深度学习论文分享(三)Look More but Care Less in Video Recognition(NIPS2022)
深度学习论文分享(三)Look More but Care Less in Video Recognition(NIPS2022)
- 前言
-
- Abstract
- 1. Introduction
- 2 Related Work
-
- 2.1 Video Recognition
- 2.2 Redundancy in Data(数据冗余)
- 3 Methodology
-
- 3.1 Architecture Design
- 3.2 Implicit Temporal Modeling隐式时间建模
- 3.3 Spatial Redundancy Reduction空间冗余减少
- 3.4 Loss functions
- 4 Empirical Validation
-
- 4.1 Comparisons with Existing Methods
- 4.2 Visualizations
- 4.3 Ablation Study
- 5 Conclusion
- Acknowledgments and Disclosure of Funding
- References
- Appendix
-
- A. 实验设置
- B. Building AFNet on BasicBlock
- C. Building AFNet wtih More Frames
- D. More Ablation of AFNet
- E. Limitations and Potential Negative Societal Impacts
前言
论文原文:https://arxiv.org/pdf/2211.09992.pdf
论文代码: https://github.com/BeSpontaneous/AFNet-pytorch
Title:Look More but Care Less in Video Recognition
Authors:Yitian Zhang1∗ Yue Bai1 Huan Wang1 Yi Xu1 Yun Fu1,2
1Department of Electrical and Computer Engineering, Northeastern University
2Khoury College of Computer Science, Northeastern University
在此仅做翻译(经过个人修改,有基础的话应该不难理解),有时间会有详细精读笔记。
Abstract
现有的动作识别方法通常会采样几帧来表示每个视频,以避免大量的计算,这往往会限制识别性能。为了解决这个问题,我们提出了 Ample and Focal Network (AFNet),它由两个分支组成,以利用更多的帧但计算量更少。具体来说,Ample Branch 通过压缩计算获取所有输入帧以获得丰富的信息,并通过所提出的 Navigation Module 为 Focal Branch 提供指导;焦点分支压缩时间大小以仅关注每个卷积块的显着帧;最后自适应融合两个分支的结果,防止信息丢失。通过这种设计,我们可以向网络引入更多帧,但计算成本更低。此外,我们证明 AFNet 可以利用更少的帧,同时实现更高的精度,因为中间特征中的动态选择强制执行隐式时间建模。此外,我们表明我们的方法可以扩展到以更低的成本减少空间冗余。对五个数据集的大量实验证明了我们方法的有效性和效率。我们的代码可在 https://github.com/BeSpontaneous/AFNet-pytorch 获取。
1. Introduction
在线视频近年来发展迅速,视频分析对于推荐 [6]、监控 [4、5] 和自动驾驶 [33、18] 等许多应用来说都是必需的。这些应用程序不仅需要准确而且高效的视频理解算法。随着深度学习网络 [3] 在视频识别中的引入,该领域方法的性能得到了快速提升。这些深度学习方法虽然成功,但通常需要大量计算,因此很难在现实世界中部署。
在视频识别中,我们需要对多个帧进行采样来表示每个视频,这使得计算成本与采样帧的数量成正比。在大多数情况下,每个输入都对所有帧的一小部分进行采样,其中仅包含原始视频的有限信息。一个直接的解决方案是对网络采样更多的帧,但计算会按比例扩展到采样帧的数量。
最近提出了一些工作来动态采样显着帧 [31、17] 以提高效率。这些方法的选择步骤是在帧被发送到分类网络之前进行的,这意味着那些不重要的帧的信息完全丢失并且选择过程消耗了相当多的时间。一些其他方法提出通过根据每个帧的重要性自适应调整分辨率大小来解决动作识别中的空间冗余 [24],或为每个帧裁剪最显着的补丁 [30]。然而,这些方法仍然完全抛弃了网络认为不重要的信息,并引入策略网络为每个样本做出决策,这导致额外的计算并使训练策略复杂化。
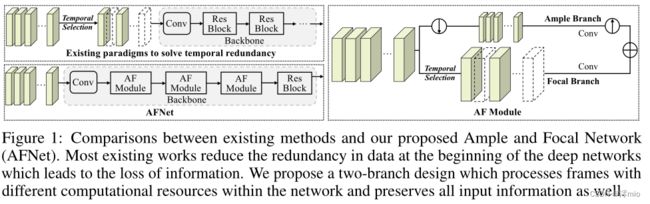
图 1:现有方法与我们提出的 Ample and Focal Network (AFNet) 之间的比较。大多数现有工作减少了深度网络开始时的数据冗余,从而导致信息丢失。我们提出了一种双分支设计,它处理网络中具有不同计算资源的帧,并保留所有输入信息。
