语义分割 | segnet 制作自己的数据,如何训练,如何测试,如何评价
本博文介绍如何手把手制作自己的数据集,并使用SegNet网络进行语义分割,如何训练,如何测试自己的分割模型。
----------------------------------------------------------------------------------------------------------------------------------------------------------
感谢:
1.源码参考cudnn5版本的caffe-segnet,https://github.com/TimoSaemann/caffe-segnet-cudnn5
2.作者的官方指导文档:http://mi.eng.cam.ac.uk/projects/segnet/tutorial.html
3.一份使用指导:https://github.com/TqDavid/SegNet-Tutorial/tree/master/CamVid
4.如果想测试SegNet的效果,这里有官方的在线测试demo: http://mi.eng.cam.ac.uk/projects/segnet/#demo
5.一份segnet的预训练model
https://github.com/alexgkendall/SegNet-Tutorial/blob/master/Example_Models/segnet_model_zoo.md,以及相对应的
| segnet_basic_inference.prototxt |
| segnet_basic_solver.prototxt |
| segnet_basic_train.prototxt |
6.参考了该博主的文章https://blog.csdn.net/caicai2526/article/details/77170223
7.以及该博主的文章https://blog.csdn.net/hjxu2016/article/details/77994925
8.对于已有mask和image,需要resize,可参考https://blog.csdn.net/u013249853/article/details/79827469
--------------------------------------------------------------------------------------------------------------------------------------------------------------
言归正传,开始正题。
下载上述caffe-segnet-cudnn5版本的代码,其路径后文称之为caffe_root,以下的操作都在该caffe_root目录下进行。
整体目录包含如下文件(夹):
一、制作自己数据集
SegNet网络需要两个输入,一个是原始图像,三通道的;一个是mask label,也就是待分割目标的标签,mask要求是单通道8位灰度图,格式是uint8, 像素0表示背景,像素1表示目标的位置。 下面分别准备这两样东西。
1. 原始图像就是你自己的照片了,注意一下:如果你不更改SegNet中参数,可以先保持与原作者的图像尺寸一致,后面可以根据自己的情况在更改,一般上采样2x,这里采用与原作者相同的图像尺寸,(360, 480)彩色图片,如果不是这样,建议resize一下,博主自己的图片是灰度的,resize前有一个转成rgb的过程,python代码函数;
# testdir为自己数据集路径,楼主的图是灰度图,所以有一个转换成rgb的过程,然后保存。
def resize_image_batch():
file_list = os.listdir(testdir)
for item in file_list:
#print(traindir + item)
imname = testdir + item
im = cv2.imread(imname, 0)
im = cv2.resize(im, (480, 360))
im_RGB = cv2.cvtColor(im, cv2.COLOR_GRAY2RGB)
print(im.shape)
print(im_RGB.shape)
#print(im)
print("============================")
#print(im_RGB[:,:,0])
#print(im_RGB[:,:,1])
#print(im_RGB[:,:,2])
print(im.dtype)
print(im_RGB.dtype)
cv2.imwrite('zht_test_use/'+ item, im_RGB)
#print("success!")2.准备mask。
首先,博主的mask来源是用labelme 得到的。labelme的使用方法,这里不再赘述。简言之,对于每一张图,我们可以得到其
json标注文件, 再通过,labelme_json_to_dataset命令,可以得到最终我们需要的label mask,我们所需的是文件夹下的label.png。
labelme_json_to_dataset批量生成数据集的shell脚本如下;
for item in $(find ./huaweishouji_20170720_train_360x480_try -iname "*.json");
do
echo $item;
labelme_json_to_dataset $item;
done接下来将lable.png转换成uint8,背景像素是0,目标像素是1的mask..convert_to_mask 代码如下:
def convert_to_mask():
file_list = os.listdir(traindir)
for item in file_list:
item_list = os.listdir(traindir + item)
#print("len(item) : ", len(item_list))
for atom in item_list:
if atom == "label.png":
np.set_printoptions(threshold='nan')
imname = traindir + item + "/" + atom
#print(imname)
im = io.imread(imname, 1)
print(imname)
#print(im[:, :])
print(im.shape)
print(im.dtype)
print("-------------after-----------------")
img = (im * 255).astype(np.uint8)
_, im_th= cv2.threshold(img, 0.0000000000000001, 1, cv2.THRESH_BINARY)
#print(img.shape)
print(im_th.shape)
print(im_th.dtype)
#print(im_th[ :, :])
print(item[:-5] + ".png")
cv2.imwrite(train_write_dir + item[:-5] + '.png', im_th )
#print(im[:,:,0])
#print(im[:,:,1])
#print(im[:,:,2])
