基于MLP的文本分类详解笔记(新手入门向:模型细节+数据集+PyTorch代码一文同时入门文本分类和MLP方法)
基于MLP的文本分类详解笔记(新手入门向:模型细节+数据集+PyTorch代码一文同时入门文本分类和MLP方法)
written by 魏福煊 谢天宝 from Harbin Institute of Technology
(BERT可给咱羡慕坏了,所以咱也为MLP找个icon叭,我觉得"My Little Pony"是个好主意)
Intro
前馈神经网络是一种文本表示的最简单的深度学习模型。然而其却在很多的文本分类的任务上取得了很高的准确度。这些使用前馈神经网络的模型的一大特点就是将文本视为词袋(a bag of words)。对于每一个单词,他都会通过一个嵌入层(例如word2vec、Glove)学到一个向量化的表示,之后将这个句子的每一个单词得到的向量化表示加和或者取平均数作为这个句子的表示,将其传递通过一个或者多个的前馈神经网络层(这多个神经网络层也被称作多层感知机),之后在最后一层使用一个分类器如logistic回归、朴素贝叶斯(Naive Bayes)、支持向量机(SVM)进行分类判断出文本的类型。
深度平均网络-DAN
一个基于该网络的很有名的例子就是深度平均网络–DAN(Deep Average Network)了。其结构如图所示,将句子中的词汇的嵌入层取出,取平均值,然后送到多层感知机中,最后在softmax层进行分类预测。

尽管DAN看着十分简单,“旦”他却可以超过很多更加复杂的号称能够获取文字位置信息的模型。
Joulin等人受到DAN的影响,在2016年提出了一个很简洁却有效的模型,也就是大名鼎鼎的fastText,和DAN一样,fastText也把一句话看作了一个词袋,但是不同的是,fastText使用的是n-grams的词袋作为附加的特征去获取到了一些局部的词与词之间的顺序,而这在实际中非常的有效,甚至比有些显式地使用词词之间顺序的模型还更加有效。
我们下面摘录知乎上了一些人对于DAN效果的评价:
“因为句子长度不固定,所以一般是用Bag-of-Word-Vectors 简单将词向量相加,然后使用MLP,这个方法比较简单,然后训练速度比较快,得到的结果也不是很差。只是没有利用到上下文信息。”
“DNN做文本任务一般是先对于输入句子进行分词,然后做成BoW特征(对句子里面出现的词的embedding直接相)。之上再堆叠上几层隐层,对这些embedding做非线性变化和融合大体上类似于关键词的提取和分类。在做证据的分类(例如证据的情感识别,泛黄识别等等)时候,句子里面的几个词基本可以决定证据的类别,因此在有样本的标注数足够的情况下是可以得到很不错的效果的。我做过的几个项目里面,根据业务需求不同,词典大小一般是10w~100w的级别,embedding取128或256维,整个神经网络的参数量基本在千万到过亿的级别,而且训练速度和预测速度都非常快,适合对响应时间要求非常严苛的线上任务”
“但DNN在效果上也有一些短板。首先,由于其输入时对于embedding求和,所以单个比较有判另能力的关键词(例如情感分析任务中的差评)有可能在这个和式里被大量其他 embedding 所淹没即使其他词可能与任务关联不大、 embedding 的 scale 也比较小。从直观意义上说,一段文本如异词太多,那么对其整体分类自然会比较困难,而且噪声也相应增多。但更严重的问题是,在一些了本任务里,词的顺序非常重要。例如在判断语义相关性中,“北京到上海的机票"与"上海到北京的机票”,其 BoW 特征完全一样,用 DNN 模型肯定会被判为完全相关,但事实上这是两个截然相反的东西。另外, DNN 的输入特征是分词后的词的 embedding 求和,因此其最终效果非常依赖分类器的效果。在实际应用中,有的人物事件衰减特性十分显著,分词器更新不够快的话非常容易拉低DNN的效果。”