在我们的工作中,与以往的工作相比,我们从另一个角度出发。我们提出了一种在分类网络中进行帧选择的方法。如图 1 所示,我们设计了一个名为 Ample and Focal Network (AFNet) 的架构,它由两个分支组成:ample 分支通过轻量级计算瞥见所有输入特征,因为我们对特征进行下采样以获得更小的分辨率并进一步减少渠道规模;焦点分支接收来自建议的导航模块的指导,通过仅对选定帧进行计算来压缩时间大小以节省成本;最后,我们自适应地融合这两个分支的特征,以防止未选择帧的信息丢失。
通过这种方式,这两个分支都非常轻量级,我们使 AFNet 能够通过对更多帧进行采样来扩大视野,并专注于重要信息以减少计算量。以统一的方式考虑这两个分支,一方面,与其他动态方法相比,我们可以避免信息丢失,因为充足的分支保留了所有输入的信息;另一方面,我们可以通过在每个卷积块中禁用它们来抑制不重要帧的噪声。此外,我们已经证明,中间特征的动态选择策略有利于时间建模,因为它隐含地实现了逐帧关注,这可以使我们的网络在获得更高准确性的同时利用更少的帧。此外,我们没有引入策略网络来选择框架,而是设计了一个可以插入网络的轻量级导航模块,这样我们的方法就可以轻松地以端到端的方式进行训练。此外,AFNet 与空间自适应工作兼容,这有助于进一步减少我们方法的计算量。
我们将主要贡献总结如下:
• 我们提出了一个自适应双分支框架,使 2D-CNN 能够以更少的计算成本处理更多的帧。通过这种设计,我们不仅可以防止信息丢失,还可以加强基本帧的表示。
• 我们提出了一个轻量级导航模块,可以在每个卷积块上动态选择显着帧,这可以很容易地以端到端的方式进行训练。
• 中间特征的选择策略不仅使模型具有很强的灵活性,因为将在不同的层选择不同的帧,而且还强制执行隐式时间建模,使 AFNet 能够以更少的帧获得更高的精度。
• 我们对五个视频识别数据集进行了综合实验。结果显示了 AFNet 与其他竞争方法相比的优越性。
2 Related Work
2.1 Video Recognition
近年来深度学习的发展对视频识别的研究起到了巨大的推动作用。此任务的一种直接方法是使用 2D-CNN 提取采样帧的特征,并使用特定的聚合方法对帧间的时间关系进行建模。例如,TSN [29] 建议对帧之间的时间信息进行平均。而 TSM [21] 移动相邻帧的通道以允许在时间维度上进行信息交换。另一种方法是构建 3D-CNN 以进行时空学习,例如 C3D [27]、I3D [3] 和 SlowFast [9]。尽管被证明是有效的,但基于 3D-CNN 的方法在计算上非常昂贵,这给实际部署带来了很大困难。
虽然 SlowFast 探索了双分支设计,但我们的动机和详细结构在以下方面与其不同:1)网络类别:SlowFast 是静态 3D 模型,而 AFNet 是动态 2D 网络; 2)动机:SlowFast旨在收集语义信息并以不同的时间速度改变分支的运动以获得更好的性能,而AFNet旨在动态跳帧以节省计算量,双分支结构的设计是为了防止信息丢失; 3)具体设计:AFNet旨在在充足的分支下对特征进行下采样以提高效率,而SlowFast在原始分辨率下处理特征; 4) 时间建模:SlowFast 将 3D 卷积应用于时间建模,AFNet 是一个 2D 模型,由设计的导航模块通过隐式时间建模强制执行。
2.2 Redundancy in Data(数据冗余)
近年来,二维 CNN 的效率得到了广泛研究。虽然一些工作旨在设计高效的网络结构 [14],但还有另一项研究侧重于减少基于图像的数据中的固有冗余 [34、12]。在视频识别中,人们通常对有限数量的帧进行采样来表示每个视频,以防止大量的计算成本。尽管如此,视频识别的计算对于研究人员来说仍然是一个沉重的负担,解决这个问题的常用策略是减少视频中的时间冗余,因为并非所有帧对于最终预测都是必不可少的。 [35] 提出使用强化学习来跳帧进行动作检测。还有其他作品 [31, 17] 动态采样显着帧以节省计算成本。由于空间冗余广泛存在于基于图像的数据中,[24] 自适应地处理具有不同分辨率的帧。 [30] 提供的解决方案是为每一帧裁剪最显着的补丁。然而,这些作品的未选择区域或框架被完全放弃。因此,在他们设计的程序中会丢失一些信息。此外,这些作品中的大多数采用策略网络来做出动态决策,这会以某种方式引入额外的计算并将训练分为几个阶段。相比之下,我们的方法采用双分支设计,根据每一帧的重要性分配不同的计算资源,防止信息丢失。此外,我们设计了一个轻量级的导航模块来引导网络去哪里看,它可以被纳入骨干网络并以端到端的方式进行训练。此外,我们验证了中间特征的动态帧选择不仅会赋予模型强大的灵活性,因为将在不同的层选择不同的帧,而且会导致学习的逐帧权重,从而强制执行隐式时间建模。
3 Methodology
直观地,考虑更多帧可以增强时间建模,但会导致更高的计算成本。为了有效地实现竞争性能,我们建议 AFNet 涉及更多帧,但明智地从中提取信息以保持较低的计算成本。具体来说,我们设计了一个双分支结构来根据帧的重要性区别对待帧,并以自适应的方式处理特征,这可以为我们的方法提供强大的灵活性。此外,我们证明了中间特征中帧的动态选择会导致学习到的帧权重,这可以被视为隐式时间建模。
