BatchNormalization论文感想
https://app.yinxiang.com/shard/s48/nl/21527065/871c1315-af21-44ae-8cb0-cfc2bfa2d483
开始之前:
本次算法组推荐的论文是SN(switch normalization),是一种在训练过程中解决数据归一化的方法,由港中文大学18年7月提出。此前何凯明于18年3月提出GN(Group normalization)是基于google15年提出的BN(batch normalization)方法,为未来复现SN或GN方法运用到不同框架的检测任务作准备,我将用2到3周从BN开始精度论文和查阅资料,在周四分享与讨论。
本次分享的是Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift这篇文章,BN一经出世就被各个深度学习前沿技术与模型广泛使用,至今仍然是数据归一化的主流方法.本次presentation我将通过论文仔细解读它的实现和原理,以及文中几个需要注意的点.
1.为什么要normalization
训练的参数常常会因为每层数据分布的改变而改变,在BN没有出现之前我们不得不花很大精力去初始化参数以及在模型训练时设置一个小的学习率来防止梯度爆炸或梯度消失。
Google在15年提出了Batch normalizetion,基于mini-batch SGD的训练模式下,对batch这一维度进行归一化。首先为什么要归一化,归一化有什么好处:
(图片来自网络)
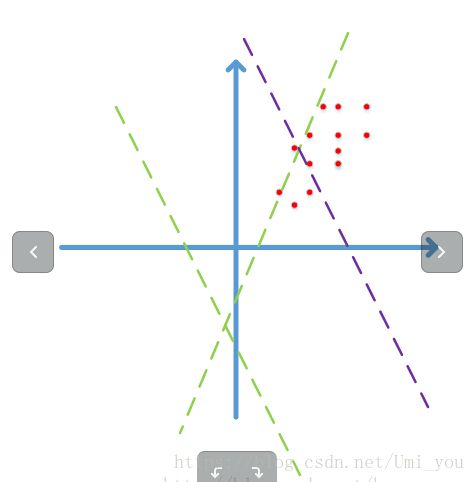
例如对于图像而言,图像数据主要分布在0-255之间,并且具有很强的相关性.以二维数据为例,图中展示的是一个图像像素点在二维空间的分布情况(图像维度更加大,为wh维),像素点之间的强关联性以及分布0-255的特性使得他们都集中分布在第一象限.通过某层网络之后,即Wx+b(其实是w1x1+w2x2+b)的结果要经过激活函数,而此时的这条线(也就是激活函数,激活函数的作用通俗来说是把Wx+b给区分开,如Relu是把大于0的数据保持不变并且梯度为1,小于0的置为0;sigmoid是把数据映射到一个0到1的递增区间,并且给越接近0的区域给一个大的梯度值,越远离0的区域给一个很低的梯度值),这条线表(Wx+b=0)大概率是不在数据分布中间(如图中绿线),而是聚集成长条状远离w1x1+w2*x2+b=0这条线的,即Wx+b这个结果非常大或者非常小(sigmoid很难分开),或者都坐落于直线一端(Relu很难分开)。
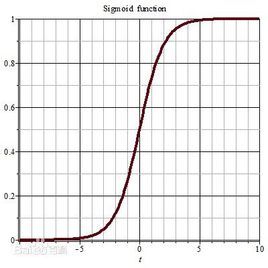
1.假设这个激活函数是sigmoid函数:
Wx+b的值全部都非常大或者非常小的值,进入sigmoid函数会进入饱和区,饱和区的梯度会非常小,产生梯度弥散,参数更新速度会很慢。
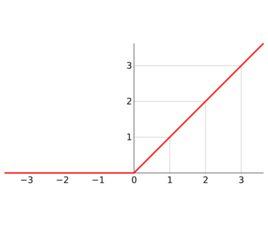
2.ReLU
Wx+b的值全部都分布在一边,经过Relu后大部分都置为0(Wx+b<0)或者相当于没有被激活(Wx+b>0)
而这些情况不仅存在于模型输入,在网络内部每一层都会出现,并且随着网络的加深,一点点微小的变化都会对引起很大的蝴蝶效应,使得每层的输入分布发生很大的改变,训练过程中权重需要花很长时间去不停的调整来适应每一层不同的数据分布,导致学习效率很低.所以在网络训练初期我们不得不精心初始化权重并且使用小的学习率来训练(怎么初始化:高斯分布 和为什么要使用小的学习率1.梯度消失和爆炸2.容易陷入局部最优).
上述讲到的问题称作:内部协变量偏移(ICS,internal covariate shift),训练过程中层与层之间参数和数据分布的变化导致的一系列问题(解释ICS).
这还仅仅是二维空间的假设,对于高维的图像,数据的分布可能范围更加狭小并且集中在某个区域,因此如果不对数据进行一些预处理的话会带来很多运算资源的浪费.
数据预处理方法:
1.PCA白化过程:
先0均值再作协方差矩阵,然后求特征向量和特征值,将原始数据投影(映射)到以特征向量为基的样本空间中,得到新的坐标,再利用新的坐标除以标准差(即对应的特征值开根号),除以标准差后就是PCA白化的结果,此时的数据分布将无相关性并且缩放后方差为1.(相关性:假设数据分析中,房屋的价格和房屋的面积是正相关的,但不一定是线性相关,只是具有相关性)
2.ZCA白化…PCA处理后的新数据分布(左乘特征矩阵的转置)重新映射回原始的样本空间,此时的数据分布会更加接近原始数据.
总结上述过程:PCA是将数据投影到另一个空间这个空间数据之间无冗余性(相关性),除以各个维度的标准差之后就是PCA白化,将PCA白化之后的数据再映射回原空间就是ZCA白化。
虽然PCA效果很好,但要对每一层都计算的话计算成本非常大,所以BN选用了更加简单的方式:减均值除以方差,归一化为一个标准的高斯分布(与PCA对比).
虽说对于所有数据集都使用归一化是可行的,但是使用full batch却不切实际(显存不够,而且要计算的epoch数量奇大),因此使用mini-batch SGD优化(不容易陷入局部最优也解决上述两个问题),由每个mini-batch的样本来计算它们的期望和方差.mini-batch size大概率会比维度小,如果用PCA方法白化的时候求协方差矩阵的时候可能生成的是奇异矩阵,即可能存在两组输入存在线性关系不可能完全消除特征之间的相关性.这也是不使用PCA白化的原因之一.
针对一个全连接的训练过程,计算均值和方差的方向为每个特征维度,B中的为一个mini-batch的样本集合