言而总之,MLP无法捕捉单词之间的序列关系,进而效果不如基于CNN,RNN的模型。但是其模型简单,参数需求量不大,更适用于快速上线且容忍牺牲一定准确度的项目。
抛砖引玉-Doc2vec
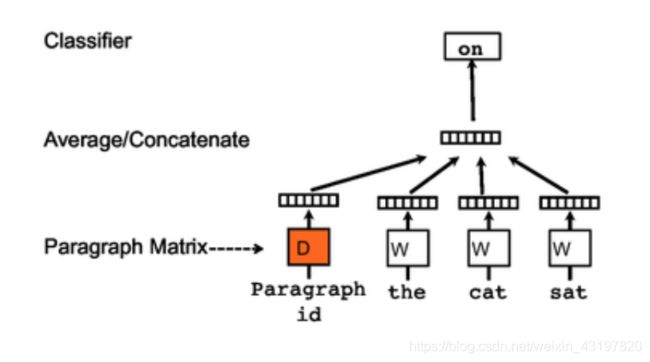
Le和Mikolov在2014年提出了doc2vec,它使用无监督算法来学习可变长度文本片段(如句子、段落和文档)的固定长度特征表示。如图2所示,doc2vec的架构类似于连续单词包(CBOW)模型。唯一的区别是附加的段落标记通过矩阵映射到段落向量D。在doc2vec的例子中,这个向量与三个单词的上下文的连接或平均值被用来预测第四个单词。段落向量表示当前上下文中缺失的信息,可以作为段落主题的记忆。经过训练后,将段落向量作为段落的特征(例如,代替或补充BoW),并输入分类器进行预测。Doc2vec在发表时在多个文本分类和情感分析任务上取得了良好的效果。感兴趣的同学可以在GitHub上找到相关的代码。
Practice
下面我们使用pytorch架构实战一下DAN模型。
这个网址是我们实现的代码,也是本文所依托的代码,希望能有所帮助(70% by&&forked from Eric,wfx, yyds!):
https://github.com/Timothyxxx/Text-classification
也欢迎随时与我们联系:
从数据集说起,有关SST-2
SST数据集:斯坦福大学发布的一个情感分析数据集,主要针对电影评论来做情感分类,因此SST属于单个句子的文本分类任务(其中SST-2是二分类,SST-5是五分类,SST-5的情感极性区分的更细致)。这里提供一个nlp所有数据集的介绍:关于文本分类(情感分析)的英文数据集汇总。官方下载地址:https://nlp.stanford.edu/sentiment/index.html

SST-2:我们要在练习中使用的数据集是SST-2。SST-2包含着电影评价的句子,每一个都被标记成要么积极正面(数字为1),要么消极负面(数字为0)。

模型-白话深度平均网络DAN
下面的图是制作的一个模型总览:每一个词汇通过我们维护的“序号-词列表”得到序号,进入嵌入层(embedding layer);之后通过嵌入层得到每一个词的“词向量”(embedding vector);再将这些词向量取平均值;再通过多层感知机(Multilayer Perceptron,缩写MLP)得到分类的结果。
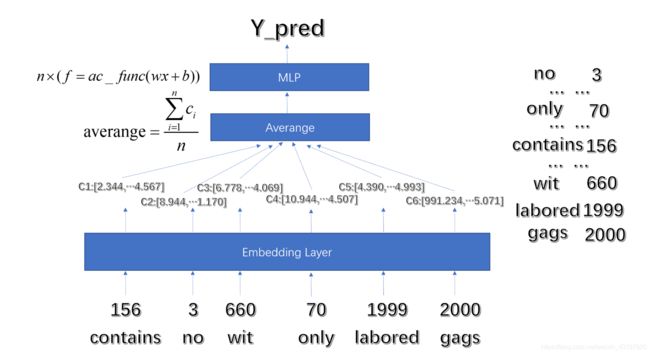
这个模型看起来很简单,但是由于这是我们第一次采用PyTorch框架实现论文的网络结构,我们在实现的过程中也是踩了很多的坑,包括一些模块之间的“度”的把握和一些容易被新手忽视的细节,悟已往之不鉴,知来者之可追,下面我们就一一记录一下,希望对您有所帮助。
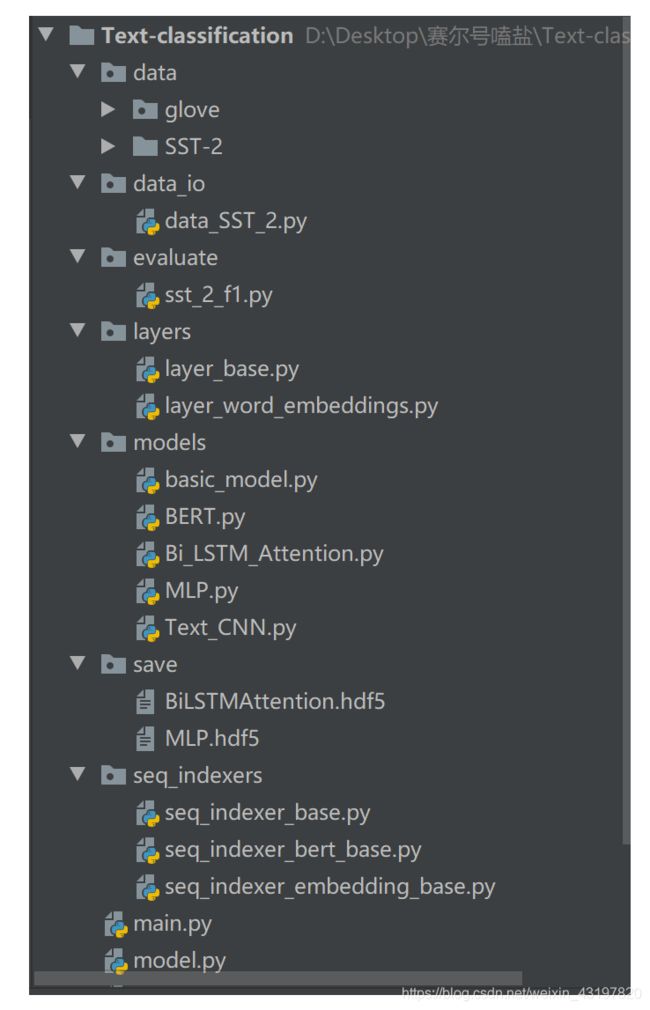
先放一下代码的整体目录结构(初代):

