「总结」最全2万字长文解读7大方向人脸数据集v2.0版
人脸图像是计算机视觉领域中研究历史最久,也是应用最广泛的图像。从人脸检测、人脸识别、人脸的年龄表情等属性识别,到人脸的三维重建等,都有非常多的数据集被不断整理提出,极大地促进了该领域的发展。
本次,我们从人脸检测、关键点检测、人脸识别、人脸属性分析、人脸姿态与3D,人脸活体与伪造,人脸风格化等几个方向来给大家做一个比较详细的介,这是在之前介绍的文章「数据集」一文道尽人脸数据集基础上的拓展。
作者&编辑 | 言有三
1. 人脸检测数据集
所谓人脸检测任务,就是要定位出图像中人脸的大概位置。通常检测完之后根据得到的框再进行特征的提取,包括关键点等信息,然后做一系列后续的分析。
(1) Caltech 10000 Web Faces
数据集地址:
http://www.vision.caltech.edu/Image_Datasets/Caltech_10K_WebFaces/。
发布于2007年,这是一个灰度人脸数据集,使用Google图片搜索引擎用关键词爬取所得,包含了7092张图,10524个人脸,平均分辨率在304×312。除此之外还提供双眼鼻子,和嘴巴共4个坐标位置,在早期被较多地使用,现在的方法已经很少用灰度数据集做评测。
(2) AFW
发布于2013年,目前官网数据链接已经失效,可以通过其他渠道获得。AFW数据集是人脸关键点检测非常早期使用的数据集,共包含205个图像,其中有473个标记的人脸。每一个人脸提供了方形边界框,6个关键点和3个姿势角度的标注。
(3) FDDB
数据集地址:
http://vis-www.cs.umass.edu/fddb/index.html。
发布于2010年,这是被广泛用于人脸检测方法评测的一个数据集。FDDB(Face Detection Data Set and Benchmark)的提出是用于研究无约束人脸检测。所谓无约束指的是人脸表情、尺度、姿态、外观等具有较大的可变性。FDDB的图片都来自于 Faces inthe Wild 数据集,图片来源于美联社和路透社的新闻报道图片,所以大部分都是名人,而且是自然环境下拍摄的。共2845张图片,里面有5171张人脸图像。
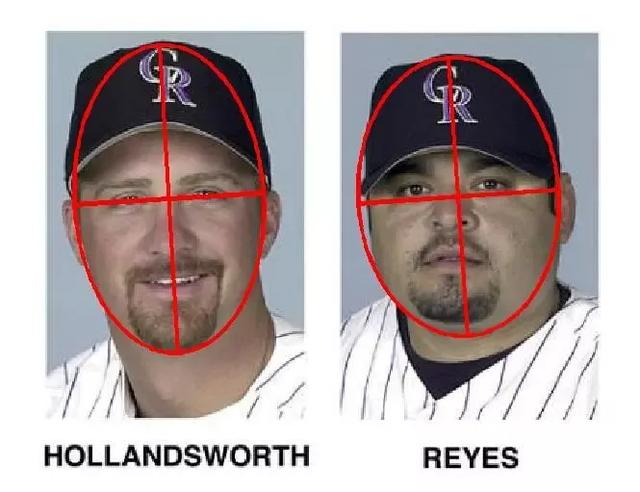
通常人脸检测数据集的标注采用的是矩形标注,即通过矩形将人脸的前额,脸颊和下巴通过矩形包裹起来,但是由于人脸是椭圆状的,所以不可能给出一个恰好包裹整个面部区域而无干扰的矩形。
在FDDB当中采用了椭圆标记法,它可以适应人脸的轮廓。具体来说,每个标注的椭圆形人脸由六个元素组成。(ra、rb、θ、cx、cy、s),其中ra、rb是椭圆的半长轴、半短轴,cx、cy是椭圆的中心点坐标,θ是长轴与水平轴夹角(头往左偏θ为正,头往右偏θ为负),s则是置信度得分。标注的结果是通过多人独立完成标注之后取标注的平均值,而且排除了长或宽小于20个像素的人脸,远离相机的人脸,被遮挡的人脸等。
(4) WIDER Face
数据集地址:
http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/。

发布于2015年,FDDB评测标准由于只有几千张图像,这样的数据集在人脸的姿态、尺度、表情、遮挡和背景等多样性上非常有限,训练出来的模型难以被很好的评判,算法很快就达到饱和。在这样的背景下香港中文大学提出了Wider-face数据集,在很长一段时间里,大型互联网公司和科研机构都在Wider-face上做人脸检测算法竞赛。
Wider-face总共有32203张图片,共有393703张人脸,比FDDB数据集大10倍,而且在面部的尺寸、姿势、遮挡、表情、妆容、光照上都有很大的变化,算法不仅标注了框,还提供了遮挡和姿态的信息,自发布后广泛应用于评估性能比传统方法更强大的卷积神经网络。
Wider-face中的图像分辨率较高,所有图像的宽都缩放到1024像素,最小标注的人脸大小为10×10,平均一张图超过10个人脸,密集小人脸非常多。训练集,验证集,测试集分别占40%,10%,50%,测试集非常大,结果可靠性高。
根据EdgeBox方法的检测率Wider-face评测被划分为三个难度等级:Easy, Medium, Hard,可以在各个任务维度上进行评测,比如Hard等级非常适合评测小脸检测框架。
(5) MALF
数据集地址:
http://www.cbsr.ia.ac.cn/faceevaluation/。
MALF(Multi-Attribute Labelled Faces)发布于2015年,是为了更加细粒度地评估野外环境中人脸检测模型而设计的数据库。数据主要来源于Internet,包含5250个图像、11931个人脸。每一幅图像包含正方形边界框,头部姿态的俯仰程度,包括小中大三个等级的标注。该数据集忽略了小于20×20或者非常难以检测的人脸,共包含大约838个人脸,占该数据集的7%。同时该数据集还提供了性别,是否带眼镜、是否遮挡、是否是夸张的表情等辅助信息。
(6) MAFA
数据集地址:
http://www.escience.cn/people/geshiming/mafa.html。
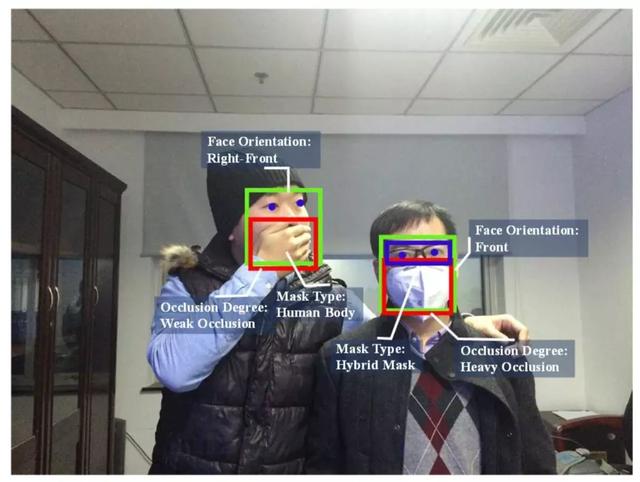
发布于2017年,这是一个遮挡人脸检测数据集,总共包含30811张图、35806张被遮挡的人脸,包含各种方向和尺度的遮挡。
它们首先将人脸分为4个区域,分为眼睛、鼻子、嘴巴、下颌,根据遮挡区域数量将遮挡程度分为三档。weak occlusion对应一到两个区域的遮挡,medium occlusion对应3个区域的遮挡,heavy occlusion对应4个区域的遮挡。
人脸方向包含5个,left、front、right、left-front及right-front。遮挡类型分为4个,即人造的纯色遮挡物、人造的复杂纹理遮挡物、手/头发等身体造成的自遮挡以及复杂类型。
(7) Unconstrained Face Detection Dataset(UFDD)
数据集地址:https://ufdd.info/。

