datax 中Transformer的使用
datax中的Transformer的使用
建议看一下datax的源码哦!其实没有我们想象的那么复杂...
官网上也有些示例代码的。请看地址:https://github.com/alibaba/DataX/tree/master/core/src/main/java/com/alibaba/datax/core/transport/transformer
类似截图:
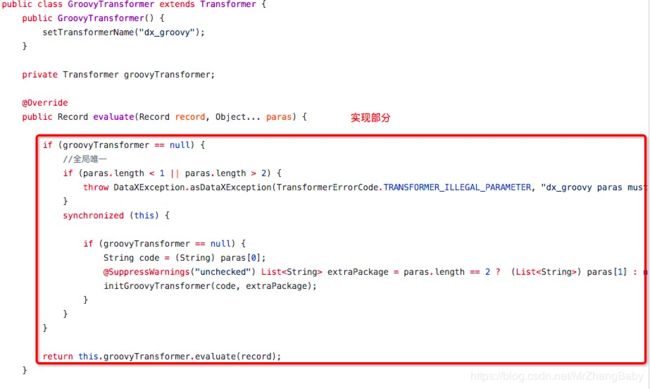
详细实践
同步配置如下:(我把相关连接了,域名了省略了...)
{
"content": [
{
"reader": {
"name": "hivereader",
"parameter": {
"column": [
...
{
"name": "stat_date",
"type": "string"
},
...
],
"hive2Url": "jdbc:hive2://xxxxxxx:xxxx/test_dev_2",
"modifyUserName": "xxxxxxx",
"partition": "ds=20190424",
"table": "xxx",
"username": "hive"
}
},
"writer": {
"name": "adswriter",
"parameter": {
"column": [
...
"stat_date"
...
],
"modifyUserName": "xxxxxxxxxxxxxx",
"partition": "id=20190424",
"partitionKey": [
"id"
],
"partitionValue": [
"20190424"
],
"password": "******************************",
"schema": "xxxx",
"table": "xxxx",
"url": "xxxxxxx:xxxxx",
"username": "xxxxxxxxxxxxxx",
"writeMode": "insert"
}
}
}
],
"setting": {
"errorLimit": {
"record": 0
},
"speed": {
"channel": 5,
"throttle": false
}
}
}添加完Transform的配置:
{
"content": [
{
"reader": {
"name": "hivereader",
"parameter": {
"column": [
...
],
"hive2Url": "jdbc:hive2://xxxxxxx:xxxx/test_dev_2",
"modifyUserName": "xxxxxxxxxxxxxx",
"partition": "ds=20190424",
"table": "xxx",
"username": "hive"
}
},
"transformer": [
{
"name": "dx_groovy",
"parameter": {
"code": "return record",
"extraPackage": [
"import groovy.json.JsonSlurper;"
]
}
}
],
"writer": {
"name": "adswriter",
"parameter": {
"column": [
...
],
"modifyUserName": "xxxxxxxxxxx",
"partition": "id=20190424",
"partitionKey": [
"id"
],
"partitionValue": [
"20190424"
],
"password": "******************************",
"schema": "xxx",
"table": "xxx",
"url": "xxxxxxxxxxxxxxxxxxxxx:xxxxxxx",
"username": "xxxxxxx",
"writeMode": "insert"
}
}
}
],
"setting": {
"errorLimit": {
"record": 0
},
"speed": {
"channel": 5,
"throttle": false
}
}
}
使用注意事项
“name” : 对应的datax中自定义Transformer名字, 固定格式: dx_groovy
“parameter”: Transformer参数
“code” : 需要对同步表进行的数据的逻辑操作(在idea或eclipse中继承Transformer类重写evaluate方法.得到record对象), code里面的东西不能随便换行,整个transformer是正确的json. 定义变量用def 进行定义,会自动类型转化
“extraPackage”: 不支持引入第三方jar包.只能用自身的.
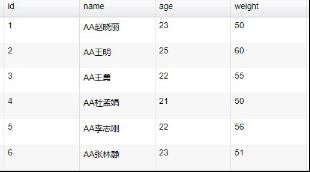
建议大家下载dataX源码看看哈~数据字段头部增加字符
{
"name":"dx_groovy",
"parameter":{
"code":"Column column = record.getColumn(1);def str = column.asString();def sb = new StringBuffer(str);def header = sb.insert(0,'AA');def strHearder = header.toString();record.setColumn(1, new StringColumn(strHearder));return record",
"extraPackage":[
"import groovy.json.JsonSlurper;"
]
}
}结果图:
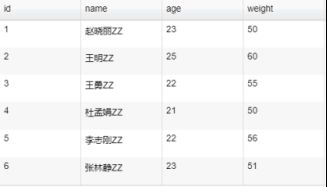
数据字段尾部添加字符
{
"name":"dx_groovy",
"parameter":{
"code":"Column column = record.getColumn(1);def str = column.asString();def sb = new StringBuffer(str);def tail = sb.append('ZZ');def strTail = tail.toString();record.setColumn(1, new StringColumn(strTail));return record",
"extraPackage":[
"import groovy.json.JsonSlurper;"
]
}
}结果图:
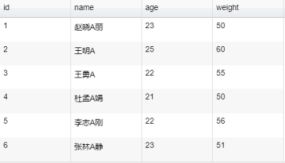
数据字段中间插入字符
{
"name":"dx_groovy",
"parameter":{
"code":"Column column = record.getColumn(1);def str = column.asString();def sb = new StringBuffer(str);def mid = sb.insert(2,'A');def strMid = mid.toString();record.setColumn(1, new StringColumn(strMid));return record",
"extraPackage":[
"import groovy.json.JsonSlurper;"
]
}
}结果图
数据字段字符转换
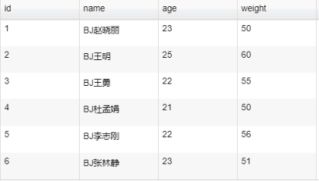
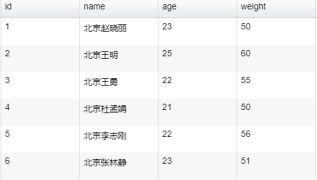
{
"name":"dx_groovy",
"parameter":{
"code":"Column column = record.getColumn(1);def str = column.asString();def newStr=null;if(str.contains('BJ')){newStr=str.replaceAll('BJ', '北京');record.setColumn(1, new StringColumn(newStr));};return record",
"extraPackage":[
"import groovy.json.JsonSlurper;"
]
}
}结果图:
数据字段归零
{
"name":"dx_groovy",
"parameter":{
"code":"Column column = record.getColumn(1);def str = column.asString();str='0';record.setColumn(1, new StringColumn(str));return record",
"extraPackage":[
"import groovy.json.JsonSlurper;"
]
}结果图:
