group by 后面 order by 失效问题
条件:
查询出学生最后一次的成绩。
全部数据显示:
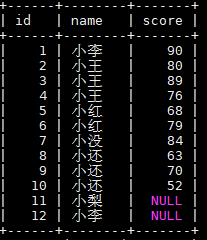
mysql5.6
使用sql:
select a.score,a.name from ( select * from hehe order by id desc ) a group by a.name;
结果:
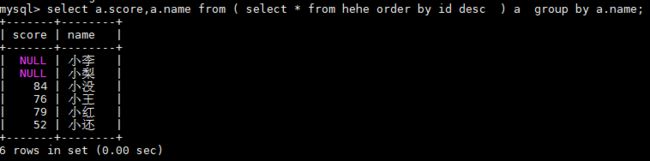
mysql5.7
使用同样语句:
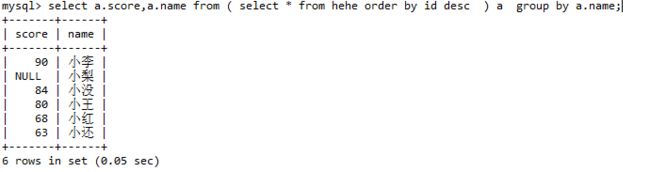
可以看出order by失效了
5.7官方手册给出:
It must not have ORDER BY with LIMIT.
他们说order by 如果没有加limit 就会失效
加上limit:
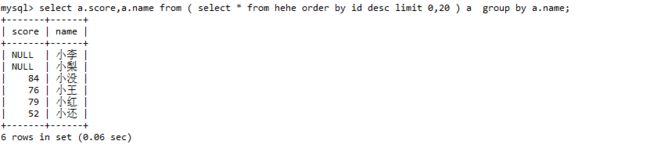
可以了
第二种方法:
使用:substring_index 和concat_group函数
5.6 5.7均可
SELECT SUBSTRING_INDEX(GROUP_CONCAT(score ORDER BY id desc),',',1) as score,name from hehe group by name;
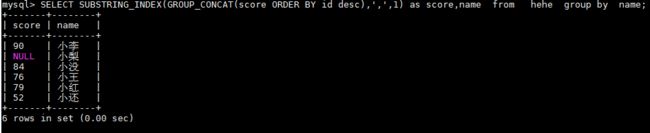
小李的是90 上一个是null concat_group 把小李最新成绩为null的过滤掉了 大家根据情况使用
简单介绍下substring_index:
substring_index(str,delim,count)
说明:substring_index(被截取字段,关键字,关键字出现的次数)
concat_group
一、concat()函数
功能:将多个字符串拼接成一个字符串
语法:concat(str1,str2,…)
返回结果为连接参数产生的字符串 如果有任何一个参数为NULL 则返回值NULL
select concat(name,score) from hehe;

select concat(period,',',award) as info from collect_ahsyxw;
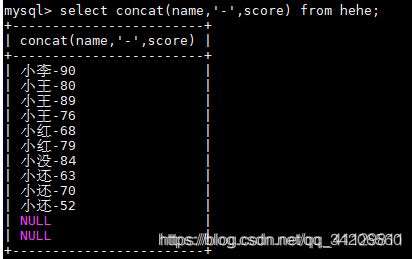
注:-符号 如果参数多的话 需要更多的-符号 因此需要concat_ws()
二、concat_ws()函数
功能:一次性指定分隔符
语法:concat_ws(separator,str1,str2,…)
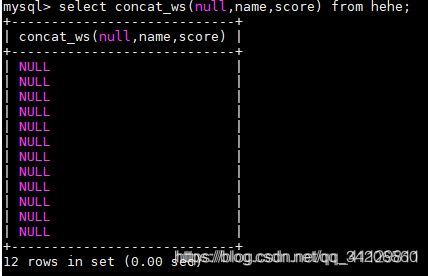
说明:第一个参数指定分隔符 分隔符不能为空 如果为NULL 则返回值NULL
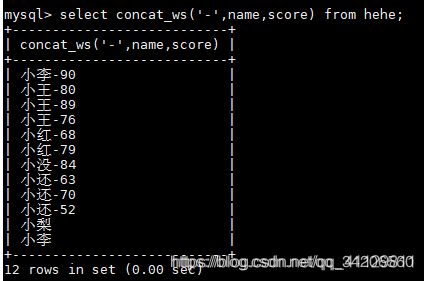
select concat(',',name,score) from hehe;
select concat_ws(null,name,score) from hehe;
三、group_concat()函数
序:在有group by查询语句中 select指定的字段要么包含在group by语句后面 作为分组的依据
要么就包含在聚合函数中
例子:
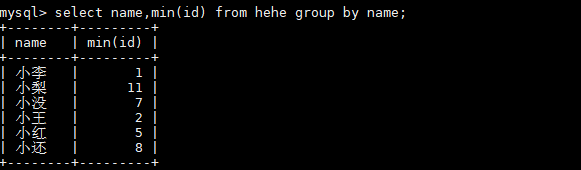
select name,min(id) from hehe group by name;
select id,name from hehe order by name;

1.功能:将group by产生的同一个分组中的值连接起来 返回一个字符串结果
2.语法 group_concat([distinct]要连接的字段 [order by 排序字段 asc/desc][separator’分隔符’])
说明:通过使用distinct可以排除重复值 如果希望对结果中的值进行排序 可以使用order by子句 separator是一个字符串值
缺省为一个逗号
举例:
使用group_concat()和group by显示相同名字的人的id号

举例:
将上面的id号从小到大排序 且用’_'作为分隔符:

举例:以name分组的所有组id和score
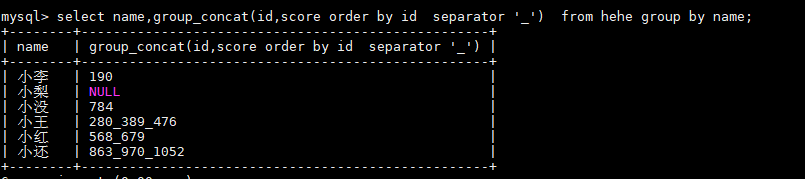
id和score连在一起 看的不是那么直观 使用concat_ws() 对每组中的id,score进行分割