发布于2018年,这是一个非限制场景下的人脸检测数据集,总共包含6425张图、10897张人脸,包含雨天(Rain)、雪天(Snow)、雾天(Haze)、模糊(Blur)、光照(Illumination)、晶体障碍(Lens impediments)和干扰物(Distractors)等7个场景。
除此之外,还有一些比较特殊的,比如鱼眼人脸检测数据集,由于比较小众,就不再集中介绍。总的来说,人脸检测数据集的发展历史,就是不断向真实复杂场景靠近。
2. 关键点检测
检测到人脸后,下一步就是定位出关键点,关键点是人脸形状的稀疏表示,它在人脸跟踪、美颜等任务中都很重要,现在已经从最开始的5个关键点发展到了超过200个关键点的标注。
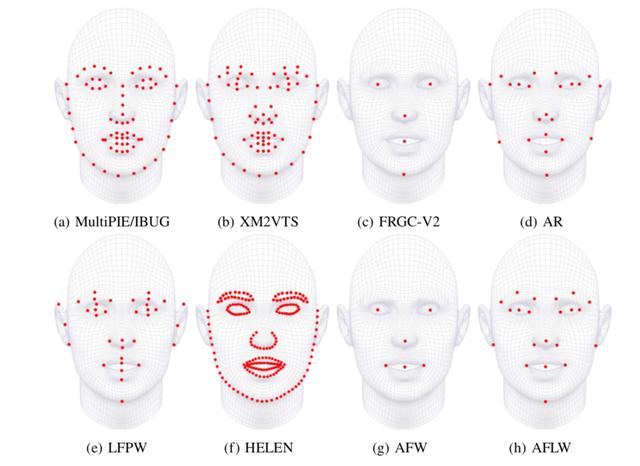
(1) LFPW、HELEN、AFW、IBUG、XM2VTS、FRGC-V2
首先是一些比较小和比较老的数据集,AFW前面已经介绍。
XM2VTS,发布于1999年,网址为
http://www.ee.surrey.ac.uk/CVSSP/xm2vtsdb/,包含295个人、2360张正面图,标注了68个关键点,大部分的图像是无表情的,而且是在同样的光照环境下。
AR人脸数据库发布于1998年,网址为
http://www2.ece.ohio-state.edu/~aleix/ARdatabase.html,包括126个人,超过4000张图,标注了22个关键点。
FGVC-V2人脸数据库发布于2005年,网址为
https://www.nist.gov/programs-projects/face-recognition-grand-challenge-frgc,共466个人的4950张图,包括均匀的光照条件下的高质量图和不均匀的光照条件下的低质量图,标注了5个关键点。
LFPW人脸数据库,发布于2011年,网址为
https://neerajkumar.org/projects/face-parts/,包括1432张图像,标注了29个关键点。
Helen人脸数据库,发布于2012年,网址为
http://www.ifp.illinois.edu/~vuongle2/helen/,包括训练集和测试集,测试集包含了330张人脸图片,训练集包括了2000张人脸图片,都被标注了194个特征点。
IBUG人脸数据库,发布于2013年,网址为
https://ibug.doc.ic.ac.uk/resources/facial-point-annotations/,这是随着300W一起发布的数据集,包含了135张人脸图片,每张人脸图片被标注了68个特征点。
(2) AFLW
数据集地址:
https://www.tugraz.at/institute/icg/research/team-bischof/lrs/downloads/aflw/。
AFLW(Annotated Facial Landmarks in the Wild)是一个包括多姿态、多视角的大规模人脸数据库,一般用于评估面部关键点检测效果,图片来自于flickr。总共有21997张图,2593张面孔,每张人脸标注21个关键点,共380k个关键点,由于是肉眼标记,不可见的关键点不进行标注。
除了关键点之外,还提供了矩形框和椭圆框的脸部位置标注,其中椭圆框的标注方法与FDDB相同。另外还有从平均3D人脸重建提供的3D的人脸姿态角标注。
大部分图像是彩色图,也有少部分是灰度图,59%为女性,41%为男性,这个数据集非常适合做多角度多人脸检测,关键点定位和头部姿态估计,是关键点检测领域里非常重要的一个数据集。
下图是上述数据集的标注的对比。
(3) 300W、300W挑战赛与300VW、300VW挑战赛
数据集地址:
https://ibug.doc.ic.ac.uk/resources/300-W/。
发布于2013年,包含了300张室内图和300张室外图,其中数据集内部的表情、光照条件、姿态、遮挡、脸部大小变化非常大,是通过Google搜索“party”,“conference”等较难等场景搜集而来。该数据集标注了68个关键点,一定程度上在这个数据集能取得好结果的,在其他数据集也能取得好结果。
300W挑战赛是非常有名的用于评测关键点检测算法的基准,2013在ICCV举办了第一次人脸关键点定位竞赛。300W挑战赛所使用的训练数据集实际上并不是一个全新的数据集,它是采用了半监督的标注工具,将AFLW、AFW、Helen、IBUG、LFPW、FRGC-V2、XM2VTS等数据集进行了统一标注然后得到的,关键信息是68个点。
在ICCV 2015年拓展成了视频标注,即300 Videos in the Wild(300-VW),数据集地址是
https://ibug.doc.ic.ac.uk/resources/300-VW/,感兴趣读者可以关注。
(4) MTFL与MAFL
数据集地址:
http://mmlab.ie.cuhk.edu.hk/projects/TCDCN.html。
发布于2014年,这里包含了两个数据集。
Multi-Task Facial Landmark(MTFL)数据集包含了12995张脸,5个关键点标注,另外也提供了性别、是否微笑、是否佩戴眼镜以及头部姿态的信息。

Multi-Attribute Facial Landmark(MAFL)数据集则包含了20000张脸,5个关键点标注与40个面部属性,实际上MAFL被包含在了Celeba数据集中,该数据集我们后面会进行介绍。这两个数据集都使用TCDCN方法将原来的标注拓展到了68个关键点的标注。

