小F和滑动步长S。
(3)输出体的尺寸是W2H2D2.
(4)对输入进行固定函数的计算,没有参数引入。
(5)池化层中很少引入零填充。
在实际中,有两种方式:一种是F=3,S=2,这种池化有重叠;另外一种更常用的是F=2,S=2.一般来说应该谨慎使用比较大的池化窗口,以免对网络有破坏性。除了最大值池化之外,还有一些其他的池化函数,比如平均池化,或者L2范数池化。在实际中证明,在卷积层之间引入最大池化的效果是最好的,而平均池化一般放在卷积神经网络的最后一层。
4.2.3 全连接层
- 全连接层和一般的神经网络的结构是一样的,每一个神经元与前一层所有的神经元全部连接,而卷积神经网络只和输入数据中的一个局部区域连接,并且输出的神经元每个深度切片共享参数。
- 一般经过了一系列的卷积层和池化层之后,提取出图片的特征图,比如说特征图的大小是33512,将特征图中的所有神经元变成全连接层的样子,直观上也就是将一个3D的立方体重新排列,变成一个全连接层,里面有33512=4608个神经元,在经过几个隐藏层,最后输出结果。
- 在这个过程中,为了防止过拟合会引入Dropout。最近的研究表明,在进入全连接层之前,使用全局平均池化能够有效的降低过拟合。
4.2.4 卷积神经网络的基本形式
- 卷积神经网络中通常由卷积层、池化层、全连接层这三种层结构所构成,引入激活函数增加模型的非线性,所以卷积神经网络最常见的形式就是将一些卷积层和ReLU层放在一起,有可能在ReLU层前面加上批标准化层,随后是池化层,再不断重复,直到图像在空间上被缩小到一个足够小的尺寸,然后将特征展开,连接几层全连接层,最后输出结果,比如分类评分。
- 一种卷积神经网络的基本结构。

1.小滤波器的有效性
- 一般而言,几个小滤波器卷积层的组合比一个大滤波器卷积层要好,比如层层堆叠了3个33的卷积层,中间含有非线性激活层。在这种排列下面,第一个卷积层中每个神经元对输入数据的感受野是33,第二层卷积层对第一层卷积层的感受野也是33,这样对于输入数据的感受野就是55,同样,第三层卷积层上对第二层卷积层的感受野是33,这样第三层卷积层对于第一层输入数据的感受野就是77.
- 多个卷积层首先与非线性激活层交替的结构,比单一卷积层的结构更能提取出深层的特征。选择小滤波器的卷积组合能够对输入数据表达出更有力的特征,同时使用参数也更少。唯一的不足是反向传播更新参数的时候,中间的卷积层可能会占用更多的内存。
2.网络的尺寸
- 对于卷积神经网络的尺寸设计,没有严格的数学证明,这是根据经验指定出来的规则。
(1)输入层
一般而言,输入层的大小应该能够被2整除很多次,常用的数字包括32,64,96,224.
(2)卷积层
卷积层应该尽可能使用小尺寸的滤波器,比如33或者55,滑动步长取1。还有一点就是需要对输入数据体进行零填充,这样可以有效的保证卷积层不会改变输入数据体的空间尺寸。如果必须要使用更大的滤波器尺寸,比如77,通常用在第一个面对原始图像的卷积层上。
(3)池化层
池化层负责对输入的数据空间维度进行下采样,常用的设置使用22的感受野做最大值池化,滑动步长取2.另外一个不常用的设置是使用3*3的感受野,步长设置为2.一般而言,池化层的感受野大小很小超过2,因为这样会使池化过程过于激烈,造成信息的丢失,这通常会造成算法的性能变差。
(4)零填充
零填充的使用可以让卷积层的输入和输出在空间上的维度保持一致。除此之外,如果不使用零填充,那么数据体的尺寸就会略微减少,在不断进行卷积的过程中,图像边缘信息会过快的损失掉。
4.3 PyTorch卷积模块
- PyTorch作为一个深度学习库,卷积神经网络是其中最为基础的一个模块,卷积神经网络中所有的层结构都可以通过nn这个包来调用。
4.3.1 卷积层
nn.Conv2d()就是PyTorch中的卷积模块,常用的参数有5个,分别是in_channels,out_channels,kernel_size,stride,padding,还有参数dilation,groups,bias等in_channels对应的是输入数据体的深度;out_channels表示输出数据体的深度;kernel_size表示滤波器(卷积核)的大小,可以使用一个数字来表示高和宽相同的卷积核,比如kernel_size=3, 也可以使用不同的数字来表示高和宽不同的卷积层,比如kernel_size=(3,2);stride表示滑动的步长;padding=0表示四周不进行零填充,而padding=1表示四周进行1个像素点的零填充;bias是一个布尔值,默认bias=True表示使用偏置;groups表示输出数据体深度上和输入数据体深度上的联系,默认groups=1,也就是所有的输入和输出是相关联的;如果groups=2,表示输入的深度被分割成两份,输出的深度也被分割成两份,它们之间分别对应起来,所以要求输入和输出都要被groups整除;dilation表示卷积对于输入数据体的空间间隔,默认dilation=1
4.3.2 池化层
- nn.MaxPool2d()表示网络中最大值池化,其中参数有kernel_size, strid, padding, dilation, return_indices, ceil_mode。
- kernel_size, stride, padding, dilation与卷积层参数的含义相同。
