大数据全家桶安装及启动JDK,mysql,canal,Zookeeper,Hadoop,Hive,Hbase,Datax,kylin,kafka,spark,flink,redis,zeppelin等
准备虚拟机
- 用户名:root
- 密码:123456
- IP: 192.168.100.100
- 主机名: node01
修改虚拟机IP地址:
vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
HWADDR=00:0C:29:61:02:EC
TYPE=Ethernet
UUID=78ce60bd-12ff-4f76-9783-c1ddba997090
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.100.100
GATEWAY=192.168.100.2
NETMASK=255.255.255.0
DNS1=8.8.8.8修改主机名(重启后永久生效)
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=node01设置ip和域名映射
vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.100.100 node01 node01.hadoop.com关闭防火墙
service iptables stop #关闭防火墙
chkconfig iptables off #禁止开机启动关闭selinux
vi /etc/selinux/config
SELINUX=disabled
免密码登录
ssh-keygen -t rsa
ssh-copy-id node01
时钟同步
## 安装
yum install -y ntp
## 启动定时任务
crontab -e
## 随后在输入界面键入
*/1 * * * * /usr/sbin/ntpdate ntp4.aliyun.com;rz安装
yum -y install lrzsz
nc安装
yum install -y nc
测试nck
nc -lk 9999
文件夹规划
mkdir -p /export/servers # 安装目录
mkdir -p /export/softwares # 软件包存放目录
mkdir -p /export/scripts # 启动脚本目录 安装JDK
查看自带的openjdk
rpm -qa | grep java
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cDIEi4CS-1589797262624)(assets/1569122548836.png)]
卸载
rpm -e java-1.6.0-openjdk-1.6.0.41-1.13.13.1.el6_8.x86_64 tzdata-java-2016j-1.el6.noarch java-1.7.0-openjdk-1.7.0.131-2.6.9.0.el6_8.x86_64 --nodeps
上传并解压
rz上传jdk-8u141-linux-x64.tar.gz到softwares目录中
tar -zxvf jdk-8u141-linux-x64.tar.gz -C ../servers/
配置环境变量
vim /etc/profile
export JAVA_HOME=/export/servers/jdk1.8.0_141
export PATH=:$JAVA_HOME/bin:$PATH
重新加载环境变量
source /etc/profile
此时, java和javac命令都可以使用了
MySql安装
安装步骤
-
上传tar包
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-riOtIl7f-1589797262627)(assets/1558497513983.png)]
-
解压
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BOF2gLYo-1589797262630)(assets/1558497763834.png)]
-
卸载历史MySql
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0uMvonKt-1589797262631)(assets/1558497974334.png)]
# 搜索mysql相关依赖 rpm -qa | grep mysql # 卸载查询到的所有依赖 rpm -e --nodeps mysql-libs-5.1.73-8.el6_8.x86_64 -
顺序安装
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BtftJAj8-1589797262634)(assets/1558498345558.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Cho0S9fV-1589797262636)(assets/1558498497274.png)]
# 查询mysql所有的安装包 cd /export/softwares/mysql-5.7 ll # 依次安装下列依赖 rpm -ih mysql-community-common-5.7.26-1.el6.x86_64.rpm rpm -ih mysql-community-libs-5.7.26-1.el6.x86_64.rpm rpm -ih mysql-community-client-5.7.26-1.el6.x86_64.rpm rpm -ih mysql-community-server-5.7.26-1.el6.x86_64.rpm rpm -ih mysql-community-devel-5.7.26-1.el6.x86_64.rpm # 供后续superset使用 -
初始化
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0O2WgQS5-1589797262639)(assets/1558498601105.png)]
# 启动Mysql服务 service mysqld start -
查询初始密码
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BlYs8CM0-1589797262640)(assets/1558498659003.png)]
grep 'temporary password' /var/log/mysqld.log -
登录MySql系统, 修改密码
# 登录系统
mysql -uroot -paVGidM5/.RtN
# 修改密码,密码默认是8位,并且包含大小写字母+特殊字符+数字
ALTER USER 'root'@'localhost' IDENTIFIED BY 'MySql5.7';[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aWG0HRID-1589797262642)(assets/1558500805405.png)]
查看密码规则:
SHOW VARIABLES LIKE 'validate_password%';