完整版目录结构:
架构—四步走之间的制衡
DAN的论文里面描述的很简单,就是说我们把句子里面的embedding拿出来,然后取一个平均值,再输入到一个MLP(也就是前馈神经网络)中,最后得到结果。听起来很简单,但实际上简单的是网络结构,针对于文本分类的io,嵌入层数据的读入等等配套操作却丝毫不少,操作过程中,我们是从零开始,所以还要考虑更多的细节。
我们先来明确四步走的分工(通过阅读大量代码吸取了一定经验,将原有的四步走略作调整,增强了一定的未来扩展能力)
**loader(io)部分:**仅仅负责从文件中读取、管理原始数据。用于在训练时获取x、y经过打包分批次加载进来的数据。
**layer&&model(module)部分:**仅仅负责实现神经网络的结构。
indexer(process)部分:仅仅负责编码,包括将建立词与下标的对应关系,建立下标与embedding向量的对应关系等等。
**train部分:**仅仅负责建立网络,并且联系输入参数进行循环训练,展示训练进程等。
如何清晰而快速的hold住模型、搭建模型?
(下文所涉及到的所有的batch_num其实用batch_size更好理解,意思是一个batch里面的数据数量)
根据我们半个月搭建模型的经验:最快最好的办法是先想好模型中的数据流。这里说的数据流动的意思,其实就是在说数据的维数变化,每一步的维数是什么,经过一个层,维数是怎么变的。这里大家可以看看这篇文章,参考它维度变化的思路:中文文本分类实战
按照这个思路,我们来捋一下数据流维度变化(如果有任何地方您觉得有遗忘请参考上一小节的模型,如果有任何涉及一些细节知识地方我都会指出在本文的哪个位置您可以看到):
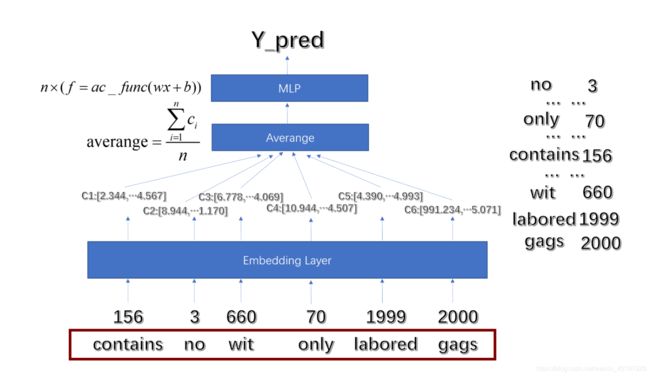
加载与输入----[batch_size,seq_len]
输入的维度:[batch_num,seq_len]
具体实现我们要联系好DataLoader,add_padding。dataloader带来的第一个维度batch_num好理解,也就是我们每次加载进来一批句子,第二个维度的seq_len代表着这一批句子里面的最长长度,而我们为了训练,将所有的句子都pad成了这个长度(一会会讲)。举例说明,我们在batch_size为4这一批次里面读入4个句子,分别为"i was admitted by HIT"、“I was so happy”、“I worked really hard”、“I joined SCIR”。那么我们读入加分词,初步就可以得到数据:
[[‘i’,‘was’,‘admitted’,‘by’,‘HIT’],
[‘i’,‘was’,‘so’,‘happy’],
[‘I’,‘worked’,‘really’,‘hard’],
[‘I’,‘joined’,‘SCIR’]]
注意维数,实际上现在第二个维度是参差不齐的,还不能投入训练。
所以我们要经过一个pad的过程,按照最大长度进行padding,进而得到:
[[‘i’,‘was’,‘admitted’,‘by’,‘HIT’],
[‘i’,‘was’,‘so’,‘happy’,’’],
[‘I’,‘worked’,‘really’,‘hard’,’’],
[‘I’,‘joined’,‘SCIR’,’’,’’]]
经过padding之后,我们就得到了一个[batch_size,seq_len]对齐的“list of list”了。