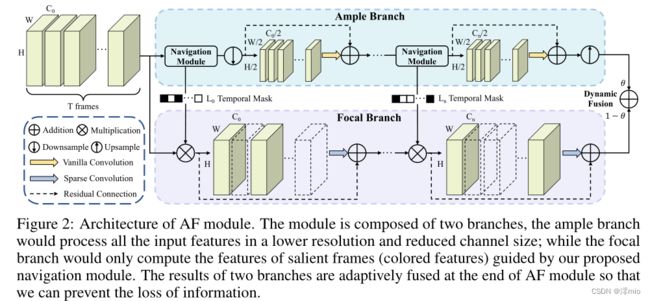 图 2:AF 模块的架构。该模块由两个分支组成,充足的分支将以较低的分辨率和减小的通道大小处理所有输入特征;而焦点分支只会计算由我们提出的导航模块引导的显着帧的特征(彩色特征)。两个分支的结果在AF模块的末尾进行自适应融合,以防止信息丢失。
图 2:AF 模块的架构。该模块由两个分支组成,充足的分支将以较低的分辨率和减小的通道大小处理所有输入特征;而焦点分支只会计算由我们提出的导航模块引导的显着帧的特征(彩色特征)。两个分支的结果在AF模块的末尾进行自适应融合,以防止信息丢失。
3.1 Architecture Design
如图 2 所示,我们将 Ample and Focal (AF) 模块设计为双分支结构:充足的分支(顶部)以较低的分辨率和压缩的通道大小处理所有帧的丰富特征;焦点分支(底部)接收来自导航模块生成的充足分支的指导,并仅对选定的帧进行计算。这种设计可以方便地应用于现有的 CNN 结构来构建 AF 模块。
充足的分支(Ample Branch)。 ample branch 旨在包含所有计算成本低的帧,其作用是:1)指导选择显着帧以帮助 focal branch 专注于重要信息; 2) 与焦点分支的互补流,通过精心设计的融合策略防止信息丢失。
形式上,我们将视频样本 i i i表示为 v i v^i vi,其中包含 T T T 个帧,表示为 v i = v^i = vi={ f 1 i , f 2 i , . . . , f T i f^i_1, f^i_2, ..., f^i_T f1i,f2i,...,fTi}。为方便起见,如果不引起混淆,我们在以下部分中省略上标 i i i。我们将 ample 分支的输入表示为 v x ∈ R T × C × H × W v_x ∈ \mathbb{R}^{T ×C×H×W} vx∈RT×C×H×W,其中 C 表示通道大小,H × W 是空间大小。由 ample 分支生成的特征可以写成:
![]()
其中 v y a ∈ R T × ( C o / 2 ) × ( H o / 2 ) × ( W o / 2 ) v_{y^a} ∈ \mathbb{R}^{T ×(C_o/2)×(H_o/2)×(W_o/2)} vya∈RT×(Co/2)×(Ho/2)×(Wo/2)表示 ample branch 的输出, F a F^a Fa 表示一系列卷积块。而焦支(focal branch)处的通道、高度、宽度分别表示为 C o 、 H o 、 W o C_o、H_o、W_o Co、Ho、Wo。我们将第一个卷积块的步幅设置为 2 以对该分支的分辨率进行下采样,并通过最近插值对该分支末尾的特征进行上采样。
导航模块(Navigation Module)。所提出的导航模块旨在通过自适应地为视频 v i v^i vi 选择最显着的帧来引导焦点分支到哪里看。
具体来说,导航模块使用 ample branch vyan 中第 n n n 个卷积块的输出生成二进制时间掩码 L n L_n Ln。首先,将平均池化应用于 v y n a v_{y^a_n} vyna 以将空间维度调整为 1 × 1,然后我们执行卷积以将通道大小转换为 2:
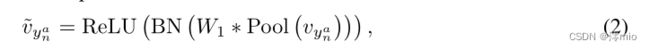
其中 ∗ * ∗ 代表卷积, W 1 W_1 W1 表示 1 × 1 卷积的权重。之后,我们将特征 v ~ y n a \tilde{v}_{y^a_n} v~yna 的维度从 T × 2 × 1 × 1 T × 2 × 1 × 1 T×2×1×1 重塑为 1 × ( 2 × T ) × 1 × 1 1 × (2 × T ) × 1 × 1 1×(2×T)×1×1 以便我们可以通过以下方式从通道维度为每个视频建模时间关系:
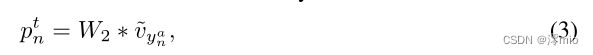
其中 W 2 W_2 W2 表示第二个 1×1 卷积的权重,它将为每个帧 t t t 生成一个二进制 logit p n t ∈ R 2 p^t_n ∈ \mathbb{R}^2 pnt∈R2,表示是否选择它。
然而,直接从这种离散分布中采样是不可微的。在这项工作中,我们应用 Gumbel-Softmax [15] 来解决这种不可微性。具体来说,我们使用 Softmax 生成归一化分类分布:
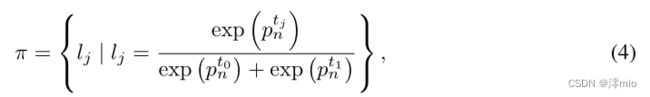
我们从分布 π 中抽取离散样本为:
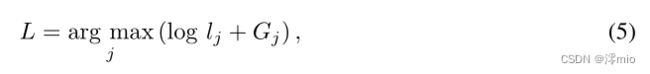
其中 G j = − l o g ( − l o g U j ) G_j = − log(− log U_j) Gj=−log(−logUj) 从 Gumbel 分布中采样, U j U_j Uj 从均匀分布的 Unif(0,1) 中采样。由于 argmax 不可微分,我们通过 Softmax 在反向传播中放宽离散样本 L L L:
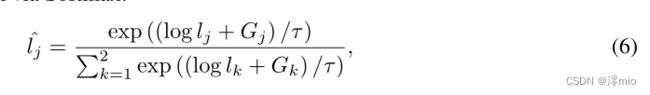