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SktOBdMf-1589797262644)(assets/1558500941206.png)]
关于 mysql 密码策略相关参数:
- validate_password_length 固定密码的总长度;
- validate_password_dictionary_file 指定密码验证的文件路径;
- validate_password_mixed_case_count 整个密码中至少要包含大/小写字母的总个数
- validate_password_number_count 整个密码中至少要包含阿拉伯数字的个数;
- validate_password_policy 指定密码的强度验证等级,默认为 MEDIUM;
关于 validate_password_policy 的取值:
- 0/LOW:只验证长度;
- 1/MEDIUM:验证长度、数字、大小写、特殊字符;
- 2/STRONG:验证长度、数字、大小写、特殊字符、字典文件;
- validate_password_special_char_count 整个密码中至少要包含特殊字符的个数;
**修改密码规则【选做】:**
set global validate_password_policy=LOW;
set global validate_password_length=6;
ALTER USER 'root'@'localhost' IDENTIFIED BY '123456';
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-n4UmmsUj-1589797262647)(assets/1558501305997.png)]
-
设置远程登录
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gtPy0KRl-1589797262648)(assets/1558501680556.png)]
# 赋予root用户远程登录的权限 GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION; # 刷新权限 flush privileges; -
测试远程登录
使用SqlYog测试是否可以远程连接到node01的mysql
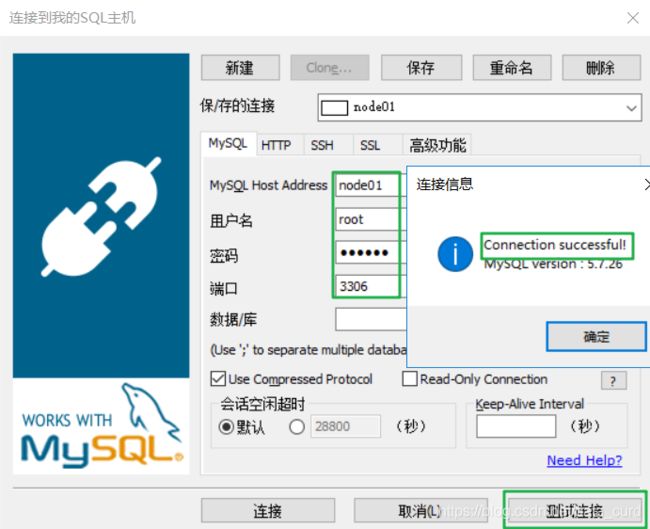
-
配置MySql开机自启
chkconfig mysqld on
MySql开启binlog
-
使用vi打开
/etc/my.cnf -
添加以下配置
[mysqld] log-bin=/var/lib/mysql/mysql-bin binlog-format=ROW server_id=1注释说明
# 配置binlog日志的存放路径为/var/lib/mysql目录,文件以mysql-bin开头
log-bin=/var/lib/mysql/mysql-bin# 配置mysql中每一行记录的变化都会详细记录下来
binlog-format=ROW# 配置当前机器器的服务ID(如果是mysql集群,不能重复)
server_id=1 -
重启mysql
service mysqld restart -
mysql -u root -p登录到mysql,执行以下命令show variables like '%log_bin%'; -
mysql输出以下内容,表示binlog已经成功开启
+---------------------------------+--------------------------------+ | Variable_name | Value | +---------------------------------+--------------------------------+ | log_bin | ON | | log_bin_basename | /var/lib/mysql/mysql-bin | | log_bin_index | /var/lib/mysql/mysql-bin.index | | log_bin_trust_function_creators | OFF | | log_bin_use_v1_row_events | OFF | | sql_log_bin | ON | +---------------------------------+--------------------------------+ 6 rows in set (0.00 sec) -
进入到
/var/lib/mysql可以查看到mysql-bin.000001文件已经生成
Canal安装
-
上传
canal.deployer-1.0.24.tar.gz到/export/softwares目录 -
在
/export/servers下创建canal目录,一会直接将canal的文件解压到这个目录中cd /export/servers mkdir canal -
解压canal到
/export/servers目录cd /export/softwares tar -xvzf canal.deployer-1.0.24.tar.gz -C ../servers/canal -
修改
canal/conf/example目录中的instance.properties文件## mysql serverId canal.instance.mysql.slaveId = 1234 # position info canal.instance.master.address = node01:3306 canal.instance.dbUsername = root canal.instance.dbPassword = 123456- canal.instance.mysql.slaveId这个ID不能与之前配置的
service_id重复 - canal.instance.master.address配置为mysql安装的机器名和端口号
- canal.instance.mysql.slaveId这个ID不能与之前配置的
-
执行/export/servers/canal/bin目录中的
startup.sh启动canalcd /export/servers/canal/bin ./startup.sh -
控制台如果输出如下,表示canal已经启动成功
cd to /export/servers/canal/bin for workaround relative path LOG CONFIGURATION : /export/servers/canal/bin/../conf/logback.xml canal conf : /export/servers/canal/bin/../conf/canal.properties CLASSPATH :/export/servers/canal/bin/../conf:/export/servers/canal/bin/../lib/zookeeper- ... cd to /export/servers/canal/bin for continue注意:
Canal的远程连接端口号默认为
11111,当然如果需要,可以在canal.properties文件中修改
重置Canal和MySql的binlog位置
重置mysql的binlog
- 进入mysql,
mysql -uroot -p123456- reset master;
- show master status;