return_indices表示是否返回最大值所处的下标,默认return_indices=False;一般不会设置这些参数。nn.AvgPool2d()表示均值池化,里面的参数和nn.MaxPool2d()类似,但多一个参数count_include_pad,这个参数表示计算均值的时候是否包含零填充,默认为True。- 一般使用较多的就是nn.MaxPool2d()和nn.AvgPool2d(), 另外PyTorch还提供了一些别的池化层,如nn.LPPool2d(),nn.AdaptiveMaxPool2d()等不常用的池化层。
- 一个简单的多层卷积神经网络
import torch.nn as nn
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
layer1 = nn.Sequential()
layer1.add_module('conv1', nn.Conv2d(3, 32, 3, 1, padding=1))
layer1.add_module('relu1', nn.ReLU(True))
layer1.add_module('pool1', nn.MaxPool2d(2, 2))
self.layer1 = layer1
layer2 = nn.Sequential()
layer2.add_module('conv2', nn.Conv2d(32, 64, 3, 1, padding=1))
layer2.add_module('relu2', nn.ReLU(True))
layer2.add_module('pool2', nn.MaxPool2d(2, 2))
self.layer2 = layer2
layer3 = nn.Sequential()
layer3.add_module('conv3', nn.Conv2d(64, 128, 3, 1, padding=1))
layer3.add_module('relu3', nn.ReLU(True))
layer3.add_module('pool3', nn.MaxPool2d(2, 2))
self.layer3 = layer3
layer4 = nn.Sequential()
layer4.add_module('fc1', nn.Linear(2048, 512))
layer4.add_module('fc_relu1', nn.ReLU(True))
layer4.add_module('fc2', nn.Linear(512, 64))
layer4.add_module('fc_relu2', nn.ReLU(True))
layer4.add_module('fc3', nn.Linear(64, 10))
self.layer4 = layer4
def forward(self, x):
conv1 = self.layer1(x)
conv2 = self.layer2(conv1)
conv3 = self.layer3(conv2)
fc_input = conv3.view(conv3.size(0), -1)
fc_out = self.layer4(fc_input)
return fc_out
model = SimpleCNN()
print(model)
- 在上面的定义中,将卷积层、激活层、池化层,组合在一起构成了一个层结构,定义了3个这样的层结构,最后定义了全连接层,输出10.
- 通过print(model)显示网络中定义了哪些层结构, 这些层结构
SimpleCNN(
(layer1): Sequential(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu1): ReLU(inplace)
(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(layer2): Sequential(
(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu2): ReLU(inplace)
(pool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(layer3): Sequential(
(conv3): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu3): ReLU(inplace)
(pool3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(layer4): Sequential(
(fc1): Linear(in_features=2048, out_features=512, bias=True)
(fc_relu1): ReLU(inplace)
(fc2): Linear(in_features=512, out_features=64, bias=True)
(fc_relu2): ReLU(inplace)
(fc3): Linear(in_features=64, out_features=10, bias=True)
)
)
4.3.3 提取层结构
- 对于一个给定的模型,如果不想要模型中所有的层结构,只希望能够提取网络中的某一层或者几层,应该如何实现?