#im_RGB = cv2.cvtColor(im, cv2.COLOR_GRAY2RGB)
#print(traindir + item)
#imname = traindir + item
#im = cv2.imread(imname, 0)
#im = cv2.resize(im, (480, 360))
#im_RGB = cv2.cvtColor(im, cv2.COLOR_GRAY2RGB)
#print(im.shape)
#print(im_RGB.shape)
#print(im)
#print("============================")
#print(im_RGB[:,:,0])
#print(im_RGB[:,:,1])
#print(im_RGB[:,:,2])
#print(im.dtype)
#print(im_RGB.dtype)
#cv2.imwrite('huaweishouji_20170720_test_360x480/'+ item, im_RGB)
def check_mask():
file_list = os.listdir(train_write_dir)
for item in file_list:
np.set_printoptions(threshold='nan')
#item_list = os.listdir(test_write_dir)
imname = train_write_dir + item
#print("len(item) : ", len(item_list))
print(item)check_mask()是检验函数。验证背景是0,目标是1,且为uint8编码。
将上述原始图像和mask,划分出训练集和测试集,分别放置在caffe_root/data/mydata/train和test下。mydata/下的结构是如图,
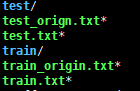 ,其中train/和test/ 结构如下:
,其中train/和test/ 结构如下:![]() ,image/和mask/下分别是上面得到的图像和mask文件。注意图像和mask名称保持一致。
,image/和mask/下分别是上面得到的图像和mask文件。注意图像和mask名称保持一致。
3.准备上面mydata/下的train.txt和test.txt,然后我们需要制作一个txt的列表,左边是原图的根目录路径,右边是mask图的根目录路径,中间以空格隔开,一定要注意,mask的路径和原图的路径一定要对,列表形式如下:
/home/hjxu/caffe_examples/segnet_xu/data/test/image/8900_11800.tiff /home/hjxu/caffe_examples/segnet_xu/data/test/mask/8500_10200_ConfidenceMap.png
/home/hjxu/caffe_examples/segnet_xu/data/test/image/10100_9800.tiff /home/hjxu/caffe_examples/segnet_xu/data/test/mask/8900_11800_ConfidenceMap.png
/home/hjxu/caffe_examples/segnet_xu/data/test/image/8900_9000.tiff /home/hjxu/caffe_examples/segnet_xu/data/test/mask/9300_10200_ConfidenceMap.png
/home/hjxu/caffe_examples/segnet_xu/data/test/image/8900_10200.tiff /home/hjxu/caffe_examples/segnet_xu/data/test/mask/8900_9000_ConfidenceMap.png
具体的shell脚本
#!/usr/bin/env sh
DATA_train=/home/ccf/CCF/Cell_segnet/data/data_train_enhancement/train/image
MASK_train=/home/ccf/CCF/Cell_segnet/data/data_train_enhancement/train/mask
DATA_test=/home/ccf/CCF/Cell_segnet/data/data_train_enhancement/test/image
MASK_test=/home/ccf/CCF/Cell_segnet/data/data_train_enhancement/test/mask
MY=/home/ccf/CCF/Cell_segnet/data/data_train_enhancement
################################################
rm -rf $MY/train.txt
echo "Create train.txt"
find $DATA_train/ -name "*.tif">>$MY/img.txt
find $MASK_train/ -name "*.tif">>$MY/mask.txt
paste -d " " $MY/img.txt $MY/mask.txt>$MY/train.txt
rm -rf $MY/img.txt
rm -rf $MY/mask.txt
##################################################
rm -rf $MY/test.txt
echo "Create test.txt"
find $DATA_test/ -name "*.tif">>$MY/img.txt
find $MASK_test/ -name "*.tif">>$MY/mask.txt
paste -d " " $MY/img.txt $MY/mask.txt>$MY/test.txt
rm -rf $MY/img.txt
rm -rf $MY/mask.txt可以适当修改,以适应自己的路径。
二、训练
训练之前,在训练的时候我们可以根据自己训练的要求更改分割的类型,segnet对原来是11中类型,在博主只有两种类型,这就会遇到对网络的修改,同时数据输入的也是一样原来的是360*480,网络中的修改根据个人的要求以及效果进行修改,修改输出层参数num_output为2,以及class-weighting,只有两个。要注意的是上采样upsample这个参数的修改,以及最后的class_weighting,对于class_weighting个数以及参数是根据自己的数据以及要求设定,输出几个类别class_weighting就有几个,对于class_weighting参数的确定是根据训练数据的mask中每一种类型的label确定的,就算方法:(all_label/class)/label,下面是计算的matlab算法代码:
clear;
clc;
Path='C:\\Users\\xxxxx\\Desktop\\mask\\'
% save_mask_path='/home/ccf/CCF/Cell_segnet/data/mask_change/'
files=dir(Path);
%element = [];
for k=3:length(files)
k