(5) WFLW
数据集地址:
https://wywu.github.io/projects/LAB/WFLW.html。
WFLW包含了10000张脸,其中7500用于训练,2500张用于测试,共98个关键点。除了关键点之外,还有遮挡、姿态、妆容、光照、模糊和表情等信息的标注。
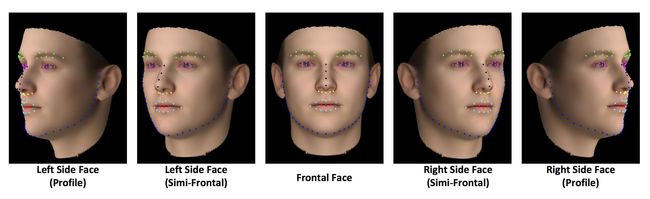
由于人脸关键点是整个人脸任务中非常基础和重要的,所以在工业界有更多的关键点的标注,因为商业价值,这些数据集一般不会进行公开。
前面介绍的关键点标注都是针对二维人脸图像,超过200个点的标注已经是非常的密集,而对于3D人脸图像,相关的开源三维人脸数据集以及Face++,美图等企业都使用了超过1000个以上的稠密关键点。
3. 人脸识别
人脸检测和关键点检测都是比较底层的任务,而人脸识别是更高层的任务,它就是要识别出检测出来的人脸是谁,完成身份比对等任务,也是人脸领域里被研究最多的任务。
3.1 人脸识别图片数据集
(1) FERET
数据库地址:
http://www.nist.gov/itl/iad/ig/colorferet.cfm。
发布于1993年至1996年,由FERET项目创建,包含14051张多姿态,不同光照的灰度人脸图像,每幅图中均只有一个人脸,在早期的人脸识别领域应用非常广泛。
(2) Yale与YALE B
数据集地址:
http://vision.ucsd.edu/~iskwak/ExtYaleDatabase/Yale%20Face%20Database.htm。
Yale人脸数据库与YALE人脸数据库B分别发布于1997年和2001年,这是两个早期的灰度数据集。Yale人脸数据库由耶鲁大学计算视觉与控制中心创建,包含15位志愿者的165张图片,包含光照、表情和姿态的变化。
后面将其拓展到YALE人脸数据库B,包含了10个人的5760幅多姿态,多光照的图像。具体包括9个姿态、64种光照变化,在实验室严格控制的条件下进行。虽然每个人的图像很多,但是由于采集人数较少,该数据库的进一步应用受到了比较大的限制。
(3) LFW
数据集地址:
http://vis-www.cs.umass.edu/lfw/index.html#download。

Labeled Faces in the Wild(LFW)发布于2007年,是为了研究非限制环境下的人脸识别问题而建立,这是比较早期而重要的测试人脸识别的数据集,所有的图像都必须要能够被经典的人脸检测算法VJ算法检测出来。
该数据集包含5749个人的13233张全世界知名人士的图像,其中有1680人有2张或2张以上人脸图片。它是在自然环境下拍摄的,因此包含不同背景、朝向、面部表情,且每个图像都被归一化到250×250大小。
CALFW数据集是LFW数据集的拓展,地址为
http://www.whdeng.cn/calfw/index.html?reload=true,它包含了3000对具有较大年龄跨度的人脸图像,可以用于评估人脸识别算法在跨年龄识别中的性能。
(4) CAS-PEAL
数据集地址:
http://www.jdl.ac.cn/peal/。
发布于2008年,CAS-PEAL数据集是中国科学院收集建立的,它主要是为了提供一个大规模的中国人脸数据集用于训练和评估对应东方人的算法,有灰度图和彩色图两个版本。目前,CAS-PEAL人脸数据库由1040个人(595名男性和445名女性)的99594张图像组成,在特定环境下具有不同的姿势、表情、照明条件、表情以及是否佩戴眼镜等信息。对于每个被拍摄的人,通过9个相机来同时捕获不同姿态的图像,平均每一个人采集了约900张图像。
(5) CMU PIE与Multi-PIE
CMU PIE数据集地址:
https://www.ri.cmu.edu/publications/the-cmu-pose-
illumination-and-expression-pie-database-of-human-faces/
Multi-PIE数据集地址:
http://www.cs.cmu.edu/afs/cs/project/PIE/MultiPie/Multi-Pie/Home.html。

CMU PIE数据集发布于2000年,PIE就是姿态(Pose)、光照(Illumination)和表情(Expression)的缩写,包含68位志愿者的41368张图,每个人有13种姿态条件,43种光照条件和4种表情。其中的姿态和光照变化图像也是在严格控制的条件下采集的,它在推动多姿势和多光照的人脸识别研究方面具有非常大的影响力,不过仍然存在模式单一多样性较差的问题。
为了解决这些问题,卡内基梅隆大学的研究人员在2009年建立了Multi-PIE数据集。它包含337个人,在15个角度,19个照明条件和不同的表情下记录,最终超过750000个图像。由于图像质量较高,原始的图片大小超过了300G,需要购买。
(6) Pubfig
数据集地址:
http://www.cs.columbia.edu/CAVE/databases/pubfig/。
发布于2010年,这是哥伦比亚大学的公众人物脸部数据集,包含有200个人的58797张人脸图像,主要用于非限制场景下的人脸识别。与LFW相比,这个数据集更大,但是人更少,每个人的图片更多。
(7) MSRA-CFW
数据集地址:https://link.zhihu.com/?target=
http%3A//research.microsoft.com/en-us/projects/msra-cfw/。
发布于2012年,由微软亚洲研究院收集整理,包含1583个人的202792张图像,采用了自动标注的方法。
(8) CASIA-WebFace
数据集地址:
http://classif.ai/dataset/casia-webface/。
发布于2014年,这是中国科学院自动化研究所李子青实验室开放的国内非常有名的数据集,包含10575个人494414张图。
(9) FaceScrub
数据集地址:
http://vintage.winklerbros.net/facescrub.html。
发布于2016年,总共包含了530个人的106863张图片,其中男性女性各占265,分别包括55306和51557张图,每个人大概200张图。
(10) UMDFaces
数据集地址:http://www.umdfaces.io/。
发布于2016年,这个数据集有静态图和视频两部分,其中静态图包含8277个人的367888张脸,视频包含22075个视频中的3107个人的3735476张图。同时标注了21个关键点,性别信息,以及人的3个姿态。
(11) MegaFace
数据集地址:
http://megaface.cs.washington.edu/dataset/download.html。
发布于2016年,MegaFace数据集包含一百万张图片,共690000个不同的人,所有数据都是华盛顿大学从Flickr组织收集。这是第一个在一百万规模级别的面部识别算法测试基准。现有脸部识别系统仍难以准确识别超过百万的数据量。为了比较现有公开脸部识别算法的准确度,华盛顿大学在2017年底开展了一个名为“MegaFace Challenge”的公开竞赛。这个项目旨在研究当数据库规模提升数个量级时,现有的脸部识别系统能否维持可靠的准确率。
(12) MS-Celeb-1M
数据集地址:https://www.msceleb.org/。
发布于2016年,这是目前世界上规模最大、水平最高的图像识别赛事之一,由微软亚洲研究院发起,每年定期举办。参赛队伍被要求基于微软云服务,搭建包括人脸检测、对齐、识别的完整人脸识别系统,而且识别系统必须先通过远程实验评估。
训练集合包含10M图片,具体的操作是从1M个名人中,根据他们的受欢迎程度,选择100K个,然后利用搜索引擎,给100K个人每人搜大概100张图片。共得到100K*100=10M个图片。测试集包括1000个名人,这1000个名人来自于1M个明星中随机挑选,每个名人大概有20张图片。
(13) VGG Face与VGG Face2
数据集地址:
http://www.robots.ox.ac.uk/~vgg/data/vgg_face2/
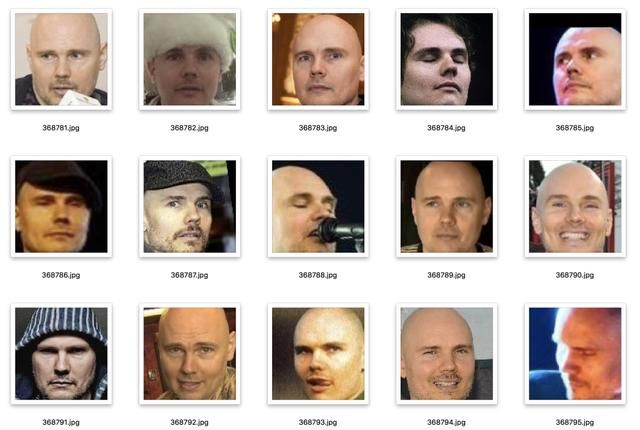
VGG Face数据集发布于2015年,包括2622个对象且每个对象拥有约1000幅静态图像。VGG Face2数据集发布于2017年,包含了9131个人的3.31百万张图片,平均每一个人有362.6张图。这个数据集人物ID较多,且每个ID包含的图片个数也较多。数据集覆盖了大范围的姿态、年龄和种族,其中约有59.7%的男性。除了身份信息之外,数据集还包括人脸框、5个关键点,以及估计的年龄和姿态。
(14) IARPA Janus Benchmark
数据集地址:
https://www.iarpa.gov/index.php/research-programs/janus。
美国国家技术标准局(NIST)在2015年召开的CVPR上发布了IJB-A人脸验证与识别数据集,IJB-A数据包含来自500个对象的5396幅静态图像和20412帧的视频数据。被拍摄者来自世界不同国家、地区和种族,具有广泛的地域性,在完全无约束环境下采集的。很多被拍摄者的面部姿态变化巨大,光照变化剧烈以及拥有不同的图像分辨率。
另外,数据集引入了“模板”的概念,即在无约束条件下采集的、所有感兴趣面部媒体的一个集合,这个媒体集合不仅包括被拍摄者的静态图像,也包括视频片段。因此一个模板代表一个集合,最终的人脸验证与识别不是基于单个图像,而是基于集合对集合。
此后,2017年迭代到IARPA Janus B,2018年迭代到IARPA Janus C,这是业界非常具有难度的人脸识别竞赛。
(15) IMDB-Face
数据集地址:
https://github.com/fwang91/IMDb-Face#data-download。
发布于2018年,这是一个经过人工清理标签的干净人脸识别数据集,包含590000个人,170万张图。数据来源于IMDb网站,清理数据集耗费了50个人共1个月的时间,由于数据集质量更高,可以用更少的数据完成相关任务。
3.2 人脸识别视频数据集
(1) YouTube Faces DB
数据集地址:
http://www.cs.tau.ac.il/~wolf/ytfaces/results.html。