序号化----[batch_size,seq_len]
我们在这一步将单词和序号一一对应,利用下一节要介绍的indexer。
接着上面的例子继续说,比如说我们初始化indexer建立了一个词表如下:(代表pad用的占位符,代表未知的字符)
| index | word |
|---|---|
| 0 | |
| 1 | |
| 2 | i |
| 3 | was |
| 4 | admitted |
| 5 | by |
| 6 | HIT |
| 7 | so |
| 8 | happy |
| 9 | worked |
| … | … |
然后我们就可以将整个list of list转化为
[[2,3,4,5,6],
…](多的我就没写了,总之就是都变成数字了)
进而变成了一个维数为[batch_size,seq_len]的矩阵

通过嵌入层,获得词向量----[batch_size,seq_len,embedding_dim]
[‘I’,‘worked’,‘really’,‘hard’,’’],
[‘I’,‘joined’,‘SCIR’,’’,’’]]
接下来,我们就要通过一个embedding层,将每一个词转化成对应的词向量,这个词向量的维度取决于如果你是载入的化,就是载入的维度,如果你是训练的话,就是设置的维度。我们将词向量的维度记作embedding_dim。
经过这一层,数据的维数变为了,[batch_size,seq_len,embedding_dim](每个词额外生成了一个维度)
例子我们在后面的embedding章节会专门举例。有一些关于PyTorch和embedding的细节也会在后面讲到。其实学习过的同学都知道,实际上embedding就是根据标号索引的一个矩阵的一行,embedding说白了就是一个二维矩阵而已,维数为[total_word_num,embedding_dim],即行数为词典中总共的词数,列数为嵌入层的维数。使得每一个词(代表所有剩下的词)都有对应的向量即可。那么实际上经过embedding,也就是乘上一个[total_word_num,embedding_dim]。即[batch_size,seq_len]×[total_word_num,embedding_dim]–>[batch_size,seq_len,embedding_dim]。

词向量求平均,获得词向量均值----[batch_size,embedding_dim]
我们注意到通过embedding之后,每一个词都有embedding,(包括),我们下一步需要取平均值,但是不能直接将维数压缩,因为我们压缩之后是将一个batch中的非最长序列长度的句子也算上了,会使得整体值偏少,所以为了保证精确,我们要传入每一个具体句子的length,length的维数是[batch_num,1],之后我们也是将所有句子加和然后除以长度的数据,具体请参看代码。

将求得的平均的词向量投入到MLP中,进行分类----[batch_size,feat_num]
这一步进行一次线性变换,因为我们使用的是PyTorch的交叉熵的criterion,所以经过一次线性之后就可以直接输出了。

至此,模型数据维数流各个阶段的变化介绍完毕,相信代码能力强的同学以后可以仅仅通过看论文就把这一步内化于心,快速复现论文。接下来我们把一些很有意义的细节处理单拎出来作为专题讲一下。
建立indexer,读入看见的词,并维护词典(UNK怎么处理?)
