【笔记】Flink 官方教程 Section 1 Try Fink
Section 1. Try Flink
官方链接
1.1 基于 DataStream API 实现欺诈检测
1.1.1 项目搭建
- 找一个目录,在其中执行如下命令
mvn archetype:generate \
-DarchetypeGroupId=org.apache.flink \
-DarchetypeArtifactId=flink-walkthrough-datastream-java \
-DarchetypeVersion=1.11.0 \
-DgroupId=frauddetection \
-DartifactId=frauddetection \
-Dversion=0.1 \
-Dpackage=spendreport \
-DinteractiveMode=false
用 intellij idea 打开创建好的 frauddetection 项目。核心文件是这三个:FraudDetecionJob.java, FraudDetector.java, pom.xml.
- build,然后 run FraudDetectionJob.java,可能会报错
java.lang.NoClassDefFoundError: org/apache/flink/streaming/api/functions/source/SourceFunction. 此时在 pom.xml 中找到两个provided . 再次 build and run,成功执行。
1.1.2 代码分析
FraudDetectionJob 定义了数据流,FraudDetector 定义了业务逻辑;
首先看 FraudDetectionJob 类,它的 main 函数中只有五句代码,我们逐步分析。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Transaction> transactions = env
.addSource(new TransactionSource())
.name("transactions");
DataStream<Alert> alerts = transactions
.keyBy(Transaction::getAccountId)
.process(new FraudDetector())
.name("fraud-detector");
alerts
.addSink(new AlertSink())
.name("send-alerts");
env.execute("Fraud Detection");
- 第一句代码用于创建一个流式执行环境,任务执行环境用于定义任务的属性、创建数据源以及最终启动任务,这在每个 Flink 程序中都是不可缺少的。
- 第二句代码使用示例类创建了数据源,数据源会将数据流不断输送到 Flink 程序中。addSource 返回一个
DataStream, T 由数据源决定,name 函数为其添加一个属性,用于调试方便。 - 第三句代码将数据流进行处理。keyBy 函数将数据流进行分区返回一个
KeyedStream,它是 DataStream 的子类,依次保证并发时同一个区的数据被同一个 task 处理。process 函数对流绑定了一个操作,将会对流上的每一个消息调用定义好的函数(见下文),然后返回处理后的流。最后,添加一个 name 以方便调试。 - 第四句代码为这个数据流指定了一个汇点(sink),这里的 AlertSink 实现了 SinkFunction 接口,它将每一个流上的消息输出到日志中。
- 第五局代码为传递了一个任务名,然后开始执行搭建好的任务。
FraudDetector 类实现了 KeyedProcessFunction
public class FraudDetector extends KeyedProcessFunction<Long, Transaction, Alert> {
private static final long serialVersionUID = 1L;
private static final double SMALL_AMOUNT = 1.00;
private static final double LARGE_AMOUNT = 500.00;
private static final long ONE_MINUTE = 60 * 1000;
@Override
public void processElement(
Transaction transaction,
Context context,
Collector<Alert> collector) throws Exception {
Alert alert = new Alert();
alert.setId(transaction.getAccountId());
collector.collect(alert);
}
}
内部需要实现 processElement(I value, Context ctx, Collector 方法,对于一个输入消息,构造所需的输出消息并将其放到 Collector 中。
这个方法将会在每个输入事件上调用一次。
1.1.3 状态
题目要求:当同一个账户在一次小额交易(小于 SMALL_AMOUNT)后面紧跟着一次大额交易(大于 LARGE_AMOUNT)时,输出一个报警信息。
为此,我们需要为每一个账户添加一个状态变量:上一次交易是否是小额交易。
Flink 提供了一套支持容错状态的原语,像普通成员变量一样易于使用。最基础的状态类型是 ValueState,它可用于分区后(keyed)的上下文中,每个 key 对应一个变量。
定义与注册如下所示,注册函数只需要写在 Process 类中即可,不需要显式调用。
private transient ValueState<Boolean> flagState;
@Override
public void open(Configuration parameters) {
