登入验证码的识别
放在前面
- 无深度学习
- 无机器学习
在以前的博客中,教务系统一键查询成绩我在登入这一步,使用的腾讯文字识别的api虽然说免费用3000次,但总觉得受限于人,今天捣鼓了一天,终于用自己的方法实现了验证码识别,虽然很简陋,但是终归是实现了,哈哈.

在昨天刚了解完支持向量机,当时就想到了用支持向量机来分类图片.昨天睡觉的时候就激动的不行,想要实现,心痒痒的.然后今天一早起来就开始折腾了.现在实现了,不过没用支持向量机,用的最简单的方法…
首先分析一下识别的步骤叭:
- 降噪.
- 二值化/灰度化图片方便处理
- 切割验证码
- 训练
- 预测
这是,一开始的设想,后面有些不同,写完再总结一下.
首先降噪,其实这个验证码的降噪还算容易处理的,肉眼就可以看到干扰线只有一种颜色.将这个颜色转成背景色就好.当然这样子会导致字母有些地方缺失颜色了.所以如果线太粗遮住的地方太多就没办法了.
第二次补充,第一次写的时候都忘了当初的改进了.干扰线并不全是直接用背景色代替,而是遍历以这个点为中心的九宫格,红色多的话久换红色,背景色多就换背景色
这是在ps中的放大图.

降噪后

然后因为图片是彩色的,RGB三通道颜色,比较难处理,那就转化一下,理论上应该灰度和二值都可以,这里使用的是灰度.(一开始想用的二值化,后面还是用了灰度化,如果中间看到我代码把灰度化叫成了二值化,不要混乱.参数搞错了)

然后就是分割,分割这一步,我是这么分割的,搜索有值点的列数(不全是空白的列数),然后如果中间有空列,那就以空白列隔开.
比如,搜索到的列数是(6,7,8,9,10,12,13,14,15)那么6-10就是一个字母,12-15的一个字母.
当然有缺陷…这个应该还是可以有改善的方法的,暂时没想出来…

分割后的数据

就到了训练这一步…然后我发现,训练个锤子…都没标签,我自己一个一个打不得累死.除了这点以外…这些分割的图片的大小都不一样,不知道能不能用于训练(我想到的解决方法是填充0,让大家都变成同样大小,这个理论上应该是可以解决的?)主要就是训练标签没法解决,然后我就放弃了,用支持向量机试了试mnist训练集(早上的文章)
不过当然没有完全放弃,不然也就没这个博客了.主要舍不得前面的工作白白浪费.慢慢的想到了最简单的方法.
分析:这个验证码大小字体完全是一模一样的,来来去去也就那么多,那我只要把所有的都分割出来,然后识别的时候,只要对比大小,大小相同,对比像素点的值,对比出来最像的就是那个值了…虽然很朴素,但是对付这个简单验证码,我觉得完全ok.

标准码的矩阵,可以看出来是个Z
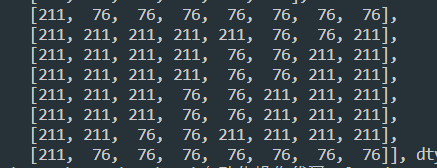
然后我爬了300来张验证码.找到上面的标准码(我称为).爬了300次都没碰到Oo0Ili1jJ我觉得这几个是不是人为设置了出现频率低,因为人眼也难识别这几个玩意儿(比如说,第四第五个,哪个是i的大写,哪个是L的小写)
最后,对于一张新的预测码通过以下步骤进行识别:
- 除噪
- 灰度化
- 分割
- 对比标准码
- 输出结果