nlp任务不可避免地要和词,句子打交道。代码处理后,词即标号,句子即标号的列表。怎么实现呢?我们需要建立一个indexer,完成对于词汇的打标号工作,这个工作其实就包含了加载入已知词汇和获取已知或者未知词汇的编号等过程。重点就是要实现indexer的add_instance和get_index这两个函数,进而实现“句子”到“标签列表”的转化。当然,作为抽象的indexer,它不仅仅可以为输入数据打标签,也可以为输出数据打标签(比如文本标注中不同的labels)
其实我们就是在维护一个双向词典的结构(具体实现为了省空间会使用dict加list)每次读入一句话就把新的词加入到词典中,并且给予编号,便于随时转化。
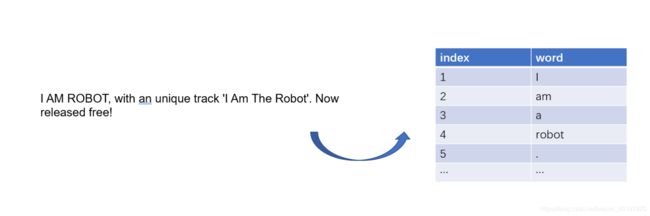
对于add_instance函数,
- 如果是输入是元组或者列表则递归调用,这样可以很简洁地同时加入多个词汇。
- 注意代码的最后两行添加新词汇和标号有一个小小技巧,非常简洁。
def add_instance(self, instance):
""" Add instances to alphabet.
1, We support any iterative data structure which
contains elements of str type.
2, We will count added instances that will influence
the serialization of unknown instance.
:param instance: is given instance or a list of it.
"""
if isinstance(instance, (list, tuple)):
for element in instance:
self.add_instance(element)
return
# We only support elements of str type.
assert isinstance(instance, str)
# count the frequency of instances.
self.__counter[instance] += 1
if instance not in self.__index2instance:
self.__instance2index[instance] = len(self.__index2instance)
self.__index2instance.append(instance)
对于get_index函数,
- 我们同样可以利用递归的技巧使得函数即支持单个元素,也支持列表构成的结构,
- 而且注意代码中对于要获取到的未知单词的标号的处理,试用了字典索引引发的异常进而进行下一步的选择。
def get_index(self, instance):
""" Serialize given instance and return.
For unknown words, the return index of alphabet
depends on variable self.__use_unk:
1, If True, then return the index of "";
2, If False, then return the index of the
element that hold max frequency in training data.
:param instance: is given instance or a list of it.
:return: is the serialization of query instance.
"""
if isinstance(instance, (list, tuple)):
return [self.get_index(elem) for elem in instance]
assert isinstance(instance, str)
try:
return self.__instance2index[instance]
except KeyError:
if self.__if_use_unk:
return self.__instance2index[self.__sign_unk]
else:
max_freq_item = self.__counter.most_common(1)[0][0]
return self.__instance2index[max_freq_item]
如何加载embedding_vector
我们往往不会从头训练一个emedding层,而是选择直接从文件中获取一个embedding,而这就要求我们对于导入embedding与PyTorch中embedding层的使用有熟练的掌握。首先我们先从下图理解一下,实则加载就是从文本中读取词和词向量,将词和对应的下标加入到dict中,将词向量存放到list中,(注意一比一的关系和预先存入的和及其对应的全零emb和随机数emb),形成一个word—index—embedding_vector的整体。

接下来,对于PyTorch的embedding层,我们要知道的是,首先其实内部核心就是一个(vocabulary_size,embedding_dim)的矩阵,输入一个indexer生成的维数为(batch_size,max_seq_len)的“标号列表”(注意,embedding就是靠标号读出的,所以一定不要错位),就可以返回来一个(batch_size,max_seq_len, embedding_dim)的拓展出词向量的数据了。
由于词,标号,词向量具有高度一致性,所以我们创建了一个seq_indexer_embedding_base类(刚刚的indexer的子类),负责从文件中加载词,加入词典,并且将其对应的词向量加载到维护的list中,因为使用了一个dict(词和索引)和emd_list,我们要时刻保证他们的长度相同一致,否则会出现错位的“训练个寂寞”的效果。embedding代码如下。
from seq_indexers.seq_indexer_base import SeqIndexerBase
import numpy as np
import torch
class SeqIndexerBaseEmbeddings(SeqIndexerBase):
def __init__(self, name, embedding_path, emb_dim, emb_delimiter):
super(SeqIndexerBaseEmbeddings, self).__init__(name=name, if_use_pad=True, if_use_unk=True)
self.path = embedding_path
self.embedding_vectors_list = list()
self.emb_dim = emb_dim
self.emb_delimiter = emb_delimiter
## Notice here that due to we set the if_use_pad and if_use_unk to true which means we added their
## signal to the instances ,so we have to also add their embeddings to the embedding vectors'list to
# maintain the equality of the total-number between them
#
self.add_emb_vector(self.generate_zero_emb_vector())
self.add_emb_vector(self.generate_random_emb_vector())
def load_embeddings_from_file(self):
"""
load embedding vectors from the file.