subpath=[Path,files(k).name];
name=files(k).name;
image=imread(subpath);
I=image;
name
I
img=uint8(zeros(360,480));
[x,y]=find(I==0);
for i=1:length(x)
img(x(i),y(i))=0;
end
[x,y]=find(I==1);
for i=1:length(x)
img(x(i),y(i))=1;
end
% imwrite(img,[save_mask_path,name]);
label_num=double(unique(img));
element(:,1)=[0;1];
if (length(element(:,1))==length(label_num))
element(:,1)=label_num;
end
for j=1:length(label_num)
a=label_num(j);
e=length(find(img==a));
element(j,i-1)=e;
end
end
num=element(:,2:end);
sum_num=sum(num,2);
median=sum(sum_num)/length(sum_num);
class_weighting=median./sum_num;
total=[element(:,1),class_weighting];
save('class_weight.mat','total');最后查看class_weighting中保存的值即可,博主是2类,所有最后生成的class_weighting有两个值,ignore_label=2,num_outout = 2;完毕。
训练模型需要的东西:
预训练模型:
- Segnet Basic model file:
segnet_basic_camvid.prototxtweights: [http://mi.eng.cam.ac.uk/~agk34/resources/SegNet/segnet_basic_camvid.caffemodel]
solver.prototxt如下所示,train.prototxt就不贴了,因为有些长。
net: "examples/segnet/segnet_train.prototxt" # Change this to the absolute path to your model file
test_initialization: false
test_iter: 1
test_interval: 10000000
base_lr: 0.01 #0.1
lr_policy: "step"
gamma: 1.0
stepsize: 50 #10000000
display: 20
momentum: 0.9
max_iter: 50000
weight_decay: 0.0005
snapshot: 50#1000
snapshot_prefix: "examples/segnet/segnet_train/segnet_basic/seg" # Change this to the absolute path to where you wish to output solver snapshots
solver_mode: GPU#!bin/sh
./build/tools/caffe train -gpu 2,3 -solver examples/segnet/segnet_solver.prototxt -weights examples/segnet/segnet_train/premodel/segnet_basic_camvid.caffemodel # This will begin training SegNet-Basic on GPU 0上面就是训练脚本了。完毕。
三、测试
1.生成含bn层的推理模型,脚本是:
#!bin/sh
echo "------------------generating bn statistics is begin-----------------------------"
python generate_bn_statistics.py examples/segnet/segnet_train.prototxt examples/segnet/segnet_train/segnet_basic/seg_iter_15700.caffemodel models/inference # compute BN statistics for SegNet
echo "------------------generating bn statistics is end-----------------------------"
generate_bn_statistics.py如下:
#-*-coding:utf8-*-
#!/usr/bin/env python
import os
import numpy as np
from skimage.io import ImageCollection
from argparse import ArgumentParser
caffe_root = '/data/xxxxxx/caffe-segnet-cudnn/caffe-segnet-cudnn5/' # Change this to the absolute directoy to SegNet Caffe
import sys
sys.path.insert(0, caffe_root + 'python')
import caffe
from caffe.proto import caffe_pb2
from google.protobuf import text_format
def extract_dataset(net_message):
assert net_message.layer[0].type == "DenseImageData"
source = net_message.layer[0].dense_image_data_param.source
with open(source) as f:
data = f.read().split()
ims = ImageCollection(data[::2])
labs = ImageCollection(data[1::2])
assert len(ims) == len(labs) > 0
return ims, labs
def make_testable(train_model_path):
# load the train net prototxt as a protobuf message
with open(train_model_path) as f:
train_str = f.read()
train_net = caffe_pb2.NetParameter()
text_format.Merge(train_str, train_net)
# add the mean, var top blobs to all BN layers
for layer in train_net.layer:
if layer.type == "BN" and len(layer.top) == 1:
layer.top.append(layer.top[0] + "-mean")