删除zookeeper中的数据
- rmr /otter/canal
删除
Zookeeper的安装
上传压缩包并解压
zookeeper-3.4.9.tar.gz
tar -zxvf zookeeper-3.4.9.tar.gz -C ../servers/
配置zookeeper
cd /export/servers/zookeeper-3.4.9/conf/
cp zoo_sample.cfg zoo.cfg
mkdir -p /export/servers/zookeeper-3.4.9/zkdatas/
vim zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/export/servers/zookeeper-3.4.9/zkdatas
# the port at which the clients will connect
clientPort=2181
# 保留多少个快照
autopurge.snapRetainCount=3
# 日志多少小时清理一次
autopurge.purgeInterval=1
# 集群中服务器地址
server.1=node01:2888:3888创建myid
echo 1 > /export/servers/zookeeper-3.4.9/zkdatas/myid
启动
# 后台启动
/export/servers/zookeeper-3.4.9/bin/zkServer.sh start
# 前台启动
/export/servers/zookeeper-3.4.9/bin/zkServer.sh start-foreground
# 查看启动状态
/export/servers/zookeeper-3.4.9/bin/zkServer.sh statusjps查看
可以观察到下列进程
QuorumPeerMain
配置环境变量
vi /etc/profile
export ZK_HOME=/export/servers/zookeeper-3.4.9
export PATH=:$ZK_HOME/bin:$PATH
重新加载环境变量source /etc/profile
安装Hadoop
集群规划
| 服务器IP | 192.168.174.100 |
|---|---|
| 主机名 | node01 |
| NameNode | 是 |
| SecondaryNameNode | 是 |
| dataNode | 是 |
| ResourceManager | 是 |
| NodeManager | 是 |
上传apache hadoop包并解压
cd /export/softwares
tar -zxvf hadoop-2.7.5.tar.gz -C ../servers/
修改core-site.xml
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://node01:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-2.7.5/hadoopDatas/tempDatas</value>
</property>
<!-- 缓冲区大小,实际工作中根据服务器性能动态调整 -->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!-- 开启hdfs的垃圾桶机制,删除掉的数据可以从垃圾桶中回收,单位分钟 -->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
</configuration>修改hdfs-site.xml
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>node01:50090value>
property>
<property>
<name>dfs.namenode.http-addressname>
<value>node01:50070value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas,file:///export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas2value>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas,file:///export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas2value>
property>
<property>
<name>dfs.namenode.edits.dirname>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/nn/editsvalue>
property>
<property>
<name>dfs.namenode.checkpoint.dirname>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/snn/namevalue>
property>
<property>
<name>dfs.namenode.checkpoint.edits.dirname>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/dfs/snn/editsvalue>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.permissionsname>
<value>falsevalue>
property>
<property>
<name>dfs.blocksizename>
<value>134217728value>
property>
configuration>修改hadoop-env.sh
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim hadoop-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_141
修改yarn-site.xml
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim yarn-site.xml
yarn.resourcemanager.hostname
node01
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
yarn.nodemanager.resource.memory-mb
20480
yarn.scheduler.minimum-allocation-mb
2048
yarn.nodemanager.vmem-pmem-ratio
2.1
修改mapred-env.sh
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim mapred-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_141
修改slaves
cd /export/servers/hadoop-2.7.5/etc/hadoop
vim slaves
node01
准备文件夹
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/tempDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/namenodeDatas2
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/datanodeDatas2
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/nn/edits
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/snn/name
mkdir -p /export/servers/hadoop-2.7.5/hadoopDatas/dfs/snn/edits
配置hadoop的环境变量
vim /etc/profile
export HADOOP_HOME=/export/servers/hadoop-2.7.5
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
source /etc/profile
启动
首次启动 HDFS 时,必须对其进行格式化操作。 本质上是一些清理和
准备工作,因为此时的 HDFS 在物理上还是不存在的。
hdfs namenode -format或者 hadoop namenode –format
cd /export/servers/hadoop-2.7.5/
bin/hdfs namenode -format
sbin/start-dfs.sh
sbin/start-yarn.sh
sbin/mr-jobhistory-daemon.sh start historyserver
JPS查看
DataNode
NameNode
SecondaryNameNode
JobHistoryServer
ResourceManager
NodeManager
Web界面
http://node01:50070/explorer.html#/ 查看hdfs
http://node01:8088/cluster 查看yarn集群
http://node01:19888/jobhistory 查看历史完成的任务
Hive 的安装
http://archive.apache.org/dist/hive/hive-2.1.1/apache-hive-2.1.1-bin.tar.gz
上传并解压安装包
cd /export/softwares/
tar -zxvf apache-hive-2.1.1-bin.tar.gz -C ../servers/
修改hive-env.sh
cd /export/servers/apache-hive-2.1.1-bin/conf
cp hive-env.sh.template hive-env.sh
HADOOP_HOME=/export/servers/hadoop-2.7.5
export HIVE_CONF_DIR=/export/servers/apache-hive-2.1.1-bin/conf
修改hive-site.xml
cd /export/servers/apache-hive-2.1.1-bin/conf
vim hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>123456value>
property>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://node01:3306/hive?createDatabaseIfNotExist=true&useSSL=falsevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
property>
<property>
<name>hive.metastore.schema.verificationname>
<value>falsevalue>
property>
<property>
<name>datanucleus.schema.autoCreateAllname>
<value>truevalue>
property>
<property>
<name>hive.server2.thrift.bind.hostname>
<value>node01value>
property>
<property>
<name>hive.metastore.urisname>
<value>thrift://hadoop003:9083value>
property>
configuration>上传mysql-connector-java-5.1.38.jar
上传mysql驱动包到 /export/servers/apache-hive-2.1.1-bin/lib
修改环境变量
vim /etc/profile
export HIVE_HOME=/export/servers/apache-hive-2.1.1-bin
export PATH=:$HIVE_HOME/bin:$PATH
修改hadoop的hdfs-site.xml文件
dfs.webhdfs.enabled
true
修改hadoop的core-site.xml文件
hadoop.proxyuser.root.hosts
*
hadoop.proxyuser.root.groups
*
重启Hadoop集群
stop-dfs.sh
stop-yarn.sh
start-dfs.sh
start-yarn.sh初始化元数据
schematool -dbType mysql -initSchema
启动hiveserver2服务
cd /export/servers/apache-hive-2.1.1-bin
nohup bin/hive --service hiveserver2 > /dev/null 2>&1 &
nohup bin/hive --service metastore > /dev/null 2>&1 &使用beeline连接hiveserver2
beeline
beeline> !connect jdbc:hive2://node01:10000Hive使用本地模式
set hive.exec.mode.local.auto=true;
HBase的安装
上传解压安装包
hbase-1.1.1-bin.tar.gz
tar -zxvf hbase-1.1.1-bin.tar.gz -C ../servers/
修改hbase-env.sh
export JAVA_HOME=/export/servers/jdk1.8.0_141/
export HBASE_MANAGES_ZK=false
修改hbase-site.xml
<configuration>
<property>
<name>hbase.rootdirname>
<value>hdfs://node01:8020/hbasevalue>
property>
<property>
<name>hbase.cluster.distributedname>
<value>truevalue>
property>
<property>
<name>hbase.master.portname>
<value>16000value>
property>
<property>