:return:
"""
for k, line in enumerate(open(self.path,encoding='utf-8')):
values = line.split(self.emb_delimiter)
self.add_instance(values[0])
emb_vector = list(map(lambda t: float(t), filter(lambda n: n and not n.isspace(), values[1:])))
self.add_emb_vector(emb_vector)
if(k%250000==0):
print("read " + str(k) + " words")
def generate_zero_emb_vector(self):
if self.emb_dim == 0:
raise ValueError('embeddings_dim is not known.')
return [0 for _ in range(self.emb_dim)]
def generate_random_emb_vector(self):
if self.emb_dim == 0:
raise ValueError('embeddings_dim is not known.')
return np.random.uniform(-np.sqrt(3.0 / self.emb_dim), np.sqrt(3.0 / self.emb_dim),
self.emb_dim).tolist()
def add_emb_vector(self, emb_vector):
self.embedding_vectors_list.append(emb_vector)
def get_loaded_embeddings_tensor(self):
return torch.FloatTensor(np.asarray(self.embedding_vectors_list))
结合embedding_indexer构造embedding层
我们结合embedding的indexer,构造mebedding层,注意我们可以使用torch的torch.nn.Embedding.from_pretrained(embeddings=…, freeze=…),直接加载indexer的embedding矩阵,进而我们需要扔进去indexer作为参数。
import torch
from seq_indexers.seq_indexer_embedding_base import SeqIndexerBaseEmbeddings
from layers.layer_base import LayerBase
class LayerWordEmbeddings(LayerBase):
def __init__(self, embedding_indexer:SeqIndexerBaseEmbeddings, gpu, freeze_word_embeddings=False):
super(LayerWordEmbeddings, self).__init__(gpu)
self.word_seq_indexer = embedding_indexer
embedding_tensor = embedding_indexer.get_loaded_embeddings_tensor()
if(gpu >= 0):
embedding_tensor = embedding_tensor.cuda(device=self.gpu)
self.embeddings = torch.nn.Embedding.from_pretrained(embeddings=embedding_tensor, freeze=freeze_word_embeddings)
def forward(self, word_sequences):
input_tensor = self.tensor_ensure_gpu(word_sequences) # shape: batch_size x max_seq_len
word_embeddings_feature = self.embeddings(input_tensor) # shape: batch_size x max_seq_len x output_dim
return word_embeddings_feature
传入lengths-DAN模型的核心代码
前面铺垫的已经差不多了,DAN其实模型本身没什么啦。
唯独需要注意的地方是我们每一次的前向传播,都需要给予这一次输入序列的长度以便取平均值(因为由于我们会把一个batch里面的不对齐元素padding掉,所以我们需要序列原有长度作为参数)
import torch
import torch.nn.functional as F
from seq_indexers.seq_indexer_embedding_base import SeqIndexerBaseEmbeddings
from layers.layer_word_embeddings import LayerWordEmbeddings
class MLP(torch.nn.Module):
def __init__(self, embedding_indexer: SeqIndexerBaseEmbeddings, gpu, feat_num):
super(MLP, self).__init__()
self.embeding = LayerWordEmbeddings(embedding_indexer, gpu)
self.linear1 = torch.nn.Linear(embedding_indexer.emb_dim, 50)
self.linear2 = torch.nn.Linear(50, feat_num)
self.act_func = torch.nn.LeakyReLU()
if(gpu >=0):
self.cuda(device=gpu)
def forward(self, words, lens : torch.Tensor):
words = self.embeding(words)
words = torch.sum(words, dim=1, keepdim=False) / lens.unsqueeze(-1)
words = self.linear1(words)
words = self.act_func(words)
words = self.linear2(words)
words = self.act_func(words)
return words
如果上述代码有任何含义不清楚,可以查看相关的文档;如果是对于过程的不清楚,可以再次查看我们上面的图解部分:
PyTorch中文文档