- 首先看nn.Module的几个重要属性。
- 第一个是children(), 这个会返回下一级模块的迭代器,比如上面这个模型,智慧返回self.layer1, self.layer2, self.layer3,self.layer4上的迭代器,不会返回它们内部的东西。
- 第二个是modules()会返回模型中所有模块的迭代器,即它能够访问到最内层,比如self.layer1.conv1这个模块。
- 还有一个与前两个相对应的是named_children()属性以及named_modules(), 这两个不仅会返回模块的迭代器,还会返回网络层的名字。
- 下面来提取网络中需要的层。
- 如果希望能提取出前面两层,可以通过下面的方法实现。
model = SimpleCNN()
new_model = nn.Sequential(*list(model.children())[:2])
print(new_model)
Sequential(
(0): Sequential(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu1): ReLU(inplace)
(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(1): Sequential(
(conv2): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(relu2): ReLU(inplace)
(pool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
)
- 如果希望提取出模型中所有的卷积层,可以通过下面的方法实现.使用isinstance()可以判断这个模块是不是所需要的类型实例,这样就提取出了所有的卷积模块。
conv_model = nn.Sequential()
for layer in model.named_modules():
if isinstance(layer[1], nn.Conv2d):
conv_model.add_module(layer[0], layer[1])
4.3.4 如何提取参数及自定义初始化
- 有时候提取出的层结构并不够,还需要对里面的参数进行初始化,那么如何提取网络中的参数并初始化呢?
- 首先nn.Module里面有两个特别重要的关于参数的属性,分别是named_parameters()和parameters(), named_parameters()给出网络层的名字和参数的迭代器, parameters()会给出一个网络的全部参数的迭代器。
model = SimpleCNN()
for param in model.named_parameters():
print(param[0])
layer1.conv1.weight
layer1.conv1.bias
layer2.conv2.weight
layer2.conv2.bias
layer3.conv3.weight
layer3.conv3.bias
layer4.fc1.weight
layer4.fc1.bias
layer4.fc2.weight
layer4.fc2.bias
layer4.fc3.weight
layer4.fc3.bias
- 如何对权重做初始化呢?因为权重是一个Variable,所以只需要取出其中的data属性,对其进行所需要的处理即可。
model = SimpleCNN()
for m in model.modules():
if isinstance(m, nn.Conv2d):
init.normal_(m.weight.data)
init.xavier_normal_(m.weight.data)
init.kaiming_normal_(m.weight.data)
m.bias.data.fill_(0)
elif isinstance(m, nn.Linear):
m.weight.data.normal_()
4.4 卷积神经网络案例分析
4.4.1 LeNet
- LeNet是整个卷积神经网络的开山之作,1998年由LeCun提出,它的结构特别简单。
- 整个网络结构特别清晰,一共7层,其中2层卷积和2层池化层交替出现,最后输出3层全连接层得到整体的结果。

- 网络的层数很浅,也没有添加激活层
import torch.nn as nn
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
layer1 = nn.Sequential()
layer1.add_module('conv1', nn.Conv2d(1, 6, 3, padding=1))
layer1.add_module('pool1', nn.MaxPool2d(2, 2))
self.layer1 = layer1
layer2 = nn.Sequential()
layer2.add_module('conv2', nn.Conv2d(6, 16, 5))
layer2.add_module('pool2', nn.MaxPool2d(2, 2))
self.layer2 = layer2
layer3 = nn.Sequential()
layer3.add_module('fc1', nn.Linear(400, 120))
layer3.add_module('fc2', nn.Linear(120, 84))
layer3.add_module('fc3', nn.Linear(84, 10))
self.layer3 = layer3
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = x.view(x.size(0), -1)
x = self.layer3(x)
return x
4.4.2 AlexNet
-
AlexNet在2012年的ImageNet竞赛上大放异彩,以领先第二名10%的准确率夺得冠军,并成功展示了深度学习的威力。
-
当时GPU计算能力不强,而AlexNet比较复杂,所以使用两个GPU并行计算,现在完全可以用一个GPU代替。
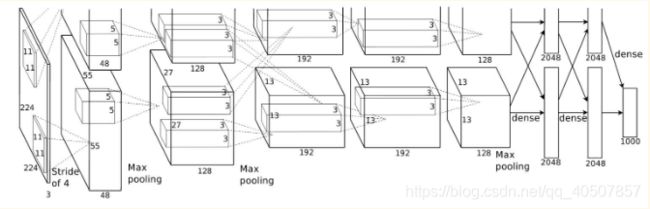
-
AlexNet相对于LeNet层数更深,同时第一次引入了激活层ReLU,在全连接层引入了Dropout层防止过拟合。
import torch.nn as nn
class AlexNet(nn.Module):
def __init__(self, num_classes):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes)
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256 * 6 * 6)
x = self.classifier(x)
return x
4.4.3 VGGNet