当温度因子 τ → 0 时,分布 l ^ \hat{l} l^ 将成为一个单热(one-hot)向量,我们让 τ 在训练期间从 1 减少到 0.01。
焦点分支。焦点分支由导航模块引导,仅计算选定的帧,这减少了冗余帧的计算成本和潜在噪声。
该分支中第 n n n 个卷积块的特征可以表示为 v y n f ∈ R T × C o × H o × W o v_{y^f_n} ∈ \mathbb{R}^{T ×C_o×H_o×W_o} vynf∈RT×Co×Ho×Wo。基于导航模块生成的时间掩码 Ln,我们为每个视频选择二进制掩码中具有相应非零值的帧,并仅对这些提取的帧 v y n f ′ ∈ R T l × C o × H o × W o v'_{y^f_n} ∈ \mathbb{R}^{T_l ×C_o×H_o×W_o} vynf′∈RTl×Co×Ho×Wo 应用卷积运算:

其中 F n f F^f_n Fnf 是该分支的第 n n n 个卷积块,我们将卷积组数设置为 2 以进一步减少计算量。在第 n n n个块的卷积运算之后,我们生成一个与 v y n f v_{y^f_n} vynf 共享相同形状的零张量,并通过添加 v y n f ′ v'_{y^f_n} vynf′ 和 v y n − 1 f v_{y^f_{n-1}} vyn−1f 来填充值,残差设计如下 [13]。
在这两个分支的末尾,受 [1, 12] 的启发,我们通过池化和线性层生成加权因子 θ θ θ 来融合来自两个分支的特征:
![]() 其中○表示通道乘法。
其中○表示通道乘法。
3.2 Implicit Temporal Modeling隐式时间建模
虽然我们的工作主要旨在减少像 [30、25] 这样的视频识别中的计算量,但我们证明了 AFNet 通过在中间特征中动态选择帧来强制执行隐式时间建模。考虑采用普通 ResNet[13] 结构的 TSN[29] 网络,每个阶段第 n 个卷积块的特征可以写为 v n ∈ R T × C × H × W v_n ∈ \mathbb{R}^{T ×C×H×W} vn∈RT×C×H×W。因此,第 n + 1 n + 1 n+1 个块的特征可以表示为:
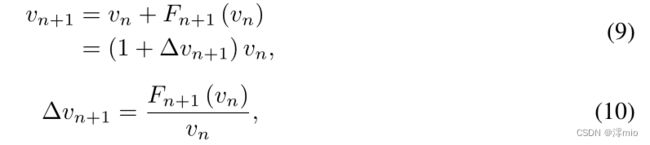
其中 F n + 1 F_{n+1} Fn+1 是第 n + 1 n + 1 n+1 个卷积块,我们将 Δ v n + 1 Δv_{n+1} Δvn+1 定义为从该块学习的系数。这样我们就可以把这个阶段 v N v_N vN的输出写成:

同样,我们将 ample 和 focal 分支中的特征定义为:
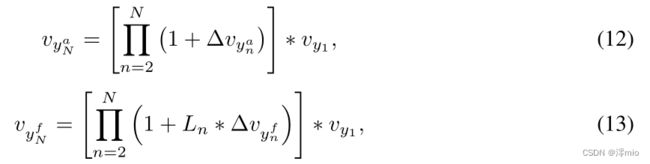
其中 L n L_n Ln 是由公式 5 生成的二进制时间掩码, v y 1 v_{y_1} vy1 表示该阶段的输入。根据等式 8,我们可以得到该阶段的输出为:
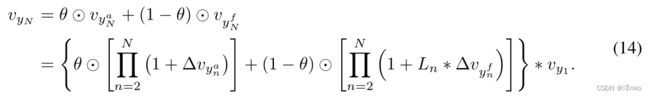
由于 L n L_n Ln 是时间方面的二进制掩码,它将决定是否在每个卷积块的每个帧中计算系数 Δ v y n f Δv_{y^f_n} Δvynf。考虑到整个阶段由多个卷积块组成,焦点分支的输出与二进制掩码 L n L_n Ln 的级数相乘将逼近软权重。这导致在每个视频中学习帧级权重,我们将其视为隐式时间建模。尽管我们没有明确构建任何时间建模模块,但方程 3 中 L n L_n Ln 的生成已经考虑了时间信息,因此学习的时间权重等于在每个阶段执行隐式时间建模。

图 3:扩展 AFNet 以减少空间冗余以进一步提高效率的图示。在推理阶段只会计算彩色区域。
3.3 Spatial Redundancy Reduction空间冗余减少
在这一部分中,我们表明我们的方法与旨在解决空间冗余问题的方法兼容。我们通过对时间掩码生成和工作 [12] 应用类似的过程来扩展导航模块,以生成第 n 个卷积块的空间逻辑,如图 3 所示:
![]()
其中 W 3 W_3 W3 表示 3 × 3 卷积的权重, W 4 W_4 W4 表示内核大小为 1 × 1 的卷积的权重。之后,我们仍然使用 Gumbel-Softmax 从离散分布中采样以生成空间掩码 M n M_n Mn 并导航焦点分支仅关注所选帧的显着区域以进一步降低成本。
3.4 Loss functions
受[29]的启发,我们取每一帧预测的平均值来表示相应视频的最终输出,我们的优化目标是最小化:

第一项是输入视频 v v v 和相应的单热标签 y y y 的预测 P ( v ) P (v) P(v) 之间的交叉熵。我们将第二项中的 r 表示为每个 mini-batch 中所选帧的比率,并将 RT 表示为训练前设置的目标比率(RS 是扩展导航模块以减少空间冗余时的目标比率)。我们通过添加第二个损失项让 r 近似 RT,并通过引入平衡这两项的因子 λ 来管理效率和准确性之间的权衡。
4 Empirical Validation