<name>hbase.zookeeper.quorumname>
<value>node01value>
property>
<property>
<name>hbase.zookeeper.property.dataDirname>
<value>/export/servers/zookeeper-3.4.9/zkdatasvalue>
property>
configuration>修改regionservers
vim regionservers
node01
配置软连接
ln -s /export/servers/hadoop-2.7.5/etc/hadoop/core-site.xml /export/servers/hbase-1.1.1/conf/core-site.xml
ln -s /export/servers/hadoop-2.7.5/etc/hadoop/hdfs-site.xml /export/servers/hbase-1.1.1/conf/hdfs-site.xml
修改环境变量
vim /etc/profile
export HBASE_HOME=/export/servers/hbase-1.1.1
export PATH=:$HBASE_HOME/bin:$PATH
启动
cd /export/servers/hbase-1.1.1
bin/start-hbase.sh
jps
HMaster
HRegionServer
WEB界面
http://node01:16010/master-status Master
http://node01:16030/rs-status RegionServer
DataX安装
前置条件
- JDK(1.8以及1.8以上,推荐1.8)
- Python(推荐 Python 2.6.X)
- 使用
python -V命令,查看python版本 - 使用 quit() 退出
- 使用
安装步骤
-
上传安装包
datax.tar.gz -
解压
tar -zxvf datax.tar.gz -C /export/servers/ -
自检脚本
进入bin目录,开始自检: python datax.py ../job/job.json
安装kylin
简介
Kylin 是一个 Hadoop 生态圈下的 MOLAP 系统,是 ebay 大数据部门从2014 年开始研发的支持 TB 到 PB 级别数据量的分布式 Olap 分析引擎。其特点包括:
- 可扩展的超快的 OLAP 引擎
- 提供 ANSI-SQL 接口
- 交互式查询能力
- MOLAP Cube 的概念
- 与 BI 工具可无缝整合
依赖环境
Kylin 依赖于 Hadoop、Hive、Zookeeper 和 Hbase
| 软件 | 版本 |
|---|---|
| Apache hbase-1.1.1-bin.tar.gz | 1.1.1 |
| apache-kylin-2.6.3-bin-hbase1x.tar.gz | 2.6.3 |
- kylin-2.6.3-bin-hbase1x所依赖的hbase为1.1.1版本
- 要求hbase的hbase.zookeeper.quorum值必须只能是host1,host2,…。不允许出现host:2181,…
安装步骤
- 上传解压
apache-kylin-2.6.3-bin-hbase1x.tar.gz
tar -zxf /export/softwares/apache-kylin-2.6.3-bin-hbase1x.tar.gz -C /export/servers/
- 增加kylin依赖组件的配置
cd /export/servers/apache-kylin-2.6.3-bin-hbase1x/conf
ln -s $HADOOP_HOME/etc/hadoop/hdfs-site.xml hdfs-site.xml
ln -s $HADOOP_HOME/etc/hadoop/core-site.xml core-site.xml
ln -s $HBASE_HOME/conf/hbase-site.xml hbase-site.xml
ln -s $HIVE_HOME/conf/hive-site.xml hive-site.xml
ln -s $SPARK_HOME/conf/spark-defaults.conf spark-defaults.conf- 配置kylin.sh
cd /export/servers/apache-kylin-2.6.3-bin-hbase1x/bin
vim kylin.shkylin.sh文件添加如下内容:
export HADOOP_HOME=/export/servers/hadoop-2.6.0-cdh5.14.0
export HIVE_HOME=/export/servers/hive-1.1.0-cdh5.14.0
export HBASE_HOME=/export/servers/hbase-1.1.1
export SPARK_HOME=/export/servers/spark-2.2.0-bin-hadoop2.6配置kylin.properties
修改 资料\Kylin\kylin_配置文件\kylin.properties 中HDFS的路径,然后上传到 Linux的 Kylin/conf文件夹中
修改yarn-site.xml
<configuration>
<property>
<name>mapreduce.reduce.java.optsname>
<value>-Xms2000m -Xmx4600mvalue>
property>
<property>
<name>mapreduce.map.memory.mbname>
<value>5120value>
property>
<property>
<name>mapreduce.reduce.input.buffer.percentname>
<value>0.5value>
property>
<property>
<name>mapreduce.reduce.memory.mbname>
<value>2048value>
property>
<property>
<name>mapred.tasktracker.reduce.tasks.maximumname>
<value>2value>
property>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>node01:10020value>
property>
<property>
<name>yarn.app.mapreduce.am.staging-dirname>
<value>/export/servers/hadoop-2.7.5/hadoopDatas/tempDatas/mapred/stagingvalue>
property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dirname>
<value>${yarn.app.mapreduce.am.staging-dir}/history/done_intermediatevalue>
property>
<property>
<name>mapreduce.jobhistory.done-dirname>
<value>${yarn.app.mapreduce.am.staging-dir}/history/donevalue>
property>