ValueStateDescriptor<Boolean> flagDescriptor = new ValueStateDescriptor<>(
"flag",
Types.BOOLEAN);
flagState = getRuntimeContext().getState(flagDescriptor);
}
ValueState 有三个用户接口方法:
- update 用于更新(修改)状态
- value 用于获取状态
- clear 用于清空状态(设置为 null)
完整的 FraudDetection 代码如下,注意使用了 true 状态和 null 状态,没有使用 false 状态。
public class FraudDetector extends KeyedProcessFunction<Long, Transaction, Alert> {
private static final long serialVersionUID = 1L;
private static final double SMALL_AMOUNT = 1.00;
private static final double LARGE_AMOUNT = 500.00;
private static final long ONE_MINUTE = 60 * 1000;
private transient ValueState<Boolean> flagState;
@Override
public void open(Configuration parameters) {
ValueStateDescriptor<Boolean> flagDescriptor = new ValueStateDescriptor<>(
"flag",
Types.BOOLEAN);
flagState = getRuntimeContext().getState(flagDescriptor);
}
@Override
public void processElement(
Transaction transaction,
Context context,
Collector<Alert> collector) throws Exception {
if(flagState.value()!=null) {
if(transaction.getAmount() > LARGE_AMOUNT) {
Alert alert = new Alert();
alert.setId(transaction.getAccountId());
collector.collect(alert);
}
flagState.clear();
}
if(transaction.getAmount() < SMALL_AMOUNT) {
flagState.update(true);
}
}
}
1.1.4 定时状态
题目要求:如果小额交易一分钟之内发生大额交易,就产生警告。
为了学习计时器,我们使用一个定时器变量来做这件事:
- 当标记设置为 true 时,设置一个一分钟后触发的定时器。
- 当定时器触发时,重置标记状态。
- 当标记状态重置时,删除定时器。
首先注册一个额外的状态变量 timerState,表示定时器的触发时间。
private transient ValueState<Boolean> flagState;
private transient ValueState<Long> timerState;
@Override
public void open(Configuration parameters) {
ValueStateDescriptor<Boolean> flagDescriptor = new ValueStateDescriptor<>(
"flag",
Types.BOOLEAN);
flagState = getRuntimeContext().getState(flagDescriptor);
ValueStateDescriptor<Long> timerDescriptor = new ValueStateDescriptor<>(
"timer-state",
Types.LONG);
timerState = getRuntimeContext().getState(timerDescriptor);
}
更改处理逻辑:当金额很小时设置 flag,设置 timer,添加定时器。
if (transaction.getAmount() < SMALL_AMOUNT) {
flagState.update(true);
long timer = context.timerService().currentProcessingTime() + ONE_MINUTE;
context.timerService().registerProcessingTimeTimer(timer);
timerState.update(timer);
}
当定时器触发时,会调用 onTimer 方法,我们可以重写这个方法。
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<Alert> out) {
// remove flag after 1 minute
timerState.clear();
flagState.clear();
}
如果需要取消定时器,需要:
- 删除已经注册的定时器
- 清除两个状态变量 flag 与 timer
汇总后的代码
package spendreport;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.util.Collector;
import org.apache.flink.walkthrough.common.entity.Alert;
import org.apache.flink.walkthrough.common.entity.Transaction;
/**
* Skeleton code for implementing a fraud detector.
