数据分析项目实战一【缺失值和异常值的处理】
1.导入相关python包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
#导入缺失数值图像展示的包
import missingno as msno
2.读取数据
data=pd.read_csv(r'H:\阿里云\泰坦尼克号\train.csv')
data_test=pd.read_csv(r'H:\阿里云\泰坦尼克号\test.csv')

3.#查看训练数据的缺失数据
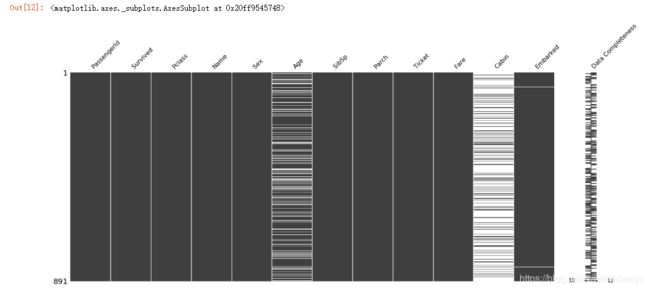
msno.matrix(data)

msno.matrix(data,labels=True)#True显示坐标题 False不显示做标题
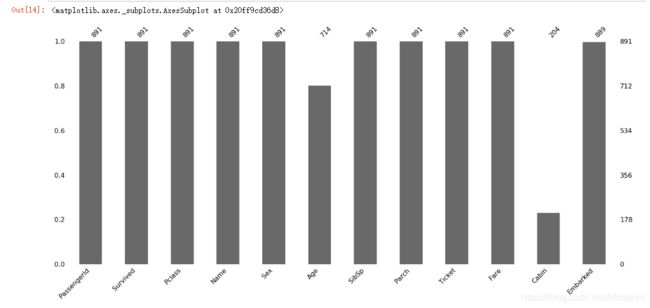
4.#条形图
msno.bar(data)
#查看测试数据
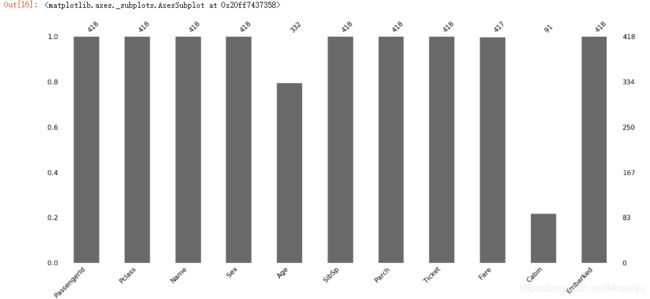
5.缺失值处理
a=data.fillna(0)#把所有的缺失值,填充为0
a
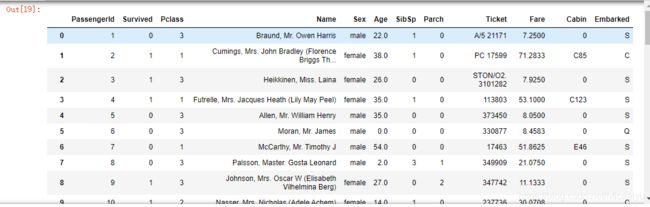
6.检查缺失填充情况
msno.matrix(a)#这样我们可以很清楚的看出 缺失值已经被填充

7.用前一个值进行填充
data.fillna(method='pad')
8.用后一个值进行填充
data.fillna(method='bfill')
9.用平均值进行填充
data['Age'].fillna(np.mean(data['Age']))

其中np.mean()函数的用法
mean() 函数定义:
numpy.mean(a, axis, dtype, out,keepdims )
mean()函数功能:求取均值
经常操作的参数为axis,以m * n矩阵举例:
axis 不设置值,对 mn 个数求均值,返回一个实数
axis = 0:压缩行,对各列求均值,返回 1 n 矩阵
axis =1 :压缩列,对各行求均值,返回 m *1 矩阵

矩阵的操作
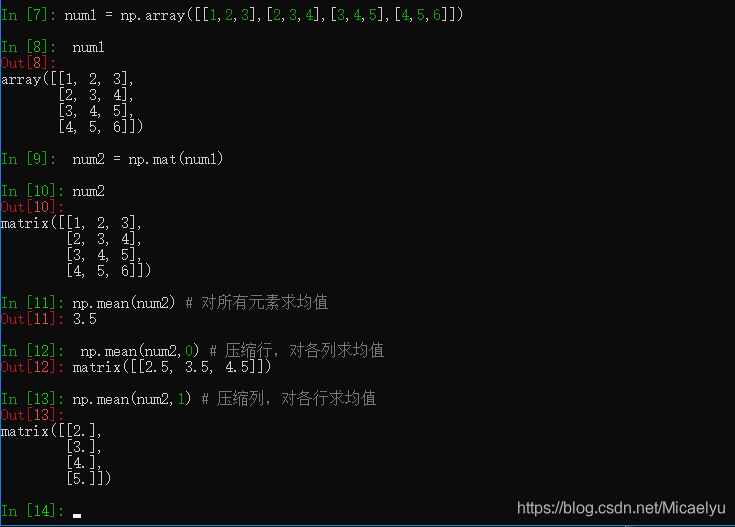
这下能理解‘np.mean(data[‘Age’]’这条语句了吧
9.1现在我们把测试数据集中的年龄数据用数据集代替
data_test['Age']=data_test['Age'].fillna(np.mean(data['Age']))