在本节中,我们进行了全面的实验来验证所提出的方法。我们首先将我们的方法与普通 2D CNN 进行比较,以证明我们的 AF 模块隐式实现了有利于时间建模的时间注意。然后,我们通过引入更多帧来验证 AFNet 的效率,但与其他方法相比计算成本更低。此外,我们展示了 AFNet 与其他高效动作识别框架相比的强大性能。最后,我们提供定性分析和广泛的消融结果来证明所提出的导航模块和双分支设计的有效性。
数据集。我们的方法在五个视频识别数据集上进行了评估:(1) Mini-Kinetics [24, 25] 是 Kinetics [16] 的一个子集,它从 Kinetics 中选择了 200 个类,包含 121k 训练视频和 10k 验证视频; (2) ActivityNet-v1.3 [2] 是一个未修剪的数据集,有 200 个动作类别,平均持续时间为 117 秒。它包含 10,024 个用于训练的视频样本和 4,926 个用于验证的视频样本; (3) Jester是[23]引入的手势识别数据集。该数据集包含 27 个类别,包含 119k 训练视频和 15k 验证视频; (4) Something-Something V1&V2 [11] 是两个具有很强时间信息的人类行为数据集,分别包括用于训练和验证的 98k 和 194k 视频。
数据预处理。我们统一采样 8 帧来表示 Jester、MiniKinetics 上的每个视频,以及 ActivityNet 和 Something-Something 上的 12 帧以与现有作品进行比较,除非另有说明。在训练过程中,训练数据按照[37]被随机裁剪为 224×224,除了 Something-Something 之外,我们执行随机翻转。在推理阶段,所有帧都被中心裁剪为 224 × 224,并且我们为每个视频使用一次裁剪一个剪辑以提高效率。
实施细节。我们的方法默认建立在 ResNet50 [13] 上,我们用我们提出的 AF 模块替换网络的前三个阶段。我们首先在 ImageNet 上从头开始训练我们的双分支网络,以便与其他方法进行公平比较。然后我们添加了建议的导航模块,并在视频识别数据集上与主干网络一起对其进行训练。在我们的实现中,RT 表示选定帧的比率,而 RS 表示选定区域的比率,它将从 1 减少到我们在逐步训练之前设置的数量。在训练期间,我们让导航模块中的温度 τ 从 1 呈指数衰减到 0.01。由于篇幅有限,我们在补充材料中包含了更多实施细节。
4.1 Comparisons with Existing Methods
少即是多。首先,我们在具有 8 个采样帧的 Something-Something V1 和 Jester 数据集上实现 AFNet。我们将其与基线方法 TSN 进行比较,因为这两种方法都没有明确构建时间建模模块,而是构建在 ResNet50 上。
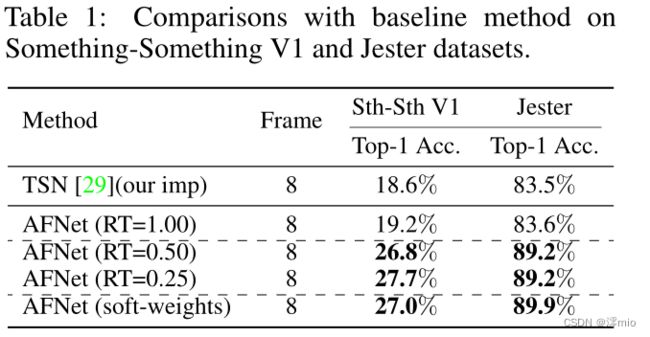
在表 1 中,我们的方法 AFNet(RT=1.00) 在选择所有帧时显示出与 TSN 相似的性能。尽管如此,当我们在 AFNet 中选择较少的帧时,它表现出比 TSN 和 AFNet (RT=1.00) 更高的精度,后者通过使用更少的帧但获得更高的精度来实现少即是多。结果可能看起来违反直觉,因为看到更多帧通常有利于视频识别。解释是 AFNet 的双分支设计可以保留所有输入帧的信息,并且在中间特征处选择显着帧实现了隐式时间建模,正如我们在 3.2 节中分析的那样。
由于导航模块学习的二进制掩码将决定是否为每个卷积块的每个帧计算系数,这将导致每个视频中的学习时间权重。为了更好地说明这一点,我们通过删除导航模块中的 Gumbel-Softmax [15] 并对其进行修改以学习焦点分支特征的软时间权重来进行实验。我们可以观察到 AFNet(soft-weights) 与 AFNet(RT=0.25)、AFNet(RT=0.50) 具有相似的性能,并且显着优于 AFNet(RT=1.00),这表明学习软帧权重会产生相似的效果.
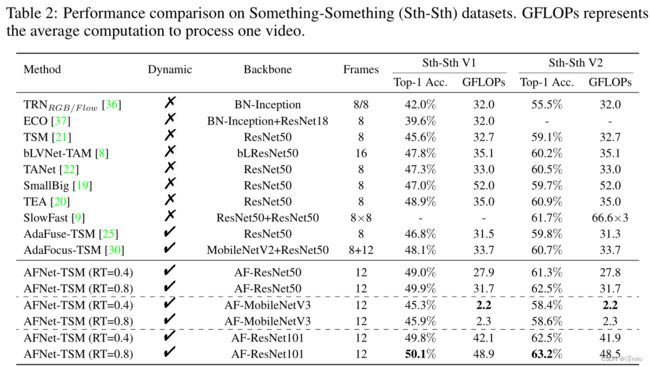
多即是少。我们将我们的方法与时间偏移模块 (TSM [21]) 相结合,以验证 AFNet 可以进一步减少此类竞争方法的冗余,并通过以更少的计算看到更多的帧来实现更多即更少。我们在包含强大时间信息的 Something-Something V1 和 V2 数据集上实施我们的方法,相关结果如表 2 所示。
与采样 8 帧的 TSM 相比,我们的方法在引入更多帧时显示出显着的性能优势,并且双分支结构可以保留所有帧的信息。然而,我们的计算成本比 TSM 小得多,因为我们通过这种双分支设计分配具有不同计算资源的帧,并使用建议的导航模块自适应地跳过不重要的帧。此外,AFNet 优于许多静态方法,这些方法在准确性和效率方面都精心设计了它们的结构以实现更好的时间建模。这可以解释为导航模块抑制了不重要帧的噪声并强制执行帧注意,这有利于时间建模。至于其他有竞争力的动态方法,如 AdaFuse 和 AdaFocus,我们的方法在准确性和计算方面都表现出明显更好的性能。当计算成本相似时,AFNet 在 Something-Something V1 上分别比 AdaFuse 和 AdaFocus 高出 3.1% 和 1.8%。此外,我们在其他主干上实施我们的方法以获得更高的准确性和效率。当我们在高效结构 MobileNetV3 上构建 AFNet 时,我们可以获得与 TSM 相似的性能,但仅需计算 2.3 GFLOPs。此外,以 ResNet101 为骨干的 AFNet-TSM(RT=0.8) 在 Something-Something V1 和 V2 上的准确率分别达到 50.1% 和 63.2%,进一步验证了我们框架的有效性和泛化能力。
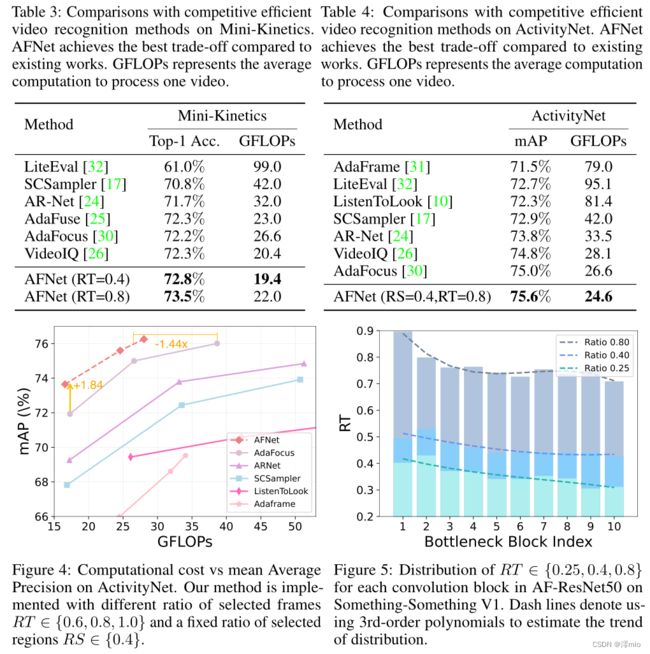
与竞争动态方法的比较。然后,我们在 MiniKinetics 和 ActivityNet 上实现我们的方法,并将 AFNet 与其他有效的视频识别方法进行比较。首先,我们在 Mini-Kinetics 上验证了我们的方法,与表 3 中的其他有效方法相比,AFNet 在准确性和计算方面均表现出最佳性能。为了证明 AFNet 可以进一步减少空间冗余,我们扩展了导航模块以选择显着区域ActivityNet 上的重要框架。我们将时间导航模块移动到网络的第一层,以避免在合并空间导航模块时出现巨大的特征差异,并注意我们仅在这部分应用此过程。我们可以从表 4 中看出,与其他工作相比,我们的方法获得了最佳性能,同时花费最少的计算量。此外,我们改变了所选帧的比率,并在图 4 中绘制了各种方法的平均精度和计算成本。我们可以得出结论,与其他工作相比,AFNet 在准确性和效率之间表现出更好的权衡。
4.2 Visualizations
我们在图 5 中显示了不同选择比率下不同卷积块之间的 RT 分布,并利用三阶多项式显示分布趋势(以虚线显示)。随着卷积块中索引的增加,可以看到所有曲线的 RT 都有下降趋势,这可以解释为较早的层主要捕获低级信息,这些信息在不同帧之间具有相对较大的差异。虽然不同帧之间的高级语义更相似,因此 AFNet 倾向于在后面的卷积块中跳过更多。在图 6 中,我们在 Something-Something V1 的验证集上以 RT =0.5 可视化了 AFNet 第三块中的选定帧,我们统一采样了 8 帧。我们的导航模块有效地引导焦点分支将注意力集中在与任务更相关的帧上,并停用包含相似信息的帧。
4.3 Ablation Study
在这一部分中,我们在具有 12 个采样帧的 ActivityNet 上实施我们的方法,以进行全面的消融研究,以验证我们设计的有效性。
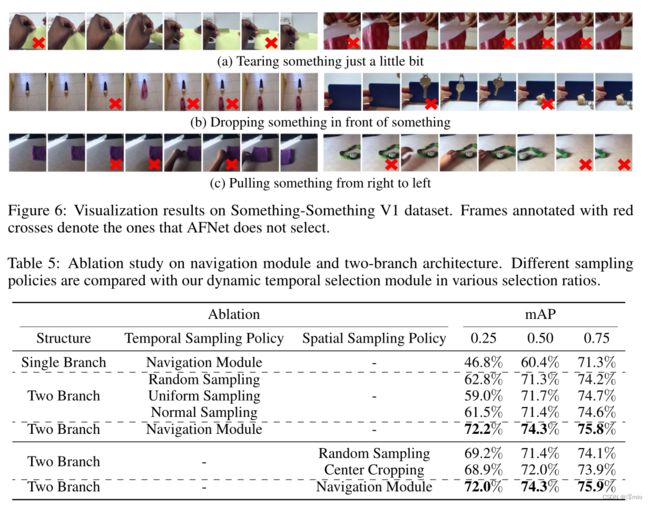
两个分支设计的效果。我们首先将我们的导航模块整合到 ResNet50 中,并将其与 AFNet 进行比较,以证明我们设计的双分支架构的实力。从表 5 可以看出,AFNet 在选择帧的不同比例下显示出显着的准确性优势。除此之外,采用我们的结构但具有固定采样策略的模型与基于单分支的网络相比也表现出明显更好的性能,这可以进一步证明我们的双分支结构的有效性以及保留所有帧信息的必要性.
导航模块的效果。在这一部分中,我们进一步将我们提出的导航模块与三种不同选择比率的可选采样策略进行比较:(1)随机采样; (2)均匀抽样:等步抽样框; (3) 正态采样:来自标准高斯分布的样本帧。如表 5 所示,我们提出的策略在不同的选择比率下不断优于其他固定采样策略,这验证了导航模块的有效性。
此外,当所选帧的比例较小时,我们的方法的优势更加明显,这表明我们选择的帧与任务相关性更高,并且包含识别的基本信息。此外,我们评估了可以减少空间冗余的导航模块的扩展,并将其与:(1)随机抽样进行比较; (2)中心裁剪。与固定采样策略相比,我们的方法在各种选择比率下表现出更好的性能,验证了该设计的有效性。
5 Conclusion
本文提出了一种自适应的 Ample and Focal Network (AFNet),以在考虑架构设计和数据固有冗余的情况下减少视频中的时间冗余。我们的方法使 2D-CNN 能够访问更多帧,从而通过专注于显着信息来更广泛地查看但计算量更少。 AFNet 表现出令人鼓舞的性能,因为我们的双分支设计保留了所有输入帧的信息,而不是在网络开始时丢弃部分知识。此外,网络内的动态时间选择不仅抑制了不重要帧的噪声,而且还强制执行隐式时间建模。与没有时间建模模块的静态方法相比,这使得 AFNet 在使用更少的帧时获得更高的精度。我们进一步表明,我们的方法可以扩展为通过仅计算所选帧的重要区域来减少空间冗余。综合实验表明,我们的方法在准确性和计算效率方面都优于竞争有效的方法。
Acknowledgments and Disclosure of Funding
研究由 DEVCOM 分析中心赞助,并根据合作协议编号 W911NF-22-2-0001 完成。本文件中包含的观点和结论是作者的观点和结论,不应被解释为代表陆军研究办公室或美国政府的官方政策,无论是明示的还是暗示的。尽管此处有任何版权标记,但美国政府有权出于政府目的复制和分发再版。
References
[1] Y . Bai, L. Wang, Z. Tao, S. Li, and Y . Fu. Correlative channel-aware fusion for multi-view time
series classification. In AAAI, 2021.