发布于2011年,这是一个视频数据集,也是用来做人脸验证的。它包含了1595个人的3425段视频,最短的为48帧,最长的为6070帧。和LFW不同的是,在这个数据集下,算法需要判断两段视频里面是不是同一个人,有不少在照片上有效的方法,在视频上可能会失败。
(2) PaSC
数据集地址:
https://www.nist.gov/programs-projects/point-and-shoot-face-recognition-challenge-pasc。
发布于2014年,这是一个图片和视频人脸数据集,包含9376张静态图以及293个人的2802个视频。
(3) iQIYI-VID
数据集地址:
http://challenge.ai.iqiyi.com/detail?raceId=5b1129e42a360316a898ff4f。
发布于2018年,iQIYI-VID是当前全球最大的明星视频数据集,数据集包含5000位明星艺人,长达1000小时、50万条视频片段,每条视频的长度是1~30秒,可以进行多模态(人脸、声音、动作及服装等特征)人物识别的挑战研究。
3.3 三维人脸识别数据集
(1) ND-2006
数据集地址:
https://cvrl.nd.edu/projects/data/#nd-2006-data-set。
发布于2006年,包含888个人,每一个人约60张图,共13450张图,包含6种不同的表情。
(2) bosphorus
数据集地址:
http://bosphorus.ee.boun.edu.tr/。
发布于2008年,这是一个使用结构光设备采集的3D人脸数据集数据集,它包含了105个人的4666张三维人脸图片,被采集者距离设备1.5m,采集的姿态为正脸。
3.4 人脸识别其他数据集
(1) FIW
数据集地址:
https://web.northeastern.edu/smilelab/fiwkinship/

发布于2017年,这是一个研究亲属人脸识别算法的数据集,总共包含1000个家庭的11163张图片,每一个家庭至少3个成员,8张图片。
(2) MeGlass
数据集地址:
https://github.com/cleardusk/MeGlass。

发布于2019年,这是一个戴眼镜的人脸识别数据集,眼镜对人脸识别问题会造成一定的困扰,MeGlass是一个仿真的戴眼镜人脸识别数据集,包括1710个人的14 832张有眼镜图和33087张无眼镜图,所有的图片来自于MegaFace。
(3) LAG
数据集地址:
http://www.ivl.disco.unimib.it/activities/large-age-gap-face-verification/。

发布于2018年,LAG Dataset是一个跨年龄的人脸识别数据集,它包括1010个人的3828张图片,每一个人都至少包括一组小孩/年轻,或者成人/老人的照片。
(4) iCartoonFace
数据集地址:
http://www.ivl.disco.unimib.it/activities/large-age-gap-face-verification/。

发布于2019年,iCartoonFace是一个卡通人脸识别数据集,它包括2639个人物形象,68312张图片,来自于爱奇艺中的卡通视频和搜索引擎中的图片。
(5) RFW
数据集地址:
http://whdeng.cn/RFW/index.html。

发布于2019年,这是一个研究人脸识别算法中种族偏移问题的数据集,总共包含4类人种,即Caucasian, Indian, Asian, African。
其中Caucasian作为训练集,包含10000个人的468139张脸,测试集则包含4类人种。其中Caucasian包含2959个人,10196张脸。Indian包含2984个人,10308张脸。Asian包含2492个人,9688张脸。African包含2995个人,10415张脸。
人脸识别虽然在百万级别的数据集如MegaFace等都已经达到相当高的水准,但是在现实世界中面临各种姿态,分辨率、遮挡等问题,仍然有较大的研究空间。
4. 人脸属性数据集
人脸属性识别在人机交互、安全控制、直播娱乐、自动驾驶等领域都非常具有应用价值,因此也已经得到了广泛的研究。
4.1 通用人脸属性分析数据集
(1) FaceTracer
数据集地址:
https://www.cs.columbia.edu/CAVE/databases/facetracer/
发布于2008年,该数据集包括15000张人脸,共10组属性,包括性别,种族,年龄,头发颜色,是否佩戴眼镜,是否有胡须,是否微笑,是否模糊,光照条件以及室内还是室外环境,这是比较早期的人脸属性数据集。
(2) PubFig
数据集地址:
https://www.cs.columbia.edu/CAVE/databases/pubfig/
发布于2009年,该数据集包括200个人的58797张人脸,来自于互联网搜索,因此具有很好的姿态,光照,表情和场景多样性,总共标注了73个人脸属性。
(3) LFWA和CelebA
数据集地址:
http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html。

两者都发布于2015年,LFWA的图片全部来自于LFW人脸识别数据集,CelebA则包含了10177个名人的202599张人脸图片,它们标注的人脸属性有40种,包括是否戴眼镜,是否微笑等,是当前最大最广泛使用的人脸属性数据集。
(4) Fairface
数据集地址:
https://github.com/joojs/fairface。