layer.top.append(layer.top[0] + "-var")
# remove the test data layer if present
if train_net.layer[1].name == "data" and train_net.layer[1].include:
train_net.layer.remove(train_net.layer[1])
if train_net.layer[0].include:
# remove the 'include {phase: TRAIN}' layer param
train_net.layer[0].include.remove(train_net.layer[0].include[0])
return train_net
def make_test_files(testable_net_path, train_weights_path, num_iterations,
in_h, in_w):
# load the train net prototxt as a protobuf message
with open(testable_net_path) as f:
testable_str = f.read()
testable_msg = caffe_pb2.NetParameter()
text_format.Merge(testable_str, testable_msg)
bn_layers = [l.name for l in testable_msg.layer if l.type == "BN"]
bn_blobs = [l.top[0] for l in testable_msg.layer if l.type == "BN"]
bn_means = [l.top[1] for l in testable_msg.layer if l.type == "BN"]
bn_vars = [l.top[2] for l in testable_msg.layer if l.type == "BN"]
net = caffe.Net(testable_net_path, train_weights_path, caffe.TEST)
# init our blob stores with the first forward pass
res = net.forward()
bn_avg_mean = {bn_mean: np.squeeze(res[bn_mean]).copy() for bn_mean in bn_means}
bn_avg_var = {bn_var: np.squeeze(res[bn_var]).copy() for bn_var in bn_vars}
# iterate over the rest of the training set
for i in xrange(1, num_iterations):
res = net.forward()
for bn_mean in bn_means:
bn_avg_mean[bn_mean] += np.squeeze(res[bn_mean])
for bn_var in bn_vars:
bn_avg_var[bn_var] += np.squeeze(res[bn_var])
print 'progress: {}/{}'.format(i, num_iterations)
# compute average means and vars
for bn_mean in bn_means:
bn_avg_mean[bn_mean] /= num_iterations
for bn_var in bn_vars:
bn_avg_var[bn_var] /= num_iterations
for bn_blob, bn_var in zip(bn_blobs, bn_vars):
m = np.prod(net.blobs[bn_blob].data.shape) / np.prod(bn_avg_var[bn_var].shape)
bn_avg_var[bn_var] *= (m / (m - 1))
# calculate the new scale and shift blobs for all the BN layers
scale_data = {bn_layer: np.squeeze(net.params[bn_layer][0].data)
for bn_layer in bn_layers}
shift_data = {bn_layer: np.squeeze(net.params[bn_layer][1].data)
for bn_layer in bn_layers}
var_eps = 1e-9
new_scale_data = {}
new_shift_data = {}
for bn_layer, bn_mean, bn_var in zip(bn_layers, bn_means, bn_vars):
gamma = scale_data[bn_layer]
beta = shift_data[bn_layer]
Ex = bn_avg_mean[bn_mean]
Varx = bn_avg_var[bn_var]
new_gamma = gamma / np.sqrt(Varx + var_eps)
new_beta = beta - (gamma * Ex / np.sqrt(Varx + var_eps))
new_scale_data[bn_layer] = new_gamma
new_shift_data[bn_layer] = new_beta
print "New data:"
print new_scale_data.keys()
print new_shift_data.keys()
# assign computed new scale and shift values to net.params
for bn_layer in bn_layers:
net.params[bn_layer][0].data[...] = new_scale_data[bn_layer].reshape(
net.params[bn_layer][0].data.shape
)
net.params[bn_layer][1].data[...] = new_shift_data[bn_layer].reshape(
net.params[bn_layer][1].data.shape
)
# build a test net prototxt
test_msg = testable_msg
# replace data layers with 'input' net param
data_layers = [l for l in test_msg.layer if l.type.endswith("Data")]
for data_layer in data_layers:
test_msg.layer.remove(data_layer)
test_msg.input.append("data")
test_msg.input_dim.append(1)
test_msg.input_dim.append(3)
test_msg.input_dim.append(in_h)
test_msg.input_dim.append(in_w)
