目标检测中anchor那些事(一)
一、anchor是什么
anchor简单来说就是,按照一定的方式,在图片的各个位置上,生成长宽不一的box框,用来定位gt(ground truth)box,这种预设框就是anchor 框。示意图如下:
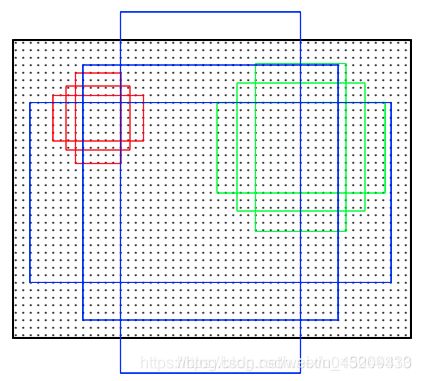
anchor框的生成一般是以feature map上的坐标点为锚点,滑窗式的生成,例如ssd中,产生ancor框的feature map有conv4_3、fc7、conv6_2、conv7_2、conv8_2、conv9_2共6个,如果输入图片的大小为300x300,那么以上6个feature map的大小分别为38x38, 19x19, 10x10, 5x5, 3x3, 1x1,每个中心点产生k个默认框,六层中每层的每个中心点产生的k分别为4、6、6、6、4、4。
那么ssd网络中,一共会产生38x38x4 + 19x19x6 + 10x10x6 + 5x5x6 + 3x3x4 + 1x1x4 = 8732个anchor 框。
二、anchor 框的大小
公式中m是使用feature map的数量(SSD 300中m=6):
s k = s m i n + s m a x − s m i n m − 1 ( k − 1 ) , k ∈ [ 1 , m ] s_k = s_{min} + \frac {s_{max} - s_{min}} {m-1} \left( k-1\right), k \in [1,m] sk=smin+m−1smax−smin(k−1),k∈[1,m]
其中,6个feature map各自的min_size, max_size如下
min_sizes = [30, 60, 111, 162, 213, 264]
max_sizes = [60, 111, 162, 213, 264, 315]
再用不同aspect ratio,用ar来表示 a = {1,2,3,1/2,1/3} 因此,默认包围盒的宽度和高度计算公式为:
w k a = s k a w^a_k = s_k\sqrt{a} wka=ska h k a = s k 1 a h^a_k = s_k \sqrt{\frac {1} {a}} hka=ska1
因此,在6个feature map上anchor框的大小分别是:
| feature map | anchor number | anchor sizes(输入图片的尺寸) |
|---|---|---|
| conv4_3 | 38x38x4=5776 | 30x30, 42x42, 42x21, 21x42 |
| fc7 | 19x19x6=2166 | 60x60, 81x81,84x42, 42x84, 103x34, 34x103 |
| conv6_2 | 10x10x6=600 | 111x111,134x134,156x78, 78x156, 192x64, 64x192 |
| conv7_2 | 5x5x6=150 | 162x162,185x185, 229x114, 114x229, 280x93, 93x280 |
| conv8_2 | 3x3x4=36 | 213x213, 237x237, 301x150, 150x301 |
| conv9_2 | 1x1x4=4 | 264x264, 288x288, 373x186, 186x373 |
三、anchor 框的工作机制
在SSD 300 中,一共有8732个anchor框,这些框与gt(ground truth)计算iou,根据iou的阈值,将8732个anchor框,分为正样本(一般iou>0.5),负样本(一般iou < 0.3),剩下的anchor框不使用,使用正样本和负样本直接进行做分类预测,正样本则做位置的偏移和缩放预测之后,预测目标框的位置。
训练过程中正负样本可视化图一如下(fish图):