发布于2019年,共包括108501张图。由于当前很多的人脸数据集中存在人种的不均衡,fairface建立了一个更加均衡的数据集。该数据集共包括white、black、Indian、East Asian、Southeast Asian、Middle East及Latino 7类人种,图片来源于YFCC-100M Flickr数据集,标注属性包括人种(Race)、性别(Gender)、年龄组(Age Group)。
类似的数据集还有IBM收集的Diversity in Faces(DiF),同样来自于YFCC-100M,有超过100万的图片。
4.2 人脸表情数据集
人脸表情识别(Facial Expression Recognition,FER)是人脸属性识别技术中的一个重要组成部分,在人机交互、安全控制、直播娱乐、自动驾驶等领域都非常具有应用价值,因此在很早前就已经得到了研究。
(1) The Japanese Female Facial Expression(JAFFE) Database
数据集链接:
http://www.kasrl.org/jaffe.html。
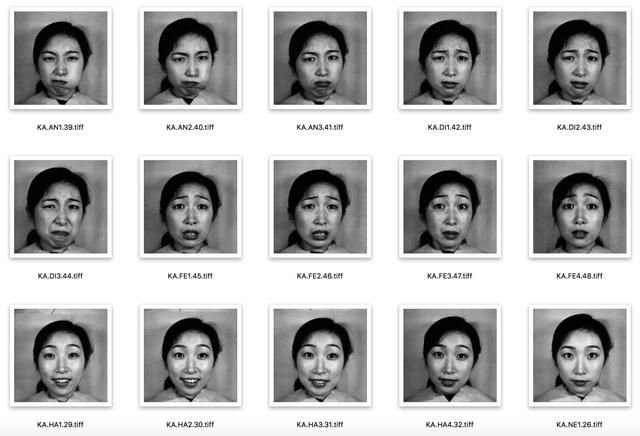
1998年发布,这是比较小和老的数据库。该数据库是由10位日本女性在实验环境下根据指示做出各种表情,再由照相机拍摄获取的人脸表情图像。整个数据库一共有213张图像,10个人,全部都是女性,每个人做出7种表情,这7种表情分别是sad、happy、angry、disgust、surprise、fear、neutral,每组大概20张样图。
(2) KDEF与AKDEF(Karolinska Directed Emotional Faces)
数据集地址:
http://www.emotionlab.se/kdef/。

发布于1998年,这个数据集最初是被开发用于心理和医学研究目的。它主要用于知觉、注意、情绪、记忆等实验。在创建数据集的过程中,特意使用比较均匀,柔和的光照,被采集者身穿统一的T恤颜色。这个数据集,包含70个人、35个男性、35个女性,年龄在20至30岁之间。没有胡须、耳环或眼镜,且没有明显的化妆。7种不同的表情,每个表情有5个角度。总共4900张彩色图,尺寸为562×762像素。
(3) GENKI
数据集地址:http://mplab.ucsd.edu。
发布于2009年,GENKI数据集是由加利福尼亚大学的机器概念实验室收集。该数据集包含GENKI-R2009a、GENKI-4K、GENKI-SZSL三个部分。GENKI-R2009a包含11159个图像,GENKI-4K包含4000个图像,分为“笑”和“不笑”两种,每个图片拥有不同的尺度大小、姿势、光照变化、头部姿态,可专门用于做笑脸识别。这些图像包括广泛的背景、光照条件、地理位置、个人身份和种族等。
(4) RaFD
数据集地址:
http://www.socsci.ru.nl:8180/RaFD2/RaFD?p=main。

发布于2010年,该数据集是Radboud大学Nijmegen行为科学研究所整理的,这是一个高质量的脸部数据库,总共包含67个模特,其中20名白人男性成年人,19名白人女性成年人,4个白人男孩,6个白人女孩,18名摩洛哥男性成年人。总共8040张图,包含8种表情,即愤怒、厌恶、恐惧、快乐、悲伤、惊奇、蔑视和中立。每一个表情,包含3个不同的注视方向,且使用5个相机从不同的角度同时拍摄的。
(5) Cohn-Kanade AU-Coded Expression Database
数据集地址:
http://www.pitt.edu/~emotion/ck-spread.htm。

发布于2010年,这个数据库是在Cohn-Kanade Dataset的基础上扩展来的,它包含137个人的不同人脸表情视频帧。这个数据库比起JAFFE要大的多。而且也可以免费获取,包含表情的标注和基本Action Units 的标注。
(6) Fer2013
数据集地址:
https://www.kaggle.com/c/challenges-in-representation-learning-facial-expression-recognition-challenge/data。

发布于2013年,该数据集包含共26190张48×48灰度图,图片的分辨率比较低,共6种表情。分别为anger生气、disgust厌恶、fear恐惧、happy开心、sad伤心、surprised惊讶、normal中性。
(7) RAF(Real-world Affective Faces)
数据集地址:
http://www.whdeng.cn/RAF/model1.html。

发布于2017年,包含总共29672张图片,其中7个基本表情和12个复合表情,而且每张图还提供了5个精确的人脸关键点,年龄范围和性别标注。
(8) EmotioNet
数据集地址:
http://cbcsl.ece.ohio-state.edu/EmotionNetChallenge/。

发布于2017年,共950,000张图,其中包含基本表情、复合表情,以及表情单元的标注。
(9) AffectNet
数据集地址:
http://mohammadmahoor.com/affectnet/。
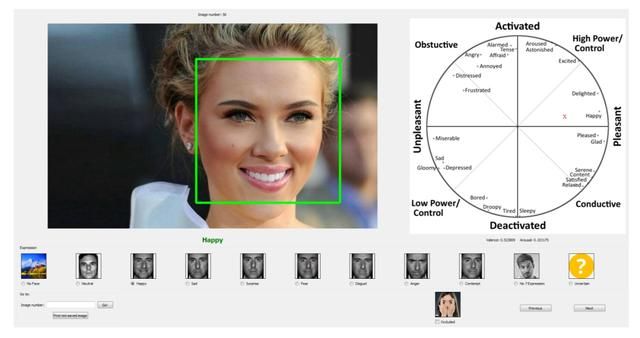
发布于2017年,数据集的采集使用6种不同语言的1250个关键词在搜索引擎中进行检索,最后超过42万张图。标注类型包括表情类型和幅度,其中表情类型包括中性表情(Neutral)、高兴(Happiness)、悲伤(Sadness)、惊讶(Surprise)、害怕(Fear)、厌恶(Disgust)、愤怒(Anger)、轻蔑(Contempt)等8种基本表情,以及无表情(None)、不确定(Uncertain)、无人脸(No-Face)。
表情识别目前的关注点已经从实验室环境下转移到具有挑战性的真实场景条件下,研究者们开始利用深度学习技术来解决如光照变化、遮挡、非正面头部姿势等问题,仍然有很多的问题需要解决。
另一方面,尽管目前表情识别技术被广泛研究,但是我们所定义的表情只涵盖了特定种类的一小部分,尤其是面部表情,而实际上人类还有很多其他的表情。表情的研究相对于颜值年龄等要难得多,应用也要广泛的多,相信这几年会不断出现有意思的应用。
4.3 人脸年龄与性别数据集
人脸的年龄和性别识别在安全控制,人机交互领域有着非常广泛的使用,而且由于收到妆造等影响,人脸的年龄估计仍然是一个难点。
(1) FGNet
数据集地址:
http://www-prima.inrialpes.fr/FGnet/html/benchmarks.html。
发布于2000年,这是第一个意义重大的年龄数据集,包含了82个人的1002张图,年龄范围是0到69岁。
(2) CACD2000
数据集地址:
http://bcsiriuschen.github.io/CARC/。