- VGGNet是ImageNet竞赛2014年的亚军,总结起来就是它使用了更小的滤波器,同时使用了更深的结构,AlexNet只有8层网络,而VGGNet有16-19层网络;AlexNet使用了1111的大滤波器,而VGGNet只使用了33的卷积滤波器和2*2的大池化层。
- VGGNet之所以使用很多小的滤波器,是因为层叠很多小的滤波器的感受野和一个大滤波器的感受野是相同的,还能减少参数,同时有更深的网络结构。
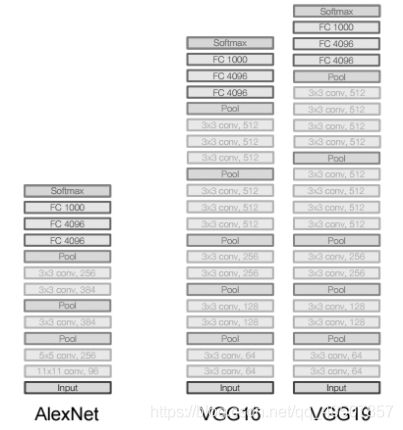
- VGG只是对网络层进行不断的堆叠,并没有进行太多的创新,而增加深度确实可以一定程度改善模型效果。
import torch.nn as nn
class VGGNet(nn.Module):
def __init__(self, num_classes):
super(VGGNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.ReLU(True),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.ReLU(True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.ReLU(True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
4.4.4 GoogLeNet
-
GoogLeNet也叫InceptionNet,是ImageNet竞赛2014年的冠军,采用了一种很有效的Inception模块,没有全连接层。
-
GoogLeNet采取了比VGGNet更深的网络结构,一共有22层,但是它的参数却比AlexNet少了12倍,同时有很高的计算效率。

-
Inception模块设计了一个全局的网络拓扑结构,然后将这些模块堆叠在一起形成一个抽象层网络结构。具体就是运用几个并行的滤波器对输入进行卷积和池化,这些滤波器有不同的感受野,最后将输出的结果按深度拼接在一起形成输出层。
-
首先定义一个最基础的卷积模块,然后根据这个模块定义了11,33,5*5的模块和一个池化层,最后使用torch.cat()将它们按深度拼接起来,得到输出结果。
import torch.nn as nn
import torch
from pandas.util._decorators import F
class BasicConv2d(nn.Module):
def __init__(self, in_channels, out_channels, **kwargs):
super(BasicConv2d, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return F.relu(x, inplace=True)
class Inception(nn.Module):
def __init__(self, in_channels, pool_features):
super(Inception, self).__init__()
self.branch1x1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch5x5_1 = BasicConv2d(in_channels, 48, kernel_size=1)
self.branch5x5_2 = BasicConv2d(48, 64, kernel_size=5, padding=2)
self.branch3x3db1_1 = BasicConv2d(in_channels, 64, kernel_size=1)
self.branch3x3db1_2 = BasicConv2d(64, 96, kernel_size=3, padding=1)
self.branch3x3db1_3 = BasicConv2d(96, 96, kernel_size=3, padding=1)
self.branch_pool = BasicConv2d(in_channels, pool_features, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3db1 = self.branch3x3db1_1(x)
branch3x3db1 = self.branch3x3db1_2(branch3x3db1)
branch3x3db1 = self.branch3x3db1_3(branch3x3db1)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = (branch1x1, branch5x5, branch3x3db1, branch_pool)
return torch.cat(outputs, 1)
4.4.5 ResNet
- ResNet是2015年ImageNet竞赛的冠军,由微软研究院提出,通过残差模块能够成功训练高达152层的神经网络。
- ResNet最初的设计灵感来自于这个问题:在不断加深神经网络的时候,会出现一个Degradation,即准确率会先上升然后达到饱和,再持续增加深度则会导致模型准确率下降。
- 这并不是过拟合的问题,因为不仅在验证集上误差增加,训练集本身误差也在增加。假设一个比较浅的网络达到了饱和的准确率,那么在后面加上恒等映射层,误差不会增加,也就是说更深的模型不会使模型效果下降。
- 这里提到的使用恒等映射直接将前一层输出传到后面的思想,就是ResNet的灵感来源。假设某个神经网络的输入是x,期望输出是
H(x), 如果直接把输入x传到输出作为初始结果,那么此时需要学习的目标就是F(x)=H(x)-x, 也就是残差模块。 - ResNet的残差学习单元相当于将学习目标改变了,不再是学习一个完整的输出H(x), 而是学习输出和输入差别H(x)-x, 即残差。

import torch.nn as nn
def conv3x3(in_planes, out_planes, stride=1):
"""
3x3 convolution with padding
:param in_planes:
:param out_planes:
:param stride:
:return:
"""
return nn.Conv2d(
in_planes,
out_planes,
kernel_size=3,
stride=stride,
padding=1,
bias=False
)
class BasicBlock(nn.Module):
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
4.5 实现MNIST手写数字分类
- 这个简单的卷积神经网络里面有4层卷积,2层最大池化,卷积之后使用批标准化加快收敛速度,使用ReLU激活函数增加非线性,最后使用全连接层输出分类得分。
- 结论:通过增加网络深度和复杂化网络结构,提高网络的准确率是可行的。
from torch import nn
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=3),
nn.BatchNorm2d(16),