# Set BN layers to INFERENCE so they use the new stat blobs
# and remove mean, var top blobs.
for l in test_msg.layer:
if l.type == "BN":
if len(l.top) > 1:
dead_tops = l.top[1:]
for dl in dead_tops:
l.top.remove(dl)
l.bn_param.bn_mode = caffe_pb2.BNParameter.INFERENCE
# replace output loss, accuracy layers with a softmax
dead_outputs = [l for l in test_msg.layer if l.type in ["SoftmaxWithLoss", "Accuracy"]]
out_bottom = dead_outputs[0].bottom[0]
for dead in dead_outputs:
test_msg.layer.remove(dead)
test_msg.layer.add(
name="prob", type="Softmax", bottom=[out_bottom], top=['prob']
)
return net, test_msg
def make_parser():
p = ArgumentParser()
p.add_argument('train_model')
p.add_argument('weights')
p.add_argument('out_dir')
return p
if __name__ == '__main__':
caffe.set_mode_gpu()
p = make_parser()
args = p.parse_args()
# build and save testable net
if not os.path.exists(args.out_dir):
os.makedirs(args.out_dir)
print "Building BN calc net..."
testable_msg = make_testable(args.train_model)
BN_calc_path = os.path.join(
args.out_dir, '__for_calculating_BN_stats_' + os.path.basename(args.train_model)
)
with open(BN_calc_path, 'w') as f:
f.write(text_format.MessageToString(testable_msg))
# use testable net to calculate BN layer stats
print "Calculate BN stats..."
train_ims, train_labs = extract_dataset(testable_msg)
train_size = len(train_ims)
minibatch_size = testable_msg.layer[0].dense_image_data_param.batch_size
num_iterations = train_size // minibatch_size + train_size % minibatch_size
in_h, in_w =(360, 480) #记得修改和自己图片一样的大小
test_net, test_msg = make_test_files(BN_calc_path, args.weights, num_iterations,
in_h, in_w)
# save deploy prototxt
#print "Saving deployment prototext file..."
#test_path = os.path.join(args.out_dir, "deploy.prototxt")
#with open(test_path, 'w') as f:
# f.write(text_format.MessageToString(test_msg))
print "Saving test net weights..."
test_net.save(os.path.join(args.out_dir, "test_weights_15750.caffemodel")) #记得修改迭代多少次命名
print "done"
2.生成预测图片
脚本:
#!bin/sh
echo "-------------------test segmentation is begin---------------------"
python test_segmentation.py --model models/inference/segmentation_inference.prototxt --weights models/inference/test_weights_15750.caffemodel --iter 26 #12250 #15750 # Test SegNet
echo "-------------------test segmentation is end---------------------"
test_segmentation.py
#-*-coding=utf8-*-
import numpy as np
import matplotlib.pyplot as plt
import os.path
import json
import scipy
import argparse
import math
import pylab
from sklearn.preprocessing import normalize
import cv2
caffe_root = '/data/xxxxxx/caffe-segnet-cudnn/caffe-segnet-cudnn5/' # Change this to the absolute directoy to SegNet Caffe
import sys
sys.path.insert(0, caffe_root + 'python')
import caffe
# Import arguments
parser = argparse.ArgumentParser()
parser.add_argument('--model', type=str, required=True)
parser.add_argument('--weights', type=str, required=True)
parser.add_argument('--iter', type=int, required=True)
args = parser.parse_args()
caffe.set_mode_gpu()
net = caffe.Net(args.model,
args.weights,
caffe.TEST)