原图大小为1280x720,上图中需要学习的目标是船上的鱼类,红色为每幅图片的gt框,蓝色为每幅图片的正样本anchor框,蓝色框上的数字,是正样本框与gt框的iou值,白色为每幅图片的负样本(采用难例挖掘)框,负样本数和正样本数的比例为3:1。
训练过程中正负样本可视化图二如下(airplane图):

上图的原始大小是2164x450,需要学习的目标是飞机,和汽车,同样,红色是gt框,蓝色是正样本框,绿色数字是正样本与gt的iou数值,白色是负样本框(同样使用难例挖掘)。
注意: 可以看到两个例图中,可视化iou的数据有的>1,这个是不合理的现象,这个是可视化手段,哪些iou>1的正样本,是在其原有的iou的数值上+1,用来和其他的正样本区别,这类正样本不是通过iou>0.5的手段筛选出来的,是8732个anchor框中,和该gt的iou最大的anchor框,这个anchor框的iou 不一定能够大于0.5,由于gt目标比较小,和该gt的有iou交集的anchor框整体iou数值比较小,如果只使用iou>o.5来筛选正样本,有些小目标的gt就没有对应的正样本,就会导致小目标的漏检。
四、训练过程中利用anchor中的正样本来逼近ground truth
边界框的回归包含四个值(cx,cy,w,h),加入anchor框的四个坐标值为 ( a c x , a c y , a w , a h ) (a^{cx},a^{cy},a^w,a^h) (acx,acy,aw,ah), ground gruth的四个坐标值为 ( g c x , g c y , g w , g h ) (g^{cx},g^{cy},g^w,g^h) (gcx,gcy,gw,gh),那么anchor与ground gruth之间的偏移量为 ( l c x , l c y , l w , l h ) (l^{cx}, l^{cy}, l^w, l^h) (lcx,lcy,lw,lh)为: l c x = g c x − a c x a w ∗ v a r i a n c e s [ 0 ] l^{cx} = \frac{g^{cx} - a^{cx}}{a^w * variances[0]} lcx=aw∗variances[0]gcx−acx l c y = g c y − a c y a h ∗ v a r i a n c e s [ 0 ] l^{cy} = \frac{g^{cy} - a^{cy}}{a^h * variances[0]} lcy=ah∗variances[0]gcy−acy l w = l o g ( g w a w ) v a r i a n c e s [ 1 ] l^w = \frac{log(\frac{g^w}{a^w})} {variances[1]} lw=variances[1]log(awgw) l h = l o g ( g h a h ) v a r i a n c e s [ 1 ] l^h = \frac{log(\frac{g^h}{a^h})} {variances[1]} lh=variances[1]log(ahgh)
网络中实际上预测 ( p c x , p c y , p w , p h ) (p^{cx},p^{cy},p^w,p^h) (pcx,pcy,pw,ph)来接近 ( l c x , l c y , l w , l h ) (l^{cx}, l^{cy}, l^{w}, l^{h}) (lcx,lcy,lw,lh),最终 l o s s = s m o o t h l o s s ( ( p c x , p c y , p w , p h ) , ( l c x , l c y , l w , l h ) ) loss = smoothloss((p^{cx},p^{cy},p^w,p^h), (l^{cx}, l^{cy}, l^{w}, l^{h})) loss=smoothloss((pcx,pcy,pw,ph),(lcx,lcy,lw,lh))
在三中的例子中,是利用红框和蓝框来计算lotion_loss
五、测试过程中使用anchor得到位置的预测