[2] F. Caba Heilbron, V . Escorcia, B. Ghanem, and J. Carlos Niebles. Activitynet: A large-scale
video benchmark for human activity understanding. In CVPR, 2015.
[3] J. Carreira and A. Zisserman. Quo vadis, action recognition? a new model and the kinetics
dataset. In CVPR, 2017.
[4] J. Chen, K. Li, Q. Deng, K. Li, and S. Y . Philip. Distributed deep learning model for intelligent
video surveillance systems with edge computing. IEEE Transactions on Industrial Informatics,
2019.
[5] R. T. Collins, A. J. Lipton, and T. Kanade. Introduction to the special section on video
surveillance. IEEE Transactions on pattern analysis and machine intelligence, 22(8):745–746,
2000.
[6] J. Davidson, B. Liebald, J. Liu, P . Nandy, T. V an Vleet, U. Gargi, S. Gupta, Y . He, M. Lambert,
B. Livingston, et al. The youtube video recommendation system. In ACM conference on
Recommender systems, 2010.
[7] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical
image database. In CVPR, 2009.
[8] Q. Fan, C.-F. Chen, H. Kuehne, M. Pistoia, and D. Cox. More is less: Learning efficient
video representations by big-little network and depthwise temporal aggregation. arXiv preprint
arXiv:1912.00869, 2019.
[9] C. Feichtenhofer, H. Fan, J. Malik, and K. He. Slowfast networks for video recognition. In
ICCV, 2019.
[10] R. Gao, T.-H. Oh, K. Grauman, and L. Torresani. Listen to look: Action recognition by
previewing audio. In CVPR, 2020.
[11] R. Goyal, S. Ebrahimi Kahou, V . Michalski, J. Materzynska, S. Westphal, H. Kim, V . Haenel,
I. Fruend, P . Yianilos, M. Mueller-Freitag, et al. The" something something" video database for
learning and evaluating visual common sense. In ICCV, 2017.
[12] Y . Han, G. Huang, S. Song, L. Yang, Y . Zhang, and H. Jiang. Spatially adaptive feature
refinement for efficient inference. IEEE Transactions on Image Processing, 30:9345–9358,
2021.
[13] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. In CVPR,
2016.
[14] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and
H. Adam. Mobilenets: Efficient convolutional neural networks for mobile vision applications.
arXiv preprint arXiv:1704.04861, 2017.
[15] E. Jang, S. Gu, and B. Poole. Categorical reparameterization with gumbel-softmax. arXiv
preprint arXiv:1611.01144, 2016.
[16] W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijayanarasimhan, F. Viola,
T. Green, T. Back, P . Natsev, et al. The kinetics human action video dataset. arXiv preprint
arXiv:1705.06950, 2017.
[17] B. Korbar, D. Tran, and L. Torresani. Scsampler: Sampling salient clips from video for efficient
action recognition. In ICCV, 2019.
[18] P . Li and J. Jin. Time3d: End-to-end joint monocular 3d object detection and tracking for
autonomous driving. In CVPR, 2022.
[19] X. Li, Y . Wang, Z. Zhou, and Y . Qiao. Smallbignet: Integrating core and contextual views for
video classification. In CVPR, 2020.
[20] Y . Li, B. Ji, X. Shi, J. Zhang, B. Kang, and L. Wang. Tea: Temporal excitation and aggregation
for action recognition. In CVPR, 2020.
[21] J. Lin, C. Gan, and S. Han. Tsm: Temporal shift module for efficient video understanding. In
ICCV, 2019.
[22] Z. Liu, L. Wang, W. Wu, C. Qian, and T. Lu. Tam: Temporal adaptive module for video
recognition. In CVPR, 2021.
[23] J. Materzynska, G. Berger, I. Bax, and R. Memisevic. The jester dataset: A large-scale video
dataset of human gestures. In ICCVW, 2019.
[24] Y . Meng, C.-C. Lin, R. Panda, P . Sattigeri, L. Karlinsky, A. Oliva, K. Saenko, and R. Feris.
Ar-net: Adaptive frame resolution for efficient action recognition. In ECCV, 2020.
[25] Y . Meng, R. Panda, C.-C. Lin, P . Sattigeri, L. Karlinsky, K. Saenko, A. Oliva, and R. Feris.
Adafuse: Adaptive temporal fusion network for efficient action recognition. arXiv preprint
arXiv:2102.05775, 2021.
[26] X. Sun, R. Panda, C.-F. R. Chen, A. Oliva, R. Feris, and K. Saenko. Dynamic network
quantization for efficient video inference. In ICCV, 2021.
[27] D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri. Learning spatiotemporal features
with 3d convolutional networks. In ICCV, 2015.
[28] L. Wang, Z. Tong, B. Ji, and G. Wu. Tdn: Temporal difference networks for efficient action
recognition. In CVPR, 2021.
[29] L. Wang, Y . Xiong, Z. Wang, Y . Qiao, D. Lin, X. Tang, and L. V an Gool. Temporal segment
networks: Towards good practices for deep action recognition. In ECCV, 2016.
[30] Y . Wang, Z. Chen, H. Jiang, S. Song, Y . Han, and G. Huang. Adaptive focus for efficient video
recognition. arXiv preprint arXiv:2105.03245, 2021.