可以看到效果还是不错的,只要不碰到粘连的情况,以及干扰线遮住了字母的上或者下线
可改进之处:
1.粘连,可以想想怎么分开
2.字母的下线其实都是同一个地方,可以改成固定值,能避免干扰线遮住下线的情况
识别代码
import numpy as np
import os
from PIL import Image
#对照标准码
def duibi(X, img_size, x_):
max_du = 0
index = -1
for i in range(len(img_size)):
x_length = img_size[i][0]
x_width = img_size[i][1]
x_array = np.array(x_)
if x_.size == img_size[i]:
temp = 0
for j in range(x_width):
for k in range(x_length):
if x_array[j][k] == X[i][1][j][k]:
temp += 1
if temp > max_du:
max_du = temp
index = X[i][0]
return index
#除噪+灰度化
def chuzao(img):
color=[(255,0,0),(211,211,211)]#红色和背景色的rgb值
width = img.size[0] #宽度
height = img.size[1] #高度
for i in range(0, width): # 遍历所有长度的点
for j in range(0, height): # 遍历所有宽度的点
data = (img.getpixel((i, j))) # 打印该图片的所有点
# print (data)#打印每个像素点的颜色RGBA的值(r,g,b,alpha)
# print (data[0])#打印RGBA的r值
if (data[0] == 105 and data[1] == 105 and data[2] == 105):
count = [0, 0]
for t in range(3):
for q in range(3):
if(i+t-1 >= 0 and j+q-1 >= 0 and i+t-1 < width and j+q-1 < height):
temp = img.getpixel((i+t-1, j+q-1))
if(temp[0] == 255):
count[0] += 1
else:
count[1] += 1
img.putpixel((i, j), color[count.index(max(count))])
# img.save(path, 'png')
img = img.convert('L')
return img
#分割图像,返回分割的列表.
def fenge(img):
res = []
x1 = set()
x2 = []
width = img.size[0]
height = img.size[1]
for i in range(width):
for j in range(height):
data = img.getpixel((i, j))
if(data == 76):
x1.add(i)
x1 = list(x1)
# print(x1)
# print([i for i in range(len(x1))])
flag = 0
for i in range(len(x1)):
if(flag != 0):
flag -= 1
continue
for j in range(i, len(x1)):
if j == len(x1) - 1:
x2.append([x1[i], x1[j]])
flag = len(x1)
break
if(x1[j]-x1[i] != j-i):
x2.append([x1[i], x1[j-1]])
flag = j-i-1
break
# print(x2)
# temp = img.crop((x2[0][0],0,x2[0][1],0))
for i in range(len(x2)):
temp = img.crop((x2[i][0]-1, 0, x2[i][1]+1, height))
ytemp = set()
for j in range(temp.size[1]):
for k in range(temp.size[0]):
if temp.getpixel((k, j)) == 76:
ytemp.add(j)
break
ytemp = list(ytemp)
yreal = []
yreal.append(ytemp[0])
yreal.append(ytemp[-1])
temp = temp.crop((0, yreal[0]-1, temp.size[0], yreal[1]+1))
# temp.save('{}.png'.format(str(i).rjust(4, '0')), 'png')
res.append(temp)
return res
if __name__ == "__main__":
inpath = r'C:\Users\83599\Desktop\自动化操作代码\数据分类2'
paths = os.listdir(inpath)
img_size = []
X = []
for path in paths:
img = Image.open(os.path.join(inpath, path))
X.append([path[0], np.array(img)])
img_size.append(img.size)
# x_ = Image.open('C:\\Users\\83599\\Desktop\\自动化操作代码\\fenge\\0001.png')
# print(img_size)
# print(x_.size)
# print(duibi(X, img_size, x_))
img = Image.open('C:\\Users\\83599\\Desktop\\自动化操作代码\\data\\082.png')
img = chuzao(img)
img = fenge(img)
for i in range(len(img)):
print(duibi(X, img_size, img[i]))
爬取验证码的代码
说明几点
- 没用之前的screenshot因为…截图的分辨率很低很低…如果用那个,可能图像处理要多几步,好像叫锐化?
- 抄了win32api的用法,其实就是右键保存图片,没别的方法保存图片了…有点难受的…具体的搜索selenium右键保存就好
import selenium
from selenium import webdriver
import pickle
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
import requests
import time
import win32api
import win32con
VK_CODE ={'enter':0x0D, 'down_arrow':0x28}
#键盘键按下
def keyDown(keyName):
win32api.keybd_event(VK_CODE[keyName], 0, 0, 0)
#键盘键抬起
def keyUp(keyName):
win32api.keybd_event(VK_CODE[keyName], 0, win32con.KEYEVENTF_KEYUP, 0)
driver = webdriver.Chrome()
driver.get("") # 地址栏里输入网址
driver.implicitly_wait(2) # 设置隐式等待时间
driver.find_element_by_id('user_login').send_keys("")#账号
driver.find_element_by_id('user_password').send_keys('')#密码
driver.find_element_by_name('commit').click()
for i in range(1):
driver.get("") # 地址栏里输入网址
img = driver.find_element_by_xpath('//*[@id="Table16"]/tbody/tr[9]/td[3]/img')
ActionChains(driver).context_click(img).perform()#右键,点击
win32api.keybd_event(86, 0, 0, 0)
win32api.keybd_event(86, 0, win32con.KEYEVENTF_KEYUP, 0)
time.sleep(1)
#按enter
# input()
keyDown("enter")
keyUp("enter")
time.sleep(1)
感慨:
- 今天可以算是征服了这个验证码hh,之前一直觉得这么简单的验证码用深度学习的api有点耻辱.今天用简单暴力的方法解决了,有点爽.
- 不得不说深度学习的api强的…screenshot这么糊的图片都能识别,而且图片还很小…