for i in range(0, args.iter):
net.forward()
print(i)
image = net.blobs['data'].data
#print(image.shape)
label = net.blobs['label'].data
#print(label.shape)
predicted = net.blobs['prob'].data #predicted: float32
# convert np.float64 to np.uint8
#image = (image* 50000).astype(np.uint8)
#lahel = (label * 50000).astype(np.uint8)
#predicted = (predicted * 50000).astype(np.uint8)
#print(predicted.shape)
image = np.squeeze(image[0,:,:,:])
output = np.squeeze(predicted[0,:,:,:])
ind = np.argmax(output, axis=0)
cv2.imwrite(str(i%26) + "predicted.png", ind * 100)# predicted: float32, this predicated is kuoda * 100
r = ind.copy()
g = ind.copy()
b = ind.copy()
r_gt = label.copy()
g_gt = label.copy()
b_gt = label.copy()
#print(output.shape)
#print(output.dtype)
#print(output)
# Sky = [128,128,128]
# Building = [128,0,0]
# Pole = [192,192,128]
# Road_marking = [255,69,0]
# Road = [128,64,128]
# Pavement = [60,40,222]
# Tree = [128,128,0]
# SignSymbol = [192,128,128]
# Fence = [64,64,128]
# Car = [64,0,128]
# Pedestrian = [64,64,0]
# Bicyclist = [0,128,192]
# Unlabelled = [0,0,0]
# label_colours = np.array([Sky, Building, Pole, Road, Pavement, Tree, SignSymbol, Fence, Car, Pedestrian, Bicyclist, Unlabelled])
BG = [0,0,0]
M = [0,255,0]
label_colours = np.array([BG, M])
for l in range(0,2):
r[ind==l] = label_colours[l,0]
g[ind==l] = label_colours[l,1]
b[ind==l] = label_colours[l,2]
r_gt[label==l] = label_colours[l,0]
g_gt[label==l] = label_colours[l,1]
b_gt[label==l] = label_colours[l,2]
# we do not normalize
rgb = np.zeros((ind.shape[0], ind.shape[1], 3))
rgb[:,:,0] = r#/255.0
rgb[:,:,1] = g#/255.0
rgb[:,:,2] = b#/255.0
rgb_gt = np.zeros((ind.shape[0], ind.shape[1], 3))
rgb_gt[:,:,0] = r_gt#/255.0
rgb_gt[:,:,1] = g_gt#/255.0
rgb_gt[:,:,2] = b_gt#/255.0
image = image#/255.0
image = np.transpose(image, (1,2,0))
output = np.transpose(output, (1,2,0))
image = image[:,:,(2,1,0)]
#scipy.misc.toimage(rgb, cmin=0.0, cmax=255).save(IMAGE_FILE+'_segnet.png') #保存文件
cv2.imwrite(str(i%26)+'image.png', image.astype(np.uint8))
cv2.imwrite(str(i%26)+'rgb_gt.png', rgb_gt.astype(np.uint8))
cv2.imwrite(str(i%26)+'rgb.png', rgb.astype(np.uint8))
#plt.figure()
#plt.imshow(image,vmin=0, vmax=1) #显示源文件
#plt.figure()
#plt.imshow(rgb_gt,vmin=0, vmax=1) #给的mask图片,如果测试的图片没有mask,可以随便放个图片列表,省的修改代码
#plt.figure()
#plt.imshow(rgb,vmin=0, vmax=1) # 预测图片
#plt.show()
print 'Success!'
四、mean IOU 评价的计算
#!/usr/bin/python
import numpy as np
from skimage import io
import cv2
def pixel_accuracy(eval_segm, gt_segm):
'''
sum_i(n_ii) / sum_i(t_i)
'''
check_size(eval_segm, gt_segm)
cl, n_cl = extract_classes(gt_segm)
eval_mask, gt_mask = extract_both_masks(eval_segm, gt_segm, cl, n_cl)
sum_n_ii = 0
sum_t_i = 0
for i, c in enumerate(cl):
curr_eval_mask = eval_mask[i, :, :]
curr_gt_mask = gt_mask[i, :, :]
sum_n_ii += np.sum(np.logical_and(curr_eval_mask, curr_gt_mask))
sum_t_i += np.sum(curr_gt_mask)
if (sum_t_i == 0):
pixel_accuracy_ = 0
else:
pixel_accuracy_ = sum_n_ii / sum_t_i
return pixel_accuracy_
def mean_accuracy(eval_segm, gt_segm):
'''
(1/n_cl) sum_i(n_ii/t_i)
'''