*/
public class FraudDetector extends KeyedProcessFunction<Long, Transaction, Alert> {
private static final long serialVersionUID = 1L;
private static final double SMALL_AMOUNT = 1.00;
private static final double LARGE_AMOUNT = 500.00;
private static final long ONE_MINUTE = 60 * 1000;
private transient ValueState<Boolean> flagState;
private transient ValueState<Long> timerState; // 定时器触发时间
@Override
public void open(Configuration parameters) {
ValueStateDescriptor<Boolean> flagDescriptor = new ValueStateDescriptor<>(
"flag",
Types.BOOLEAN);
flagState = getRuntimeContext().getState(flagDescriptor);
ValueStateDescriptor<Long> timerDescriptor = new ValueStateDescriptor<>(
"timerTime",
Types.LONG);
timerState = getRuntimeContext().getState(timerDescriptor);
}
@Override
public void processElement(
Transaction transaction,
Context context,
Collector<Alert> collector) throws Exception {
if(flagState.value()!=null) {
if(transaction.getAmount() > LARGE_AMOUNT) {
Alert alert = new Alert();
alert.setId(transaction.getAccountId());
collector.collect(alert);
}
cleanUp(context);
}
if(transaction.getAmount() < SMALL_AMOUNT) {
flagState.update(true);
long afterAMinute = context.timerService().currentProcessingTime() + ONE_MINUTE;
timerState.update(afterAMinute);
context.timerService().registerProcessingTimeTimer(afterAMinute);
}
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<Alert> out) {
timerState.clear();
flagState.clear();
}
private void cleanUp(Context ctx) throws Exception {
Long timer = timerState.value();
ctx.timerService().deleteProcessingTimeTimer(timer);
timerState.clear();
flagState.clear();
}
}
1.2 基于 Table API 实现实时报表
Apache flik 提供了一个 Table API,作为一个统一的关系 API,用于批处理和流处理,也就是说,查询在无界的实时流或有界的批处理数据集上以相同的语义执行,并产生相同的结果。Flik 中的 Table API 通常用于简化数据分析、数据流水线和 ETL 应用程序的定义。
1.2.1 搭建
- git clone https://github.com/apache/flink-playgrounds.git
- 用 IDEA 打开 flink-playgrounds 下的 table-walkthrough 项目,导航到 SpendReport.java.
- 注释掉 pom.xml 里面所有的
test provided - 构建并运行项目,结果应当是这个报错,因为还需要添加代码。

1.2.2 代码分析
EnvironmentSettings settings = EnvironmentSettings.newInstance().build();
TableEnvironment tEnv = TableEnvironment.create(settings);
tEnv.executeSql("CREATE TABLE transactions (\n" +
" account_id BIGINT,\n" +
" amount BIGINT,\n" +
" transaction_time TIMESTAMP(3),\n" +
" WATERMARK FOR transaction_time AS transaction_time - INTERVAL '5' SECOND\n" +
") WITH (\n" +
" 'connector' = 'kafka',\n" +
" 'topic' = 'transactions',\n" +
" 'properties.bootstrap.servers' = 'kafka:9092',\n" +
" 'format' = 'csv'\n" +
")");
tEnv.executeSql("CREATE TABLE spend_report (\n" +
" account_id BIGINT,\n" +
" log_ts TIMESTAMP(3),\n" +
" amount BIGINT\n," +
" PRIMARY KEY (account_id, log_ts) NOT ENFORCED" +
") WITH (\n" +
" 'connector' = 'jdbc',\n" +