configuration>- WEB UI
`http://node01:7070/kylin`
用户名: ADMIN
密码: KYLIN Kafka安装
-
上传解压
kafka_2.11-0.11.0.2.tgz -
修改
config/server.properties# 指定broker的唯一编号 broker.id=0 # 开启物理删除topic delete.topic.enable=true -
启动程序
# 启动Kafka cd /export/servers/kafka_2.11-0.11.0.2;nohup bin/kafka-server-start.sh config/server.properties > /dev/null 2>&1 &
相关指令
cd /export/servers/kafka_2.11-0.11.0.2
创建topic
bin/kafka-topics.sh --create --zookeeper node01:2181 --partitions 1 --replication-factor 1 --topic 主题名称
创建topic为test的producer
bin/kafka-console-producer.sh --broker-list node01:9092 --topic test
创建topic为test的consumer
bin/kafka-console-consumer.sh --bootstrap-server node01:9092 --from-beginning --topic test
cd /export/servers/kafka_2.11-0.11.0.2 bin/kafka-console-consumer.sh --bootstrap-server node01:9092 --topic itcast_order
Spark安装
spark-2.2.0-bin-hadoop2.7.tgz
tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz -C …/servers/
cd …/servers/spark-2.2.0-bin-hadoop2.7/conf
cp spark-env.sh.template spark-env.sh
Flink安装
- 上传压缩包
- 解压
cd /export/softwares
tar -zxvf flink-1.7.2-bin-hadoop27-scala_2.11.tgz -C /export/servers/- 启动
cd /export/servers/flink-1.7.2/
./bin/start-cluster.sh
-
访问web界面
http://node01:8081/
Redis安装
- 获取redis资源
wget http://download.redis.io/releases/redis-4.0.8.tar.gz- 解压
tar xzvf redis-4.0.8.tar.gz- 提前安装gcc(可选)
yum install gcc- 安装
cd redis-4.0.8
make MALLOC=libc
cd src
make install PREFIX=/usr/local/redis- 移动配置文件到安装目录下
cd ../
mkdir /usr/local/redis/etc
mv redis.conf /usr/local/redis/etc- 配置redis为后台启动
vi /usr/local/redis/etc/redis.conf
1、将**daemonize no** 改成daemonize yes
2、将bind 127.0.0.1改成 bind node01- 将redis加入到开机启动
vi /etc/rc.local
//在里面添加内容:
/usr/local/redis/bin/redis-server /usr/local/redis/etc/redis.conf (意思就是开机调用这段开启redis的命令)- 开启redis
/usr/local/redis/bin/redis-server /usr/local/redis/etc/redis.conf - 停止redis
pkill redis
-
客户端测试连通性
[root@node01 bin]# /usr/local/redis/bin/redis-cli -h node01 node01:6379> ping PONG -
卸载redis
rm -rf /usr/local/redis //删除安装目录
rm -rf /usr/bin/redis-* //删除所有redis相关命令脚本
rm -rf /root/download/redis-4.0.4 //删除redis解压文件夹Zeppelin安装
- 上传
zeppelin-0.8.0-bin-all.tgz - 解压
tar -zxvf zeppelin-0.8.0-bin-all.tgz -C /export/servers/
- 启动Zeppelin
cd /export/servers/zeppelin-0.8.0-bin-all/
# 启动
bin/zeppelin-daemon.sh start
# 停止
bin/zeppelin-daemon.sh stop- 访问WEB-UI
http://node01:8080/#/
Druid-Imply安装
-
下载安装包(也可以手动上传压缩包)
cd /export/softwares/ wget https://static.imply.io/release/imply-3.0.4.tar.gz -
解压imply-3.0.4
tar -xvzf imply-3.0.4.tar.gz -C ../servers cd ../servers/imply-3.0.4 -
mysql中创建imply相关的数据库
CREATE DATABASE `druid` DEFAULT CHARACTER SET utf8;
CREATE DATABASE `pivot` DEFAULT CHARACTER SET utf8;注意事项
- MySQL版本必须使用5.5及以上版本(Druid和Pivot使用utf8字符集)
-
修改并上传配置文件
-
将 imply 安装目录的 conf-quickstart目录重命名为 conf-quickstart.bak
mv conf-quickstart conf-quickstart.bak -
上传
imply配置文件\conf-quickstart.zip到 imply-3.0.4 安装目录 -
解压缩
unzip conf-quickstart.zip -
修改 conf/druid/_common/common.runtime.properties 文件
# 修改zookeeper的配置 druid.zk.service.host=node01:2181 # 修改MySQL的配置 druid.metadata.storage.type=mysql druid.metadata.storage.connector.connectURI=jdbc:mysql://node01:3306/druid druid.metadata.storage.connector.user=root druid.metadata.storage.connector.password=123456 -
修改 conf/pivot/config.yaml 配置文件