训练-有关不对齐与padding
训练的核心代码如下所示:
我们讨论一个很重要的处理问题:add_padding。因为在训练过程中,我们取出来的一个batch里面的各个句子的长度实际上是不尽相同的,所以我们需要将所有的句子的长度都padding到这些句子里面的最大值。出于为了以后packed_pad_sequence的复用,我们先排序,再padding。我们在train中调用了完成这一工作的add_padding函数,我们接下来讲讲。
for x, y in tqdm(train_loader):
padded_text, [sorted_label], seq_lens = dataset.add_padding(
x, [(y, False)]
)
## Transfer the texts and the labels --->index---->tensor
padded_text = seq_indexer.get_index(padded_text)
sorted_label = label_indexer.get_index(sorted_label)
padded_text = torch.LongTensor(padded_text)
sorted_label = torch.LongTensor(sorted_label)
seq_lens = torch.LongTensor(seq_lens)
if (args.gpu >= 0):
padded_text = padded_text.cuda()
sorted_label = sorted_label.cuda()
seq_lens = seq_lens.cuda()
if args.model == 'DAN':
y = model(padded_text, seq_lens)
if args.model == 'TextCNN':
y = model(padded_text)
loss = criterion(y, sorted_label)
loss.backward()
optimizer.step()
train_loss += loss.item()
optimizer.zero_grad()
其实add_padding函数还是很直接的,不过它带着的参数带着方括号大家一看可能会觉得有些奇怪,但其实在仔细读源码之后细品会发现,这是一种增强扩展性和灵活度的使用技巧。同时值得注意的是,因为我们重新索引排列了输入的text的,所以labels也必须要跟着一起重新索引排列作为返回值(labels也可以拓展到很多其他的函数,方括号内的元素都会随着texts的顺序改变而追随)。
@staticmethod
def add_padding(texts, items=None, digital=False):
"""
Sorting by the length and add padding to the texts and the items(items could be the y values or else)
:param texts: a list of different lists which need to pad
:param items: require the 'list of tuple' type input(like '[(y, false),...]', y means the item with texts which need to
change order together with the text ,and the false which is in the position of 'require' means )
:param digital: the padding element'type (True means '0', False means '')
:return:
"""
len_list = [len(text) for text in texts]
max_len = max(len_list)
# Get sorted index of len_list.
sorted_index = np.argsort(len_list)[::-1]
trans_texts, seq_lens, trans_items = [], [], None
if items is not None:
trans_items = [[] for _ in range(0, len(items))]
for index in sorted_index:
seq_lens.append(deepcopy(len_list[index]))
trans_texts.append(deepcopy(texts[index]))
if digital:
trans_texts[-1].extend([0] * (max_len - len_list[index]))
else:
trans_texts[-1].extend(['' ] * (max_len - len_list[index]))
# This required specific if padding after sorting.
if items is not None:
for item, (o_item, required) in zip(trans_items, items):
item.append(deepcopy(o_item[index]))
if required:
if digital:
item[-1].extend([0] * (max_len - len_list[index]))
else:
item[-1].extend(['' ] * (max_len - len_list[index]))
if items is not None:
return trans_texts, trans_items, seq_lens
else:
return trans_texts, seq_lens
至此,难搞的部分就完事了,剩余的细节希望大家查看我们的代码。
不可忽视的debug,看看是不是按照预想的跑
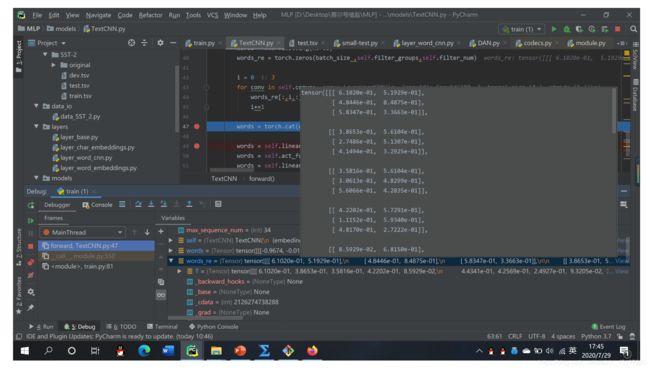
重点检查每一步都数据流的维数和具体内容是不是和预想的一样。如下图所示:(注意是设置断点之后,程序会运行到断断点停止,这时候你可以在下面观察数据是不是按照你所想的一样。检查无误之后你再在下面继续断点,按F9继续程序运行,再下一个断点处停止,继续检查)
评价函数的构建,收尾的最后一步
没有进行评价的模型都是耍流氓。评价模型的函数的所需要有的功能包括查看查准率(准确度)、查全率(召回率),f1 score,f1 macro等等。建议看看这篇文章对于相关测试指标的解释和优缺点分析。
精确率、召回率、F1 值、ROC、AUC 各自的优缺点是什么?