check_size(eval_segm, gt_segm)
cl, n_cl = extract_classes(gt_segm)
eval_mask, gt_mask = extract_both_masks(eval_segm, gt_segm, cl, n_cl)
accuracy = list([0]) * n_cl
for i, c in enumerate(cl):
curr_eval_mask = eval_mask[i, :, :]
curr_gt_mask = gt_mask[i, :, :]
n_ii = np.sum(np.logical_and(curr_eval_mask, curr_gt_mask))
t_i = np.sum(curr_gt_mask)
if (t_i != 0):
accuracy[i] = n_ii / t_i
mean_accuracy_ = np.mean(accuracy)
return mean_accuracy_
def mean_IU(eval_segm, gt_segm):
'''
(1/n_cl) * sum_i(n_ii / (t_i + sum_j(n_ji) - n_ii))
'''
check_size(eval_segm, gt_segm)
cl, n_cl = union_classes(eval_segm, gt_segm)
_, n_cl_gt = extract_classes(gt_segm)
eval_mask, gt_mask = extract_both_masks(eval_segm, gt_segm, cl, n_cl)
IU = list([0]) * n_cl
for i, c in enumerate(cl):
curr_eval_mask = eval_mask[i, :, :]
curr_gt_mask = gt_mask[i, :, :]
if (np.sum(curr_eval_mask) == 0) or (np.sum(curr_gt_mask) == 0):
continue
n_ii = np.sum(np.logical_and(curr_eval_mask, curr_gt_mask))
t_i = np.sum(curr_gt_mask)
n_ij = np.sum(curr_eval_mask)
IU[i] = n_ii / (t_i + n_ij - n_ii)
mean_IU_ = np.sum(IU) / n_cl_gt
return mean_IU_
def frequency_weighted_IU(eval_segm, gt_segm):
'''
sum_k(t_k)^(-1) * sum_i((t_i*n_ii)/(t_i + sum_j(n_ji) - n_ii))
'''
check_size(eval_segm, gt_segm)
cl, n_cl = union_classes(eval_segm, gt_segm)
eval_mask, gt_mask = extract_both_masks(eval_segm, gt_segm, cl, n_cl)
frequency_weighted_IU_ = list([0]) * n_cl
for i, c in enumerate(cl):
curr_eval_mask = eval_mask[i, :, :]
curr_gt_mask = gt_mask[i, :, :]
if (np.sum(curr_eval_mask) == 0) or (np.sum(curr_gt_mask) == 0):
continue
n_ii = np.sum(np.logical_and(curr_eval_mask, curr_gt_mask))
t_i = np.sum(curr_gt_mask)
n_ij = np.sum(curr_eval_mask)
frequency_weighted_IU_[i] = (t_i * n_ii) / (t_i + n_ij - n_ii)
sum_k_t_k = get_pixel_area(eval_segm)
frequency_weighted_IU_ = np.sum(frequency_weighted_IU_) / sum_k_t_k
return frequency_weighted_IU_
'''
Auxiliary functions used during evaluation.
'''
def get_pixel_area(segm):
return segm.shape[0] * segm.shape[1]
def extract_both_masks(eval_segm, gt_segm, cl, n_cl):
eval_mask = extract_masks(eval_segm, cl, n_cl)
gt_mask = extract_masks(gt_segm, cl, n_cl)
return eval_mask, gt_mask
def extract_classes(segm):
cl = np.unique(segm)
n_cl = len(cl)
return cl, n_cl
def union_classes(eval_segm, gt_segm):
eval_cl, _ = extract_classes(eval_segm)
gt_cl, _ = extract_classes(gt_segm)
cl = np.union1d(eval_cl, gt_cl)
n_cl = len(cl)
return cl, n_cl
def extract_masks(segm, cl, n_cl):
h, w = segm_size(segm)
masks = np.zeros((n_cl, h, w))
for i, c in enumerate(cl):
masks[i, :, :] = segm == c
return masks
def segm_size(segm):
try:
height = segm.shape[0]
width = segm.shape[1]
except IndexError:
raise
return height, width
def check_size(eval_segm, gt_segm):
h_e, w_e = segm_size(eval_segm)
h_g, w_g = segm_size(gt_segm)
if (h_e != h_g) or (w_e != w_g):
raise EvalSegErr("DiffDim: Different dimensions of matrices!")
'''
Exceptions
'''
class EvalSegErr(Exception):
def __init__(self, value):
self.value = value
def __str__(self):
return repr(self.value)
###############now we do some eval.