stateStore: type: mysql location: mysql connection: 'mysql://root:123456@node01:3306/pivot'
-
-
配置环境变量
# 编辑环境变量 vi /etc/profile # DRUID export DRUID_HOME=/export/servers/imply-3.0.4 # 重新加载环境变量 source /etc/profile -
修改启动脚本
由于本文搭建的是
单机Imply, 无法启动多次supervise, 需要修改下启动脚本
vi /export/servers/imply-3.0.4/conf/supervise/quickstart.conf
:verify bin/verify-java
# 屏蔽掉端口检测 不然会提示zookeeper端口占用
# :verify bin/verify-default-ports
:verify bin/verify-version-check
:kill-timeout 10
# 不使用本地zookeeper
# !p10 zk bin/run-zk conf-quickstart
coordinator bin/run-druid coordinator conf-quickstart
broker bin/run-druid broker conf-quickstart
router bin/run-druid router conf-quickstart
historical bin/run-druid historical conf-quickstart
!p80 overlord bin/run-druid overlord conf-quickstart
!p90 middleManager bin/run-druid middleManager conf-quickstart
pivot bin/run-pivot-quickstart conf-quickstart
# Uncomment to use Tranquility Server
#!p95 tranquility-server bin/tranquility server -configFile conf-quickstart/tranquility/server.json
# Uncomment to use Tranquility Kafka
#!p95 tranquility-kafka bin/tranquility kafka -configFile conf-quickstart/tranquility/kafka.json
# Uncomment to use Tranquility Clarity metrics server
#!p95 tranquility-metrics-server java -Xms2g -Xmx2g -cp "dist/tranquility/lib/*:dist/tranquility/conf" com.metamx.tranquility.distribution.DistributionMain server -configFile conf-quickstart/tranquility/server-for-metrics.yaml- 启动Imply
cd /export/servers/imply-3.0.4/
nohup bin/supervise -c conf/supervise/quickstart.conf > quickstart.log &
或者( --daemonize 代表后台启动)
/export/servers/imply-3.0.4/bin/supervise -c /export/servers/imply-3.0.4/conf/supervise/quickstart.conf --daemonize- 停止imply服务
/export/servers/imply-3.0.4/bin/service --down 访问WebUI
| 组件名 | URL |
|---|---|
| broker | http://node01:8888 |
| coordinator、overlord | http://node01:8081/index.html |
| middleManager、historical | http://node01:8090/console.html |
Python3安装
- 首先去Anaconda官网下载安装脚本
Anaconda3-2019.07-Linux-x86_64.sh
-
上传Anaconda3-2019.07-Linux-x86_64.sh到 /export/softwares
-
运行Anaconda3-2019.07-Linux-x86_64.sh脚本
sh Anaconda3-2019.07-Linux-x86_64.sh安装过程输入:回车、yes、
Anaconda安装目录设置为:/export/servers/anaconda
- 配置环境变量
vim /etc/profile
#Anaconda
export PATH=$PATH:/export/servers/anaconda/bin
source /etc/profile- 验证是否安装python3成功
python3提示出现python3.x版本即安装成功!!
退出使用quit();
注意:对于重新打开的终端连接会出现base字样,消除方法:
若在终端中输入conda deactivate,也可消除base字样,但是一次性的,再次打开终端依然存在base字样。在.bashrc文件(home目录下)添加命令:conda deactivate可以永久消除base字样。至此python3已经安装成功。
SuperSet安装
- 安装依赖
yum upgrade python-setuptools
yum install gcc gcc-c++ libffi-devel python-devel python-pip python-wheel openssl-devel libsasl2-devel openldap-devel- pip安装superset
cd /export/servers/anaconda/
pip install superset需要联网下载文件等待一段时间
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ooGNaxyD-1589797262654)(assets/1571493314416.png)]
- 创建管理员用户名和密码
fabmanager create-admin --app superset[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mh3pRUyA-1589797262656)(assets/1571493718318.png)]
- 记住以下信息,登录使用:
Username [admin]: admin
User first name [admin]: admin
User last name [user]: admin
Email [admin@fab.org]:
Password: 123456
Repeat for confirmation: 123456
Recognized Database Authentications.
Admin User admin created.