" 'url' = 'jdbc:mysql://mysql:3306/sql-demo',\n" +
" 'table-name' = 'spend_report',\n" +
" 'driver' = 'com.mysql.jdbc.Driver',\n" +
" 'username' = 'sql-demo',\n" +
" 'password' = 'demo-sql'\n" +
")");
Table transactions = tEnv.from("transactions");
report(transactions).executeInsert("spend_report");
- 前两行设置了表环境,这个项目中创建了一个使用流运行时的标准表环境。
- 接下来两句是两个表注册语句:第一条语句在环境中注册了一个表 transactions,来源是 kafaka 中的 transactions,是一个以 csv 格式存储的 topic。第二条语句注册了一个表 spend_report,底层存储对应于 mysql 中的一张表。
- 最后两句构建了应用程序,从 transactions 中读取输入表以读取其行,使用 executeInsert 将结果写入输出表。 report 函数是尚未实现的业务逻辑。
1.2.3 测试
项目中包含了一个测试类 SpendReportTest,它用批处理模式创建表环境。因为 flink 的流批非常牛批,具有一致语义,所以可以很方便地以批处理形式开发和测试程序,然后部署为流式应用程序。
EnvironmentSettings settings = EnvironmentSettings.newInstance().inBatchMode().build();
TableEnvironment tEnv = TableEnvironment.create(settings);
1.2.4 业务逻辑
要求:实现 report 函数,显示一天中每个小时每个账户的总支出。
就和写 sql 一样。。实际上就是写 sql。
public static Table report(Table transactions) {
return transactions.select(
$("account_id"),
$("transaction_time").floor(TimeIntervalUnit.HOUR).as("log_ts"),
$("amount")
).groupBy(
$("account_id"),
$("log_ts")
).select(
$("account_id"),
$("log_ts"),
$("amount").sum().as("amount")
);
}
执行一次测试,发现可以通过。
为了学习自定义函数,我们自己定义一个 floor 函数。
import java.time.LocalDateTime;
import java.time.temporal.ChronoUnit;
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.functions.ScalarFunction;
public class MyFloor extends ScalarFunction {
public @DataTypeHint("TIMESTAMP(3)") LocalDateTime eval(
@DataTypeHint("TIMESTAMP(3)") LocalDateTime timestamp
) {
return timestamp.truncatedTo(ChronoUnit.HOURS);
}
}
然后把 floor 换成 call 形式调用的 MyFloor.
public static Table report(Table transactions) {
return transactions.select(
$("account_id"),
call(MyFloor.class, $("transaction_time")).as("log_ts"),
$("amount")
).groupBy(
$("account_id"),
$("log_ts")
).select(
$("account_id"),
$("log_ts"),
$("amount").sum().as("amount")
);
}
再测试一次,又成功了!
1.2.5 加窗
加窗是指基于时间将数据进行分组,这是数据处理的典型操作,尤其是在处理无限流的时候。Flink 提供了灵活的窗口语义,最基本的窗口类型是滚筒窗(Tumble Window),它具有固定的窗口大小并且窗口之间不重叠。
窗口函数具有 intrinsics 的属性,即可以在运行时被额外优化。下面就用滚筒窗来实现一下 report 吧!
public static Table report(Table rows) {
return rows.window(
Tumble.over(lit(1).hour()).on($("transaction_time")).as("log_ts")
).groupBy(
$("account_id"),
$("log_ts")
).select(
$("account_id"),
$("log_ts").start().as("log_ts"),
$("amount").sum().as("amount")
);
}
注意加窗后如果要换回原来的数据格式,需要用 start().
1.2.6 在 docker 中尝试
进入 flink-playgrounds/table-walkthrough 目录下,执行:
docker-compose build
docker-compose up -d
然后就可以在 flink 界面(8082) 查看正在运行的任务。
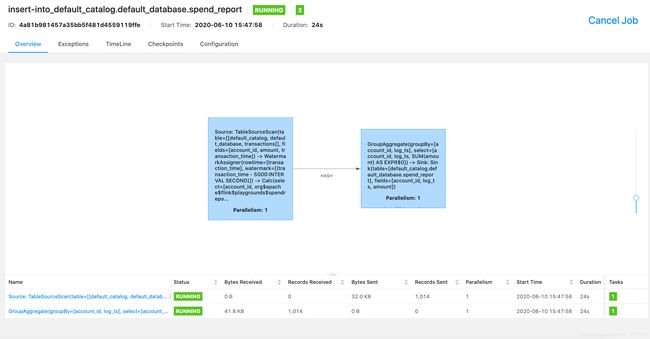
还可以去 Grafana(3000) 查看可视化结果。
注意:调了我三个小时的bug!在执行上面的语句之前,请将 pom.xml 改回最初的状态!!!!!!!!!!!!!
学到了,调试和教程不一样的 bug 时:
- 学会看日志,找到第一行错误在哪
- 想想自己对项目改动了什么,改回去试试
- 设置一个阈值,比如30分钟,到时间还调不出来直接不调了,重装或者换个环境。