测试时,知道anchor的坐标 ( a c x , a c y , a w , a h ) (a^{cx},a^{cy},a^w,a^h) (acx,acy,aw,ah),通过网络得到了anchor到真实值之间的偏移量 ( l c x , l c y , l w , l h (l^{cx}, l^{cy}, l^w, l^h (lcx,lcy,lw,lh,那么网络估计的目标框的位置 ( p r e c x , p r e c y , p r e w , p r e h ) (pre^{cx},pre^{cy},pre^w,pre^h) (precx,precy,prew,preh): p r e c x = a c x + l c x ∗ v a r i a n c e s [ 0 ] ∗ a w pre^{cx} = a^{cx} + l^{cx} * variances[0] * a^w precx=acx+lcx∗variances[0]∗aw p r e c y = a c y + l c y ∗ v a r i a n c e s [ 0 ] ∗ a h pre^{cy} = a^{cy} + l^{cy} * variances[0] * a^h precy=acy+lcy∗variances[0]∗ah p r e w = a w ∗ l o g ( l w ∗ v a r i a n c e s [ 1 ] ) pre^w = a^w * log(l^w * variances[1]) prew=aw∗log(lw∗variances[1]) p r e h = a h ∗ l o g ( l h ∗ v a r i a n c e s [ 1 ] ) pre^h = a^h * log(l^h * variances[1]) preh=ah∗log(lh∗variances[1])
( p r e c x , p r e c y , p r e w , p r e h ) (pre^{cx},pre^{cy},pre^w,pre^h) (precx,precy,prew,preh)就是最终网络给出的位置值。
可视化图如下:

上图,黄色框是网络最终给出的位置坐标 ( p r e c x , p r e c y , p r e w , p r e h ) (pre^{cx},pre^{cy},pre^w,pre^h) (precx,precy,prew,preh),而黄色框是在蓝色框的基础上,由上述公式偏移而来的,蓝色框是我们预先设定的anchor框, ( a c x , a c y , a w , a h ) (a^{cx},a^{cy},a^w,a^h) (acx,acy,aw,ah)
六、anchor 尺寸与ground truth尺寸的分布的分析
本次统计的anchor的尺寸分布都是针对300x300的输入图片,下面的尺寸分布图,是实际应用中,两种不同的场景中,ground truth的尺寸分布,x坐标是框,y坐标是高。
fish图的gt尺寸分布以及anchor的尺度分布图如下:
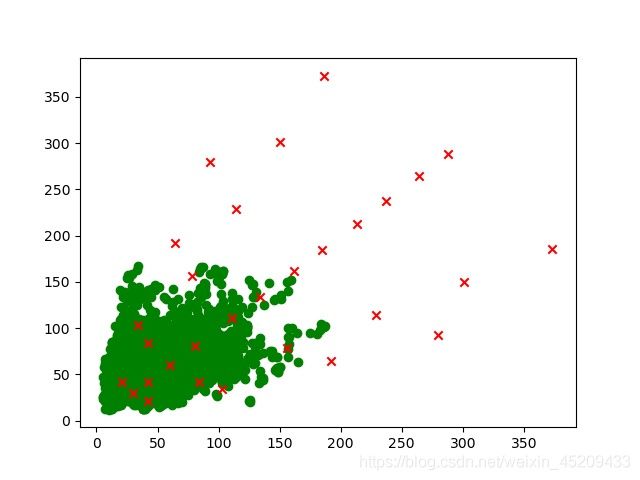
上图中,绿色圆是所有训练图片中,鱼类的尺寸分布(这里的尺寸是将原图缩放到300x300后的标注框的尺寸),红色×,是anchor框的分布。
airplane图的gt尺寸分布以及anchor的尺度分布图如下:
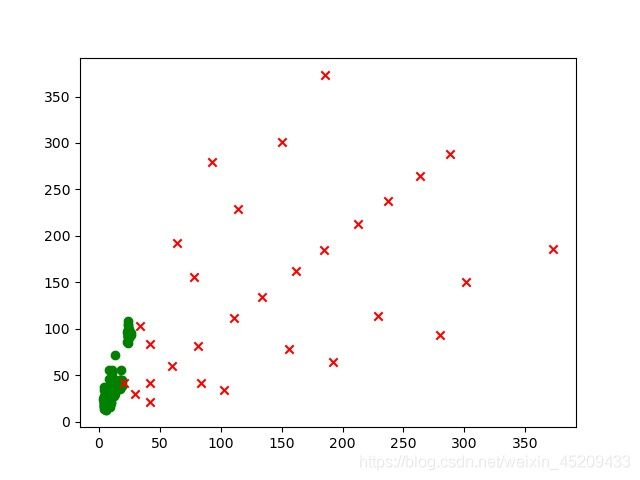
上图中,绿色圆是所有训练图片中,目标的尺寸分布(这里的尺寸是将原图缩放到300x300后的标注框的尺寸),红色×,是anchor框的分布。
可以观察到,论文中的anchor的尺寸其实比较符合voc数据的学习特征,在我们实际的学习过程中,实际需要学习的目标的尺寸的分布有各自的特点,直接使用论文中的anchor尺寸,会发现得到的正样本的质量差(平均iou低,从airplane的例子中可以看到,小目标对应的正样本只有一个,并且iou值在0.2左右),数量少,这样的正样本不利于网络的学习。