发布于2013年,这是一个名人数据集,包含了2000个人的163446张名人图片,其范围是16到62岁。
(3) Adience
数据集地址:
https://www.openu.ac.il/home/hassner/Adience/data.html#frontalized。
发布于2014年,这是采用iPhone5或更新的智能手机拍摄的数据,共2284个人26580张图像。它的标注采用的是年龄段的形式而不是具体的年龄,其中年龄段为(0-2、4-6、8-13、15-20、25-32、38-43、48-53、60+)。
(4) IMDB-wiki
数据集地址:
https://data.vision.ee.ethz.ch/cvl/rrothe/imdb-wiki/。

发布于2015年,IMDB-WIKI人脸数据库是由IMDB数据库和Wikipedia数据库组成,其中IMDB人脸数据库包含了460723张人脸图片,而Wikipedia人脸数据库包含了62328张人脸数据库,总共523051张人脸数据。都是从IMDb和维基百科上爬取的名人图片,根据照片拍摄时间戳和出生日期计算得到的年龄信息,以及性别信息,对于年龄识别和性别识别的研究有着重要的意义,这是目前年龄和性别识别最大的数据集。
(5) MORPH
数据集地址:
http://www.faceaginggroup.com/morph/。
发布于2017年,包括13000多个人的55000张图,年龄范围是16到77。
4.4 人脸分割数据集
人脸属性分割可以用于对人脸进行编辑以及辅助其他人脸相关的任务。
(1) Helen Parsing Dataset
数据集地址:
http://www.cs.wisc.edu/~lizhang/projects/face-parsing/。
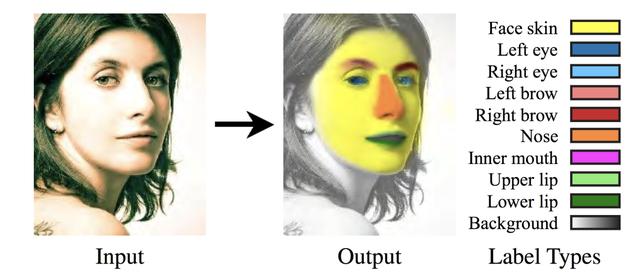
发布于2013年,Helen Parsing dataset是将关键点检测数据集Helen Dataset进行掩膜标注后得到的人脸图像分割数据集,包含2000张训练图像和330张测试图像。数据集共包含10类面部区域的标注,分别是Face skin、Left eye、Right eye、Left brow、Right brow、Nose、Inner mouth、Upper lip、Lower lip、Background,标注的方法是每一个类别都单独存储为一张图片。
(2) CelebAMask-HQ
数据集地址:
https://github.com/switchablenorms/CelebAMask-HQ。

发布于2019年,CelebAMask-HQ是从CelebA-HQ数据集中标注的30000张人脸属性分割数据集,其中图像大小均为512×512,包含19个类别,分别是skin、nose、eyes、eyebrows、ears、mouth、lip、hair、hat、eyeglass、earring、necklace、neck及cloth区域。
4.5 人脸颜值数据集
人脸颜值和吸引度在社交平台和图像质量评估上都有应用。
(1) SCUT-FBP5500
数据集地址:
https://github.com/HCIILAB/SCUT-FBP5500-Database-Release。
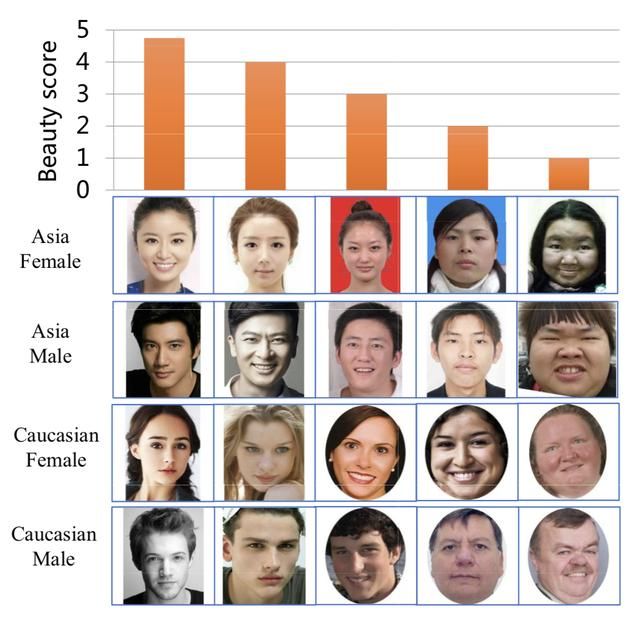
发布于2017年,数据集共5500个正面人脸,年龄分布为15-60,全部都是自然表情。包含不同的性别分布和种族分布(2000亚洲女性、2000亚洲男性、750高加索男性、750高加索女性),数据分别来自于数据堂,US Adult database等。每一张图由60个人进行评分,共评为5个等级,这60个人的年龄分布为18~27岁,均为年轻人。适用于基于表观和形状等的模型研究。同时,每一个图都提供了86个关键点的标注。
(2) Selfier
数据集地址:
https://www.crcv.ucf.edu/data/Selfie/。
发布于2015年,作者们从selfeed.com网站上收集了46,836张自拍图,然后标注了36种属性,分为以下组别,前面是属性,后面是具体的分类。
性别:is female。
年龄:baby、child、teenager、youth、middle age、senior。
种族:white、black、asian。
脸型:oval、round、heart。
脸部表情:smiling、frowning、mouth open、tongue out、duck face。
头发颜色:black、blond、brown、red。
发型:curly、straight、braid。
装饰:glasses、sunglasses、lip- stick、hat、earphone。
其他.:showing cellphone、using mir-ror、having braces、partial face。
光照条件:harsh、dim。
每一张图像都标注了受欢迎的分数,该数据集可以用于研究人脸属性与受欢迎程度之间的关系。
4.6 人脸妆造数据集
妆造在人脸图像中是普遍存在的,人脸的上妆与去妆,抗装造干扰的人脸识别也是一种具有挑战性的问题。
(1) YMU,VMU,MIW,MIFS等妆造数据集
数据集地址:
http://www.antitza.com/makeup-datasets.html。

发布于2012年,这是一个女性面部化妆数据集,可用于研究化妆对面部识别的影响。总共包括4个子数据集:
YMU(YouTube化妆):这是从YouTube视频化妆教程中获取的面部图像,YouTube网址为
http://www.antitza.com/URLs_YMU.txt。
VMU(虚拟化妆):这是将从FRGC数据库中采集的高加索女性受试者的面部图像,使用
公开的软件来合成的虚拟化妆样本,软件来自www.taaz.com。
MIW:从互联网获得有化妆和没有化妆的受试者的前后对比面部图像。
MIFS:化妆诱导面部欺骗数据集:这是从YouTube化妆视频教程的107个化妆视频中获取。每一组包含3张图片,其中一张图片是目标的化妆前的主体图像,一个是化妆后的,另一个是其他人化同样的妆试图进行欺骗的图片。
(2) 妆造迁移数据集
数据集地址:
http://liusi-group.com/projects/BeautyGAN。

发布于2018年,包括3834张女性人脸图,其中1115张无妆造人脸,2719张有妆造人脸。妆造类型包括不同程度的烟熏妆(smoky-eyes makeup style)、华丽妆(flashy makeup style)、复古妆(Retro makeup style)、韩式妆(Korean makeup style)及日式妆(Japanese makeup style)。
5. 人脸姿态与3D数据集
人脸的姿态估计在考勤,支付以及各类社交应用中有非常广泛的应用。三维人脸重建在大姿态人脸关键点的提取,表情迁移等领域有非常重大的研究意义,也是目前人脸领域的研究重点。
5.1 人脸姿态数据集
(1) Bosphorus Database
数据集地址:
http://bosphorus.ee.boun.edu.tr/default.aspx。
发布于2009年,这是一个研究三维人脸表情的数据集,通过结构光采集。包含105个人,4666张人脸,每一个人脸有35种表情以及不同的仿真姿态。
(2) BIWI
数据集地址:
http://www.vision.ee.ethz.ch/datasets/b3dac2.en.html。
发布于2010年,包含1000个高质量的3D扫描仪和专业麦克风采集的3D数据,其中14个人,6个男性,8个女性。采集以每秒25帧的速度获取密集的动态面部扫描。
(3) Head Pose Image
数据集地址:
http://www-prima.inrialpes.fr/perso/Gourier/Faces/HPDatabase.html。

发布于2013年,为灰度图数据集,在实验室采集,标注包括垂直角度和水平角度。包括5580张图,其中372个人,每个人15张图。
(4) BIWI kinect_headpose
数据集地址:
https://data.vision.ee.ethz.ch/cvl/gfanelli/head_pose/head_forest.html。
发布于2013年,使用kinect进行采集,包含20个人的15000张图片,有3D的标注,图片大小为640×480。

(5) TMU
数据集地址:www.facedbv.com。
发布于2015年,这是一个面部视频数据库,包含31500个100名志愿者的视频。每个志愿者在7个照明条件下由9组同步网络摄像头拍摄,并被要求完成一系列指定的动作,有不同的遮挡,照明、姿势和表情的面部变化。与现有数据库相比,THU人脸数据库提供了具有严格时间同步的多视图视频序列,从而能够对注视校正方法进行评估。
(6) UPNA Head Pose Database
数据集地址:
http://gi4e.unavarra.es/databases/hpdb/。
发布于2016年,10个人,其中6个男性,4个女性,每个人12个视频,6个规定的动作,6个自由的动作。分辨率1280×720,30fps,每一个视频10s,有3D标注信息。
5.2 人脸重建数据集
(1) Basel Face Model
数据集地址:
https://faces.dmi.unibas.ch/。
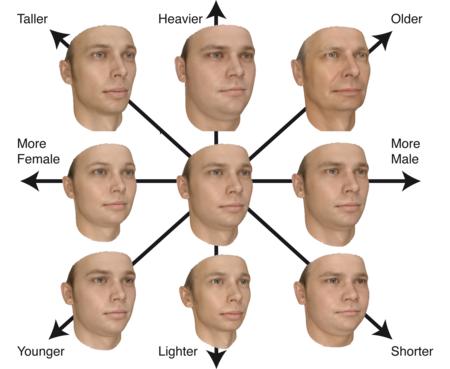
发布于2009年,这是使用3DMM模型构建的数据集,通过结构光和激光进行采集,未处理前每一个模型由70000个点描述,处理后由53490个点描述。在数据库的处理过程中,将所有模型的每一个点的位置都进行了精确的一一匹配,也就是说,每一个点都有实际的物理意义,可能有右嘴角,可能是鼻尖。
数据集包含100个男性和100个女性的3D扫描数据,是人脸三维重建领域影响最大的数据集,堪称3D人脸领域的“hello world”。在该数据集中,还标注了表情系数,纹理系数,68个关键点的坐标,以及相机的7个系数。
BFM数据集如今已经更新了多次,包括BFM2017,BFM2019,读者可以自行关注。
(2) FaceWarehouse
数据集地址:http://www.kunzhou.net/#facewarehouse。
发布于2014年,这是浙江大学周昆实验室开源的3D人脸数据集,与3DMM数据集的构建相似,不过数据集是中国人。共包含了150个人,年龄从7-80岁。相比于3DMM数据集,它增加了表情,每个人包含了20种不同的表情、1个中性表情、19个张嘴、微笑等表情。
其他的还有USF Human ID 3-D Database,ICT-3DHP database,IDIAP等,读者可以线下了解。由于3D数据集的构建代价很高,所以仿真数据集经常被使用,即通过从2D图像构建3D模型然后进行姿态仿真。当然另一方面,研究摆脱3D数据集的运用的方法也不断被提出,而且精度已经和基于3D数据集的方法可以比拼,因此这可能也是未来的重要研究方向。
(3) 300W-LP
数据集地址:
http://www.cbsr.ia.ac.cn/users/xiangyuzhu/projects/3DDFA/main.htm。
这是基于300W数据集和3DMM模型仿真得到的3D数据集,这是3D领域里使用最大,使用最广泛的仿真数据集,包含了68个关键点,相机参数以及3DMM模型的系数的标注。
6. 人脸活体与伪造数据集
在金融支付、门禁等应用场景,活体检测用来验证是否是真实的本人还是一张图片或者一段视频。随着当前人脸伪造技术的发展,伪造人脸图像的检测也是一个重要的问题。
6.1 人脸活体数据集
(1) NUAA
数据集地址:
http://parnec.nuaa.edu.cn/xtan/data/nuaaimposterdb.html
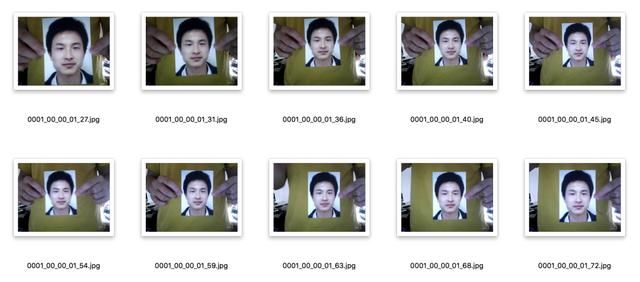
发布于2010年,这是一个重放攻击人脸数据集,包含15个人采集的照片。采集时使用20fps,对每一个正面人脸姿态和中性表情进行采集,每一个人采集500张图,分辨率大小为640×480,人脸图像采集使用了Canon相机,而伪造人脸则使用相机纸打印和A4纸打印,上图展示了一些样本。
(2) Replay-Attack Database
数据集地址:
https://www.idiap.ch/dataset/replayattack。
发布于2012年,这是一个重放攻击人脸数据集,包含50个人的1300个视频。所有的视频都是通过让一个(真正的)客户端试图通过内置的网络摄像头访问笔记本电脑或者通过显示同一客户端的照片或视频至少记录了9秒后生成,分辨率为320×240像素。
(3) 3DMask Attack
数据集地址:
https://www.idiap.ch/dataset/3dmad。
发布于2013年,包含了17个人的76500张图片,使用Kinect进行采集。每一个人采集了3组视频,前两组为真实视频,第三组掩码攻击图。
每一组视频包含了5个视频,每一个视频300帧,每个帧包括一幅深度图像、相应的RGB图像和手动标注的眼睛位置。其中每帧分辨率是640×480,包含8位rgb图像和11位深度图像,采集者姿态是正面,无表情。
(4) MSU USSA
数据集地址:
http://biometrics.cse.msu.edu/Publications/Databases/MSU_USSA/。
发布于2016年,这是一个活体检测数据集,包含9000张图片,其中1000张为真实图,8000张为伪造图,即非活体图。
(5) SiW
数据集地址:
http://cvlab.cse.msu.edu/siw-spoof-in-the-wild-database.html。
发布于2016年,这是一个活体检测数据集,包含165个人,每个人包含8段真实的视频,多达20段伪造的视频,总共4478个视频。视频的分辨率为1080p,帧率是30fps。
(6) WFFD
数据集地址:
https://arxiv.org/abs/1906.11900。
发布于2019年,这是一个3D人脸蜡像数据集,总共包含2200对真实人脸和蜡像人脸图。
(7) CASIA-SURF
数据集地址:
https://sites.google.com/qq.com/chalearnfacespoofingattackdete/。
发布于2019年,这是一个活体检测数据集,包括1000个人的21000个视频,数据集通过Intel RealSense SR300相机在不同的室内背景下采集得到,同时采集RGB、Depth和InfraRed(IR)视频。其中RGB图片分辨率1280×720,Depth和IR的分辨率为640×480。
每一个样本会录制一个真实视频以及6个攻击视频,攻击类型包括遮挡住眼睛、鼻子、嘴巴等区域。
6.2 人脸伪造数据集
(1) FaceForensics++
数据集地址:
https://github.com/ondyari/FaceForensics。