读懂之后创建一个eval类写相关的函数即可
为了实现上述这些指标的检测,配套的,我们要在以后的模型里面不仅仅实现forward,还要实现predict,即返回一个[batch_num,1]的数据代表着每一句话的预测。之后我们用这些预测的数据和真实的数据进行比较,然后得到各个评价指标。
我们代码只实现了一个基础的f1,不过支持随时补充,问题不大:
class sst2F1Eval(object):
@staticmethod
def get_score(predict, label):
TP = 0
FP = 0
FN = 0
for p, l in zip(predict, label):
if p == l and p == '1':
TP += 1
elif p == '1':
FP += 1
elif l == '1':
FN += 1
return 2 * TP / (2*TP + FP + FN)
调参侠的自我修养
调参的话,假设我们不使用相关的自动调参工具而是使用手工尝试。建议大家首先使用论文的最优配置进行尝试,一般结果都会不错,看看到底和人家最后的结果差距有多大,再看看能不能给这个差距一个合理的理由。之后也可以和亲朋好友复现的结果进行对照,判断是否离谱。不断迭代,指导压榨发挥出模型的所有性能。
当然,这一步为了加速,我们一定要白嫖colab的gpu(十倍训练速度差距,十倍网速差距)。而这时候可能会出现很多cuda的bug,大家仔细去了解一下,一般来讲绝大多数错误都是由于数据没有被加载到cuda上,这种情况分为三类:
-
输入数据忘记挂载到cuda上
-
模型忘记挂载到cuda上
-
中间新定义的中间数据没有挂在cuda上
简要来说,请一定注意要把要参与张量运算更新的数据都要挂载到cuda上。
有关colab的白嫖
首先进入google的云端硬盘:
将代码文件夹上传,注意要把预训练模型拿走,colab自带包括bert在内的各种预训练模型。(当然上传也未尝不可,就是慢点)
然后在当前目录下(代码文件夹所在目录),点击新建、更多,创建colab文件
colab类似于jupyter notebook,可以直接执行python代码。在语句最前面加上“!”就可执行linux命令,其余运行等操作和jupyter notebook完全一致。
比如 " !python ‘main.py’ -bs=64 --model==‘MLP’ "
在创建的ipynb文件中,首先要切换到GPU,在修改、笔记本设置里:(一定要搞这个!!!!否则colab没意义!!!!!!)
先执行如下代码,将此页面挂载到云端硬盘上,
期间会弹出两次链接,点击去能够得到验证码,输入即可:
(再次强调,这个两次验证码挺麻烦的,在这一步之前一定要确保已经将设置里面的GPU选中)
——
!apt-get install -y -qq software-properties-common python-software-properties module-init-tools
!add-apt-repository -y ppa:alessandro-strada/ppa 2>&1 > /dev/null
!apt-get update -qq 2>&1 > /dev/null
!apt-get -y install -qq google-drive-ocamlfuse fuse
from google.colab import auth
auth.authenticate_user()
from oauth2client.client import GoogleCredentials
creds = GoogleCredentials.get_application_default()
import getpass
!google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret} < /dev/null 2>&1 | grep URL
vcode = getpass.getpass()
!echo {vcode} | google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret}
——
再执行如下代码,将工作目录切换到:
——
!mkdir -p drive
!google-drive-ocamlfuse drive
import os
import sys
os.chdir(‘drive/此处是你drive下项目文件夹的目录’)
——
接下来安装必要的包、使用!python执行代码即可:
!pip install pytorch_pretrained_bert
!pip install ordered_set
!python ‘main.py’
小结
一般的流程就是:
- 熟悉维数的变化,写模型函数与辅助注释
- 初步实现模型函数的forward(当然大概率有bug)
- 用断点+debugger逐步检查每一步是否按照自己所想
- 如果可以的话说明模型没啥问题,我们把它上传到colab跑初步看看效果
- 先初步和网络上的数据对照一下,看看是不是特别离谱
- 和亲朋好友的结果进行比赛,疯狂调参
结语
在我们的实验中,DAN大概能跑到81.5%的准确度(几乎没调参)。作为一个简单却远远比想象中有效的模型,DAN在如今动不动就上亿的参数中,像一位有实力却淡薄世间的隐士,默默地为nlp初学者们提供做搭建的练习,并给他们留下一份“居然work”的惊喜。