- 初始化superset
superset db upgrade- 装载初始化数据
superset load_examples- 创建默认角色和权限
superset init- 启动superset
superset run -h node3 -p 8080 --with-threads --reload --debugger[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fR1rdQm6-1589797262658)(assets/1571529541183.png)]
- 登录superset
http://node01:8080
用户名: admin
密码:123456
启动命令集合
# 时间同步
/etc/init.d/ntpd restart
# Zookeeper后台启动
/export/servers/zookeeper-3.4.9/bin/zkServer.sh start
# 一键启动Hadoop
start-all.sh
# 启动HDFS
# start-dfs.sh
# 启动Yarn
# start-yarn.sh
# 退出hdfs safemode
hdfs dfsadmin -safemode leave
# 启动jobhistory
mr-jobhistory-daemon.sh start historyserver
# 启动Mysql(开机自启,不用手动启动了)
/etc/init.d/mysqld start
# 启动Hive
cd /export/servers/apache-hive-2.1.1-bin
nohup bin/hive --service hiveserver2 > /dev/null 2>&1 &
nohup bin/hive --service metastore > /dev/null 2>&1 &
# 启动Hbase
start-hbase.sh
# 启动Phoenix
cd /export/servers/apache-phoenix-4.14.0-HBase-1.1-bin/bin
./sqlline.py node01:2181
# 启动Kafka
cd /export/servers/kafka_2.11-0.11.0.2
nohup bin/kafka-server-start.sh config/server.properties > /dev/null 2>&1 &
# 启动Kafka-manager
rm -rf /export/servers/kafka-manager-1.3.3.7/RUNNING_PID
nohup /export/servers/kafka-manager-1.3.3.7/bin/kafka-manager -Dconfig.file=/export/servers/kafka-manager-1.3.3.7/conf/application.conf -Dhttp.port=9000 2>&1 &
# 启动kylin
cd /export/servers/apache-kylin-2.6.3-bin-hbase1x
bin/kylin.sh start
# 启动Redis(开机自启动)
/usr/local/redis/bin/redis-server /usr/local/redis/etc/redis.conf
# 启动Canal
/export/servers/canal/bin/stop.sh
/export/servers/canal/bin/startup.sh
# 停止Imply
/export/servers/imply-3.0.4/bin/service --down
# 启动Imply
cd /export/servers/imply-3.0.4/
nohup bin/supervise -c conf/supervise/quickstart.conf > quickstart.log &
# 启动点击流日志模拟程序[数仓使用]
cd /export/servers/itcast_dw_pvuvlog-1.0/bin
sh startup.sh
# 启动Flume采集点击流日志到Kafka[数仓使用]
cd /export/servers/apache-flume-1.8.0-bin
bin/flume-ng agent -c conf -f conf/exec_source_kafka_sink.conf -n a1 -Dflume.root.logger=INFO,console
# 启动Superset
superset run -h node01 -p 8080 --with-threads --reload --debugger
访问地址: `http://node01:8080`
用户名: admin
密码:123456admin
密码:123456
启动命令集合
# 时间同步
/etc/init.d/ntpd restart
# Zookeeper后台启动
/export/servers/zookeeper-3.4.9/bin/zkServer.sh start
# 一键启动Hadoop
start-all.sh
# 启动HDFS
# start-dfs.sh
# 启动Yarn
# start-yarn.sh
# 退出hdfs safemode
hdfs dfsadmin -safemode leave
# 启动jobhistory
mr-jobhistory-daemon.sh start historyserver
# 启动Mysql(开机自启,不用手动启动了)
/etc/init.d/mysqld start
# 启动Hive
cd /export/servers/apache-hive-2.1.1-bin
nohup bin/hive --service hiveserver2 > /dev/null 2>&1 &
nohup bin/hive --service metastore > /dev/null 2>&1 &
# 启动Hbase
start-hbase.sh
# 启动Phoenix
cd /export/servers/apache-phoenix-4.14.0-HBase-1.1-bin/bin
./sqlline.py node01:2181
# 启动Kafka
cd /export/servers/kafka_2.11-0.11.0.2
nohup bin/kafka-server-start.sh config/server.properties > /dev/null 2>&1 &
# 启动Kafka-manager
rm -rf /export/servers/kafka-manager-1.3.3.7/RUNNING_PID
nohup /export/servers/kafka-manager-1.3.3.7/bin/kafka-manager -Dconfig.file=/export/servers/kafka-manager-1.3.3.7/conf/application.conf -Dhttp.port=9000 2>&1 &
# 启动kylin
cd /export/servers/apache-kylin-2.6.3-bin-hbase1x
bin/kylin.sh start
# 启动Redis(开机自启动)
/usr/local/redis/bin/redis-server /usr/local/redis/etc/redis.conf
# 启动Canal
/export/servers/canal/bin/stop.sh
/export/servers/canal/bin/startup.sh
# 停止Imply
/export/servers/imply-3.0.4/bin/service --down
# 启动Imply
cd /export/servers/imply-3.0.4/
nohup bin/supervise -c conf/supervise/quickstart.conf > quickstart.log &
# 启动点击流日志模拟程序[数仓使用]
cd /export/servers/itcast_dw_pvuvlog-1.0/bin
sh startup.sh
# 启动Flume采集点击流日志到Kafka[数仓使用]
cd /export/servers/apache-flume-1.8.0-bin
bin/flume-ng agent -c conf -f conf/exec_source_kafka_sink.conf -n a1 -Dflume.root.logger=INFO,console
# 启动Superset
superset run -h node01 -p 8080 --with-threads --reload --debugger
访问地址: `http://node01:8080`
用户名: admin
密码:123456