# test image only 1 image
def eval_segm(preddir, gtdir):
pred = io.imread(preddir, 1)
gt = io.imread(gtdir, 1)
pred = (pred ).astype(np.uint8)
np.set_printoptions(threshold='nan')
#print(pred[10:50,:])
_, pred_th= cv2.threshold(pred, 0.0000000000000001, 1, cv2.THRESH_BINARY)
#print(gt[10:50,:])
gt = (gt).astype(np.uint8)
_, gt_th= cv2.threshold(gt, 0.0000000000000001, 1, cv2.THRESH_BINARY)
pixel_accu = pixel_accuracy(pred_th, gt_th)
mean_accu = mean_accuracy(pred_th, gt_th)
mean_iou = mean_IU(pred_th, gt_th)
fw_iou = frequency_weighted_IU(pred_th, gt_th)
print("pixel_accu is: ", pixel_accu)
print("mean_accu is: ", mean_accu)
print("mean_iou is: ",mean_iou)
print("fw_iou is: ", fw_iou)
return pixel_accu, mean_accu, mean_iou, fw_iou
# test batch image
def eval_batch(rootdir):
res_sum = []
pixel_accu = 0.0
mean_accu = 0.0
mean_iou = 0.0
fw_iou = 0.0
for i in range(16):
preddir = rootdir + str(i)+"predicted.png"
gtdir = rootdir + str(i) + "rgb_gt.png"
print("===============%d==================", i)
resperimage = eval_segm(preddir, gtdir)
res_sum.append(resperimage)
# compute avg eval metrics
print("==================avg eval seg=========================")
len_res_sum = len(res_sum)
for i in range(len_res_sum):
pixel_accu += res_sum[i][0]
mean_accu += res_sum[i][1]
mean_iou += res_sum[i][2]
fw_iou += res_sum[i][3]
print("avg pixel_accu : ", pixel_accu / len_res_sum, "avg mean_accu : ", mean_accu / len_res_sum,\
"avg mean_iou : ", mean_iou / len_res_sum, "avg fw_iou : ", fw_iou/len_res_sum)
# get the contours of huizibiao
def get_contour(imagedir, preddir):
#np.set_printoptions(threshold='nan')
pred = io.imread(preddir, 1)
print(pred.dtype)
#print(pred[:,10:50])
pred = (pred ).astype(np.uint8)
#print(" ")
image = io.imread(imagedir, 1) # because it is float64
print(image.dtype)
print(image.shape)
#print(image[:,10:50])
image = (image* 255).astype(np.uint8)
#cv2.imwrite("image.png",image)
_, pred_th= cv2.threshold(pred, 0.0000000000000001, 1, cv2.THRESH_BINARY)
contours, _ = cv2.findContours(pred_th,cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE)
pred_contours = image
for i in range(len(contours)):
cv2.drawContours(pred_contours, contours[i], -1, (0, 255, 0), 1)
return pred_contours
# batch test contours of huizibiao
def get_contour_batch(rootdir):
for i in range(16):
preddir = rootdir + str(i)+"predicted.png"
imagedir = rootdir + str(i) + "image.png"
print("=================================", i)
cv2.imwrite(str(i)+"image_countours.png", get_contour(imagedir, preddir))
if __name__ == "__main__":
'''
# test only one image.
preddir = "/data/xxxxxx/caffe-segnet-cudnn/caffe-segnet-cudnn5/test_result/3_iter7700/2/predicted.png"
gtdir = "/data/xxxxx/caffe-segnet-cudnn/caffe-segnet-cudnn5/test_result/3_iter7700/2/rgb_gt.png"
eval_segm(preddir, gtdir)
'''
# test batch image
#rootdir = "/data/xxxxxxxx/caffe-segnet-cudnn/caffe-segnet-cudnn5/test_result/116/iter17w/"
rootdir = "/data/xxxxxxxx/caffe-segnet-cudnn/caffe-segnet-cudnn5/"
#eval_batch(rootdir)
#draw contours on the one image
#preddir = "/data/xxxxx/caffe-segnet-cudnn/caffe-segnet-cudnn5/0predicted.png"
#imagedir = "/data/xxxxx/caffe-segnet-cudnn/caffe-segnet-cudnn5/0image.png"
#get_contour(imagedir, preddir)
#test batch
get_contour_batch(rootdir)楼主最后的mean IOU 是95.19%。
至此完毕。