nn.ReLU(inplace=True)
)
self.layer2 = nn.Sequential(
nn.Conv2d(16, 32, kernel_size=3),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.layer3 = nn.Sequential(
nn.Conv2d(32, 64, kernel_size=3),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
self.layer4 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2)
)
self.fc = nn.Sequential(
nn.Linear(128 * 4 * 4, 1024),
nn.ReLU(inplace=True),
nn.Linear(1024, 128),
nn.ReLU(inplace=True),
nn.Linear(128, 10)
)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
4.6 图像增强的方法
- 一直以来,图像识别这一计算机视觉的核心问题都面临着很多挑战,同一个物体在不同情况下都会得出不同的结论。
- 对于一张照片,人类看到的是一些物体,对于计算机而言,看到的是一些像素点。
- 如果拍摄照片的照相机位置发生了改变,那么拍摄的图片对于我们而言,变化很小,但是对于计算机而言,图片的像素变化是很大的。
- 拍摄时的光照条件也是很重要的一个影响因素:光照太弱,照片里的物体和背景融为一体,它们的像素点就会很接近,计算机就无法正确识别出物体。
- 物体本身的变形也会对计算机识别造成障碍,比如一只猫是趴着的,计算机能够识别它,但是如果猫换一个姿势,变成躺着的状态,计算机就无法识别了。
- 物体本身会隐藏在一些遮蔽物,这样物体只呈现局部的信息,计算也难以识别。
torchvision.transforms包括所有图像增强的方法。scale对图片的尺寸进行缩小和放大CenterCrop对图像正中心进行给定大小的剪裁RandomCrop对图片进行给定大小的随机剪裁RandomHorizaontalFlip对图片进行概率为0.5的随机水平反转RandomSizedCrop首先对图片进行随机尺寸的裁剪,然后对裁剪的图片进行一个随机比例的缩放,最后将图片变成给定大小,在InceptionNet中较流行。pad对图片进行边界零填充
4.7 实现cifar10分类
- cifar10数据集有60000张图片,每张图片的大小都是32*32的三通道的彩色图,一共是10种类别,每种类别有6000张图片。
- 首先进行图像增强。只对训练集进行图片增强,提高泛化能力,对于测试集,仅对其中心化,不做其他的图像增强。
from torchvision import transforms
train_transform = transforms.Compose([
transforms.Scale(40),
transforms.RandomHorizontalFlip(),
transforms.RandomCrop(32),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
- 定义ResNet的基本模块。
def conv3x3(in_channels, out_channels, stride=1):
return nn.Conv2d(
in_channels,
out_channels,
kernel_size=3,
stride=stride,
padding=1,
bias=False
)
# Residual Block
class ResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(ResidualBlock, self).__init__()
self.conv1 = conv3x3(in_channels, out_channels, stride)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(out_channels, out_channels)
self.bn2 = nn.BatchNorm2d(out_channels)
self.downsample = downsample
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
- 先定义残差模块,再将残差模块拼接起来,注意其中维度变化。
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=10):
super(ResNet, self).__init__()
self.in_channels = 16
self.conv = conv3x3(3, 16)
self.bn = nn.BatchNorm2d(16)
self.relu = nn.ReLU(inplace=True)
self.layer1 = self.make_layer(block, 16, layers[0])
self.layer2 = self.make_layer(block, 32, layers[0], 2)
self.layer3 = self.make_layer(block, 64, layers[1], 2)
self.avg_pool = nn.AvgPool2d(8)
self.fc = nn.Linear(64, num_classes)
def make_layer(self, block, out_channels, blocks, stride=1):
downsample = None
if (stride != 1) or (self.in_channels != out_channels):
downsample = nn.Sequential(
conv3x3(self.in_channels, out_channels, stride=stride),
nn.BatchNorm2d(out_channels)
)
layers = []
layers.append(
block(self.in_channels, out_channels, stride, downsample)
)
self.in_channels = out_channels
for i in range(1, blocks):
layers.append(block(out_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv(x)
out = self.bn(out)
out = self.relu(out)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.avg_pool(out)
out = out.view(out.siza(0), -1)
out = self.fc(out)
return out