以上已经用简化的方式解决了数据归一化问题(0均值,1方差的正太分布),也即ICS问题,但是通过这种方式我们也同样丢失了表达原始数据的能力(比如说我们将0-255归一化为-1到1的分布,新的分布很难去衡量图像之间的信息关系,也就是表达图像信息的能力),同时,0均值1方差的分布如果用的是sigmoid或者tanh作为激活函数,那么它们都会被限制到非线性激活函数的线性区域,
所以在文章中,加入了两个可学习的变量,伽玛和贝塔。确保被网络转换过的数据分布能够恒等映射回原始的数据分布。这一步其实有点像ZCA白化之与PCA白化…特殊情况下当(噶吗=方差开根号,贝塔等于期望时)的时候新数据经过噶吗和贝塔能够映射回原始数据.噶吗和贝塔的存在应该仅仅是为了确保数据有能够映射回原始数据分布的能力,至于具体映射成什么样就要看两个参数学习成什么样。对于每一个维度都有一组相应的可学习参数伽玛和贝塔.

为了保留CNN的特性,针对具有CNN的网络结构,文章使用了特别的归一化方法,具体差别在于归一化所用集合和上文提到的归一化集合有差别:
在CNN的BN方法中,一次BN过程的集合不是针对一个维度(即一张特征图上某个特定坐标),而是包含了一张feature map的所有坐标(location),即对于不同样本的同一张feature map都训练一组伽玛和贝塔参数。(画图说明)

BN该放在哪:
虽说我们能够将BN放在每层的原始输入之前,但这一层的原始输入是上一层激活函数的输出,在训练过程中数据分布很大可能会改变,依然不能消除ICS问题,相比之下 Wx+b之后的数据为对称非稀疏,分布更加稳定.

防止过拟合:
在训练过程中联合了同一个batch中的其他样本,对于给定的一个样本经过模型后不容易产生固定的值,即一个样本不仅给出它自己的信息,还附带整个batch中样本的全局信息,等于变相地增加了模型的范化能力,减少过拟合
实验结果:
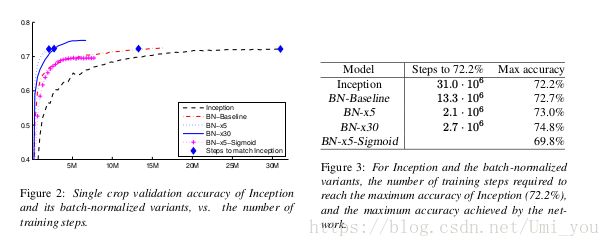
可以看出使用BN的inception模型收敛速度比原始inception模型更快,并且准确率有所上升(防止过拟合作用),直接加入BN的效果也并不能起到最好的作用,所以实验使调整了其他参数来对比,以下实验都将BN层放在非线性激活函数之前,其中:
BN-x5:增加学习率至0.0075,为原来的5倍,使得学习速率更快(允许使用大的学习率);减少了dropout和L2正则化(表可以看出准确率并没有下降),加速了学习率衰减速度,移除局部响应归一化(实验发现对于有BN的网络来说不必要),完全打乱训练数据,减少光度扭曲。
BN-X30:学习率改为30倍其他和x5一样,发现收敛速率有所下降,但是准确率上升了(?),说明加入BN能够允许使用的大学习率还是有上限。
BN-X5-Sigmoid:用sigmoid代替ReLU.实验也将原始Inception的激活函数替换为率Sigmoid但是和BN-X5的实验结果一样。这个模型验证了,如果使用了sigmoid函数,BN层将数据分布限制在了非线性激活函数的线性部分(也即sigmoid函数梯度很大的区域),导致了此激活函数的划分数据的效果变差(因为sigmoid激活函数划分数据的方法为,将接近0那一部分的高梯度部分和远离0的低梯度部分),因为BN将数据分布归一化到0均值,1方差,再通过伽玛和贝塔稍稍映射回一点,所以BN的数据在sigmoid函数中都集中在高梯度部分。而Relu是以0为分解点,所以没多大影响.
总结BN作用:
1.消除ICS内部协变量偏移问题,防止数据一直待在饱和区,加速收敛
2.可以防止初始化的权重在训练初期太敏感,省去了精心初始化权重的时间,
3.反复更新来适应不同的数据分布,从而允许使用较大的学习率,加速学习速率(梯度消失和爆炸,陷入局部最优)。
4.防止过拟合