发布于2019年,这是一个伪造人脸数据集,使用了Face2Face、FaceSwap、DeepFakes及NeuralTextures共4种换脸算法对1000个真实视频进行处理,各自得到了510207张真假脸对应的图像。
(2) DFW
数据集地址:
http://iab-rubric.org/resources/dfw.html。
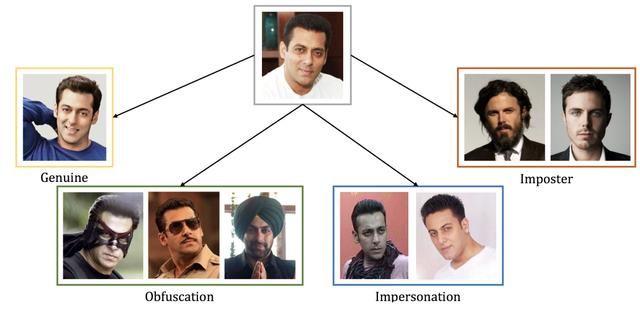
发布于2018年,包括1000人的11157张图片,它是IBM发布的一个人脸数据集,主要包括遮挡和伪造人脸。每一个人都有一张正脸图,其中903张人有一个验证图,两者构成正常的人脸验证对。所有1000个人都有一些包括妆造图,874个人有一些被识别成该人(故意的或者非故意的)的伪造图,最终总共1000张整成图、903张验证图、4814张妆造图、4440张伪造(另一个人)图。
除此之外还有一些其他较小的人脸伪造数据集,感兴趣的读者可以自行阅读更多。
7. 人脸风格化数据集
人脸的风格化在娱乐社交领域里有非常广泛的应用,是近些年的研究热点。
(1) CUFSF
数据集地址:
http://mmlab.ie.cuhk.edu.hk/archive/cufsf/。
发布于2009年,这是一个人像素描数据集,原图来自于FERET,有1195张成对的灰色正面肖像图和对应的素描图。
(2) IIIT-CFW1.0
数据集地址:
http://cvlab.cse.msu.edu/siw-spoof-in-the-wild-database.html。
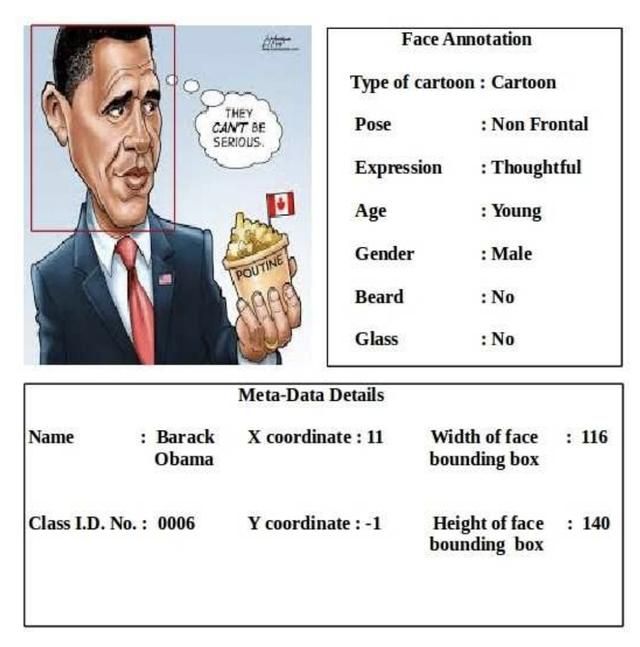
发布于2016年,包含100个名人的8928张卡通图片,同时也附带了1000张真实图。
(3) CartoonSet10/100k
数据集地址:
https://google.github.io/cartoonset/download.html。

发布于2017年,有两个子集,CartoonSet10k和CartoonSet100k,分别包含10000和100000张卡通人脸图。每一张卡通人脸图都有16个组件,其中12个面部属性和4个颜色属性。
其中颜色属性来自于一个离散的RGB集合,每一个属性的种类可以低至3种,高达11种。比如chin的长度就包括short、medium、long一共三种,而发型就有111种。所有属性及其集合大小统计如下:
艺术风格总共包括:3种下巴长度(chin_length)、3种眼睛角度(eye_angle)、2种睫毛可见与否属性(eye_lashes)、2种眼睑样式(eye_lid)、14种眉毛形状(eyebrow_shape)、2种眉毛宽度(eyebrow_weight)、7种脸型(face_shape)、15种面部发型(facial_hair,包括光头)、12种眼镜(glasses,包括无眼镜)、111种头部发型(head hair)。
颜色风格包括:5种眼虹膜颜色(eye_color)、11种面部皮肤颜色(face_color)、7种眼镜颜色(glasses_color)、10种头发颜色(hair_color)。
比例风格包括:3种眼睛眉毛距离(eye_eyebrow_distance)、3种眼缝大小(eye_slant)、4种眉毛厚度(eyebrow_thickness)、3种眉毛宽度(eyebrow_width)。
所有的元素及其变种都是由同一个艺术家Shiraz Fuman绘制而成,最终得到约250个卡通艺术元素,可以组合成约108种样式。所有的艺术元素都是采用顺序分层的方式方便进行渲染,比如脸型需要依赖于眼睛和眼睛,而发型比较复杂有两个元素,一个在人脸上一层,一个在人脸下一层,总共有8层,头发背景、人脸、头发前景、眼睛、眼睫毛、嘴巴、面部头发、眼镜。
从属性到艺术的映射也是有艺术家确定的,这样任意一个属性的选择都能获得视觉好看的效果,而不至于对不齐,有时候需要一些交互,比如不同脸型的“短胡子”属性的创作。
(4) self2anime
数据集地址:
https://github.com/taki0112/UGATIT。

发布于2019年,这是一个漫画人脸数据集,首先使用漫画人脸检测算法对Anime-Planet1上的图片进行了检测,最后留下了女性的人脸图共3500张,其中3400张作为训练,100张作为测试。
其他还有一些比较小和老的数据集,这里就不做过多的介绍,感兴趣的读者可以自行去了解更多。
8. 如何获取数据集
如果你对以上许多数据集感兴趣,在有三AI知识星球的数据集板块中,我们提供了以上各类数据集的详细解读以及下载方式,有需要的同学可以加入。
「知识星球」这几年人脸都有哪些有意思的新数据集被整理出来?
总结
本次我们给大家介绍了人脸相关的主要数据集,人脸图像属于最早被研究的一类图像,也是计算机视觉领域中应用最广泛的一类图像,其中需要使用到几乎所有计算机视觉领域的算法,可以说掌握好人脸领域的各种算法,基本就玩转了计算机视觉领域。