[31] Z. Wu, H. Li, C. Xiong, Y .-G. Jiang, and L. S. Davis. A dynamic frame selection framework for
fast video recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020.
[32] Z. Wu, C. Xiong, Y .-G. Jiang, and L. S. Davis. Liteeval: A coarse-to-fine framework for
resource efficient video recognition. arXiv preprint arXiv:1912.01601, 2019.
[33] Y . Xu, L. Wang, Y . Wang, and Y . Fu. Adaptive trajectory prediction via transferable gnn. In
CVPR, 2022.
[34] L. Yang, Y . Han, X. Chen, S. Song, J. Dai, and G. Huang. Resolution adaptive networks for
efficient inference. In CVPR, 2020.
[35] S. Yeung, O. Russakovsky, G. Mori, and L. Fei-Fei. End-to-end learning of action detection
from frame glimpses in videos. In CVPR, 2016.
[36] B. Zhou, A. Andonian, A. Oliva, and A. Torralba. Temporal relational reasoning in videos. In
ECCV, 2018.
[37] M. Zolfaghari, K. Singh, and T. Brox. Eco: Efficient convolutional network for online video
understanding. In ECCV, 2018.
Appendix
A. 实验设置
ImageNet。我们首先使用 SGD 优化器在 ImageNet [7] 上训练我们的骨干网络。 L2 正则化系数和动量分别设置为 0.0001 和 0.9。我们在 2 个 NVIDIA Tesla V100 GPU 上以 256 的批量大小训练 90 个时期的网络,并采用 5 个时期的预热程序。初始学习率设置为 0.1,在第 30 和 60 轮时衰减 0.1。
迷你动力学(Mini-Kinetics)和 ActivityNet。然后我们添加导航模块并在视频数据集上与主干网络一起训练它。在 Mini-Kinetics [16] 和 ActivityNet [2] 上,我们使用动量为 0.9 的 SGD 优化器,L2 正则化系数设置为 0.0001。初始学习率设置为 0.002,它将在第 20 和第 40 轮衰减 0.1。模型在 2 个 NVIDIA Tesla V100 GPU 上训练了 50 个轮数,批量大小为 32。两个数据集的损耗因子 λ 设置为 1,温度 τ 从 1 呈指数下降到 0.01。
小丑和某物(Jester and Something-Something)。 Jester [23] 和 SomethingSomething [11] 数据集的训练细节与 ActivityNet [2] 相同,除了以下变化:初始学习率为 0.01,在 25 和 45 个 epoch 时衰减,总共训练 55 个 epoch;这些数据集上的损失因子 λ 设置为 0.5;训练数据将调整为 240×320,然后裁剪为 224×224,因为这两个数据集上的原始数据具有相对较小的分辨率。
B. Building AFNet on BasicBlock
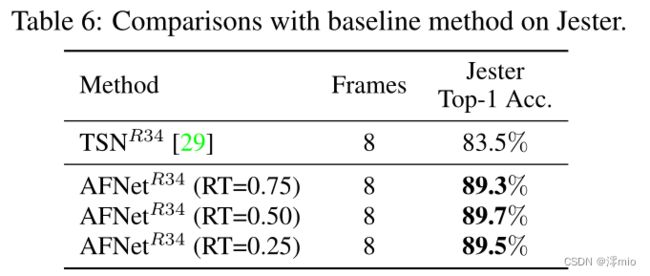
在之前的实验中,我们在由 Bottleneck 结构组成的 ResNet50 [13] 上构建 AFNet。相反,我们在这部分中使用 BasicBlock 在 Jester 数据集上构建 AFNet,并将其与基线方法 TSN [29] 进行比较。表 6 表明,我们的方法在不同的选择比率下不断显示出优于 TSN [29] 的显着优势,这也验证了我们的方法在 BasicBlock 结构上的有效性。有趣的是,当选择比率设置为 0.5 时,AFNet 获得最佳性能,而当选择更多帧时,它显示出相对最低的精度。这可以解释为我们的导航模块有效地抑制了无意义帧的噪声并实现了隐式时间建模,它使用更少的帧但获得更高的精度。
C. Building AFNet wtih More Frames

我们在本节中使用更多采样帧构建 AFNet,并将其与基线方法进行比较。结果如表 7 所示。当采样 16 帧时,TSN 与其他有效方法相比在性能上表现出明显优势,这可以用这些动态方法的预处理阶段(例如,帧选择、补丁裁剪)中的信息丢失来解释。这种现象促使我们设计 AFNet,它采用双分支结构来防止信息丢失。结果表明,与基线方法相比,AFNet 的计算成本显着降低,性能仅略有下降。此外,我们在 32 帧上进行实验,该现象与 16 帧类似。
D. More Ablation of AFNet

我们进一步在具有 12 个采样帧的 ActivityNet 上包含更多的 AFNet 消融。首先,我们在没有动态融合模块的情况下测试 AFNet 的性能,表 8 中的结果可以证明这种设计是重要的,因为它有效地平衡了来自两个分支的特征之间的权重。此外,我们探索了不同的温度衰减时间表,包括:1) 指数衰减,2) 余弦形状衰减,3) 线性衰减。结果表明,指数衰减实现了最佳性能,我们将其作为所有实验中的默认设置。
E. Limitations and Potential Negative Societal Impacts
首先,由于两个分支结构,AFNet 的主干需要在 ImageNet 上进行专门训练,而大多数其他方法直接利用来自在线资源的预训练 ResNet [13]。为了让其他人可以方便地使用 AFNet,我们在 ImageNet 上提供了预训练的主干,可以在我们提供的代码中访问它。其次,我们没有考虑在 AFNet 的设计过程中构建任何时间建模模块,这是其他静态方法的主要关注点,如 TEA [20]、TDN [28] 等。但是,我们已经证明 AFNet 实现了隐式时间建模并且它与现有的时间建模模块兼容,如 TSM [21]。据我们所知,我们的方法没有潜在的负面社会影响。