10.查看填充数据的基本方法,原函数

 这里面主要讲解了几种填充的方法
这里面主要讲解了几种填充的方法
11.我们用替换的方式填充
data.replace(to_replace=np.nan,value=-99)
#如何选取将被替换的值:to_replace
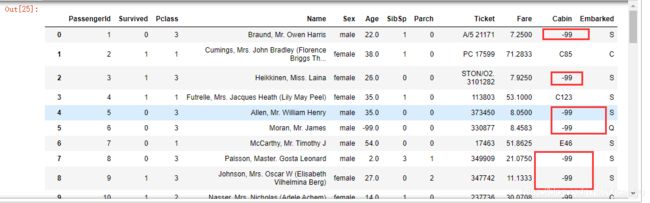
12.采用线性插值进行填充
data.interpolate(method='linear',limit_direction='forward')
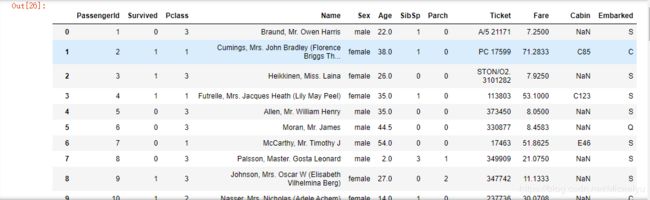
其中解释df.interpolate()函数
(1)df.interpolate()
DataFrame.interpolate(method=‘linear’, axis=0, limit=None, inplace=False, limit_direction=‘forward’, limit_area=None, downcast=None, **kwargs)
参考文档
插值方式
nearest:最邻近插值法
zero:阶梯插值
slinear、linear:线性插值
quadratic、cubic:2、3阶B样条曲线插值
参考文档

df.replace()函数
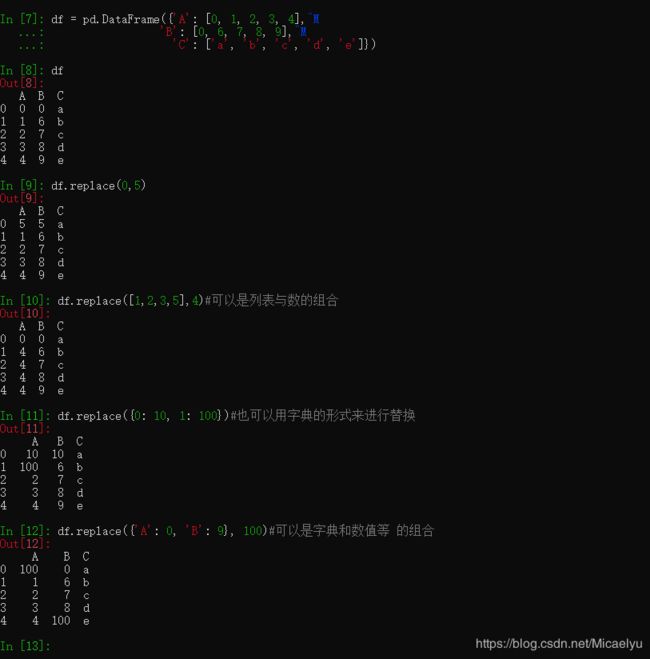
13#删除缺失值
print('训练数据条数',len(data))
print('删除数据删除nan后的条数',len(data.dropna()))
![]()
13.1#删除全部都是nan的数据
print('训练数据条数',len(data))
print('删除全部都是nan的后数据',len(data.dropna(how='all')))
![]()
13.2#删除行中至少有一个nan的数据
print('训练数据条数',len(data))
print('训练数据删除行中至少有一个nan后的数据',len(data.dropna(axis=0)))
![]()
13.3#删除行列中至少有一个nan的数据
print('训练数据列数',len(data.columns))
print('训练数据全部都是nan后的数据',len(data.dropna(axis=1).columns)
![]()
all表示是这一行或者一列中的所有数据都为nan值,才删除
any表示这一行或者一列中只要有一个位nan值,才删除
上面的结果,均为删除空值之后,剩余的数据