奇异值分解(Singular Value Decomposition,SVD)的理解
1、特征向量
A为n阶矩阵,若数λ和n维非0列向量x满足Ax=λx,那么数λ称为A的特征值,x称为A的对应于特征值λ的特征向量。
式Ax=λx也可写成( A-λE)x=0,并且|λE-A|叫做A 的特征多项式。当特征多项式等于0的时候,称为A的特征方程,特征方程是一个齐次线性方程组,求解特征值的过程其实就是求解特征方程的解。
- 求特征值

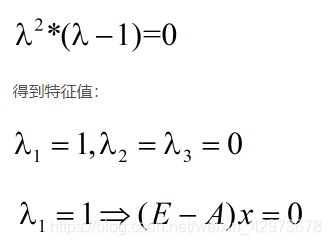
- 求特征向量
代入λ= 1求解有:

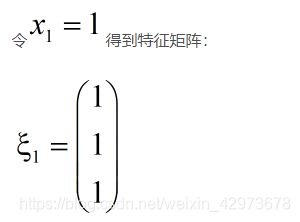
同理带入λ = 0 得特征向量
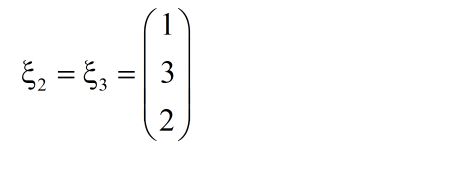
2、矩阵对角化
对于上节样例,令对角矩阵为D = diag(1,0,0), P = [ξ1,ξ2,ξ3],把P的每个列向量单位化,那么P就是一个正交矩阵。
那么矩阵A就可以表示为一个对角矩阵分别左乘一个正交矩阵P和右乘P的逆:
有A = PDP-1 = PDPT
P-1 的求解方式通过在矩阵的右边拼接一个同大小的单位矩阵,进行恒等变化,把左边变成一个单位矩阵,那么右边就是一个对应的逆矩阵。
但是如果一个矩阵是正交矩阵,那么它的逆等于它的转置,即P-1 = PT。
3、奇异值分解理解
假设M是一个m∗n的矩阵,如果存在一个分解
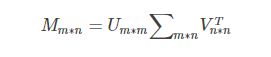
其中,U,V为正交矩阵,∑只有对角元素,其他元素都是0,而且∑的对角元素是从大到小排列的,这些对角元素称为奇异值,式中
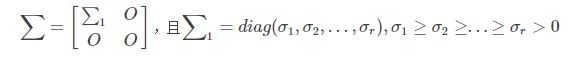
记住前面的假设,M = U ∑ VT, 故 MT = V∑ TUT
因为M不是对称矩阵,但是通过M和MT 相乘可以得到对称矩阵,如下
其中V是正交矩阵,所以VTV = E,同理UTU = E
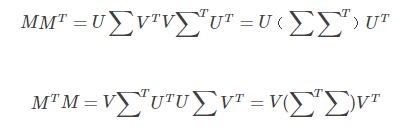
所以主要问题就变成了求解MMT 和 MTM 对角化的正交矩阵U和V。
∑ T∑ 可以看作是∑ 2,所以最后∑ 就是 MMT 的特征值的开方。
实例讲解

对B求解得对应的正交矩阵 U
![]()
同理可求得C对应的正交矩阵VT
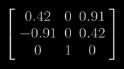
B,C有着共同的特征值对角矩阵

开方就是我们要求的对角矩阵∑ ,注意这里的形状跟W一样,特征值依次填充就行。

最后一步,可以分解成下面的计算过程:
即U ∑ VT = ∑ λiuiviT, 注意i的最大值为∑的行数。
其中ui为U的列向量,vi为V的列向量,所以每个uiviT 都是一个2x2的矩阵,在这个例子里。
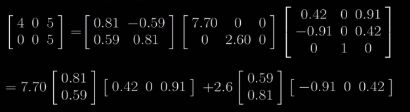
至于可以这样分解,最本质的原因是:
对于A∑, 其中A矩阵和对角矩阵∑的乘法等于列向量ai 和特征值λi的相乘。
矩阵相乘的本质有:
Amxn x Bnxm = ∑ Aci x Bri,累加所有A的第i个列向量和B的第i个行向量相乘的结果。其实每个Aci x Bri 都是一个mxm的矩阵
![]()
最后最重要的式子如上,其实λ的值越大,也就是紧跟其后的矩阵越重要,对于数据压缩,其实可以通过舍弃后面λ比较小的部分,有时那些比较小的部分去掉还可以起到除噪音的功能。
4、幂迭代法求特征值和特征向量(power iteration)
参考文章:https://www.cnblogs.com/fahaizhong/p/12240051.html

主特征向量(特征值最大对应的向量)求解代码:
import numpy as np
def power_iteration(A, num_simulations: int):
# Ideally choose a random vector
# To decrease the chance that our vector
# Is orthogonal to the eigenvector
b_k = np.random.rand(A.shape[1])
for _ in range(num_simulations):
# calculate the matrix-by-vector product Ab
b_k1 = np.dot(A, b_k)
# calculate the norm
b_k1_norm = np.linalg.norm(b_k1)
# re normalize the vector
b_k = b_k1 / b_k1_norm
return b_k
A = np.array([[2,1],[1,2]])
V = power_iteration(A, 100).reshape(1,-1)
print(V)
#array([[0.70710678, 0.70710678]])
特征值求法
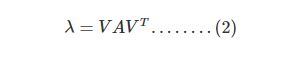
lbd = np.dot(V,np.dot(A,V.T))
# array([[3.]])
如果矩阵非方阵,需要有两个步骤:

给定矩阵A和迭代次数n,求主特征向量的过程,就是先求左正交矩阵U的主u向量,再求右正交矩阵V的主v向量,不断迭代,(注意u刚开始是随机初始化的)相比上面的代码,这里多了个v的求解过程。其实就是上文说的SVD的那两个正交矩阵的最大特征值对应的特征向量。
求次特征向量
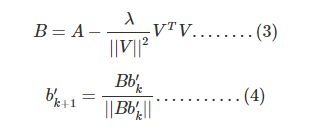
主要思想就是用A矩阵减去主特征向量构成的矩阵,得到B,然后对B进行幂迭代发求解B的主特征向量。
B = A - lbd / np.linalg.norm(V)**2 * np.dot(V.T,V)
V_2 = power_iteration(B, 100)
lbd1 = np.dot(V_2.T,np.dot(B,V_2))
print(lbd1)
#1.0000000000000002