一、问题简述
本次作业的任务为多项式的求导。一个多项式为类似x**2+sin(x**2)**3这样的式子,第一次仅是只带有幂函数的、常数因子固定在每个乘积项的第一个因子位置的多项式求导;第二次则是增加了三角函数,给表达式带来了化简的难题,且对格式错误的输入要输出WRONG FORMAT!;而第三次又加入了括号,并使表达式可以进行嵌套,在第二次的基础上难度上升了一个档次。
第一次和第二次实际上不需要复杂的继承关系就可以完成,使用正则表达式等工具可以较为简单地实现,而第三次作业明显不同前两次的复杂程度,加入了嵌套关系,不能再像前两次作业那样使用简单的元组式数据结构来存储。这也意味着求导需要对因子的求导方法进行递归调用。
二、程序设计
-
输入的处理方法
对于第一次作业的输入,我采用了使用重量级正则表达式的方法,对整个乘积项进行匹配。这是因为第一次作业的输入形式极其简单:
表达式 → 空白项 [加减 空白项] 项 空白项 | 表达式 加减 空白项 项 空白项
项 → 变量项|常数项
变量项 → [带符号的整数 空白项 * 空白项] 幂函数
常数项 → 带符号的整数
幂函数 → x [空白项 指数]
指数 → ** 空白项 带符号的整数
带符号的整数 → [加减] 允许前导零的整数
允许前导零的整数 → (0|1|2|…|9){0|1|2|…|9}
空白项 → {空白字符}
空白字符 →
加减 + | -
可以看出,表达式是由几个简单的乘积项组合起来的,完全可以仅特判式中第一个乘积项的格式,其后的乘积项全部可以使用一个固定的正则表达式来读入。但是,这样的使用重量级正则表达式的方法却让我在第二次作业彻底进行了重构。
从第二次作业开始,输入的问题变得不再这么简单无脑。输入的表达式的幂函数和常数的位置不再固定,且加入了正余弦函数,使乘积项的读入变得难以继续完全使用正则表达式。因此,我转而采用状态机的做法,利用小的正则表达式将式中的各种项读入。
在第二次时,我就开始考虑第三次的做法了。第二次的函数仅支持
sin(x)和cos(x)两种,但我认为第三次肯定要将其改为支持所有表达式的嵌套。在此我进行了特判。我使用一个类Parser对表达式进行解析。对于式中的其他字符,我定义了一个函数private String expect(Pattern pattern),接受一个正则表达式,判断当前位置之后是不是直接邻接一个可以被pattern匹配的子串。如果是,则返回子串并标记下一位置,如果不是则返回null。而对于sin和cos的括号之内的表达式,我采用了直接按照括号的层数将内部的子表达式原封不动提取出来的方法,并新建一个Parser对象用来解析子表达式。在第三次,我发现自己预想的情况和实际的作业稍有差异:三角函数中的并不是表达式,而是因子。同时,作业中加入了“表达式因子”,即括号。这使得我不得不改变第二次的解析方式,增加一个用于解析函数中因子的方法。然而,我发现自己的状态机的代码已经过长,由于checkstyle有一个文件最多500行的限制,我只好另起炉灶,写了一个
ItemParser类专门用于解析函数内的因子项。 -
数据结构设计
在第二次作业,我就已经摒弃了第一次作业用到的元组结构,较有前瞻性地采用了树形的继承结构,使用一个类
Item作为所有因子项的基类,使用Function类继承Item,并作为所有函数项的基类。Item类中存储了项的幂次,对于常数项Constant类则用于表示常数的大小。对Item类,我设置了compareTo方法,用于在用TreeMap存储的时候能够方便地进行合并,因此没有对幂次进行比较;另设置了itemCompare方法,用于真正地对两个项的“大小”进行比较。Item类中还有一个函数derivative,用来求解导数,返回的是一个表达式对象。在表达式的结构上,我将表达式类命名为
Expression,设立乘积项Product类用来管理与合并项。在Product类中,我使用TreeMap对项进行管理,使用TreeMap而非TreeSet的原因是TreeSet不能直接通过索引进行查找,为此我将Item设计为“半不变类型”,之所以这么说,是因为我没有在创建之外的位置改变Item类型的对象,但是在一些位置,到了不得不更改的时候仍然可以修改,从而我可以直接对可以合并的项通过get方法进行查找,从而快速进行合并,而合并之后由于仅改变了幂次,对compareTo的结果没有影响,TreeMap不需要改变存储的元素位置。在Expression类中,我也使用TreeMap来对乘积项进行管理,并用到了类似的管理方式。由于引用容易产生浅拷贝这样的问题,这样的管理方式实际上非常具有风险,很容易出bug,我也险些因为这一点被送去C房间。但是若是使用得当,我相信不论是时间还是空间都能够降低复杂度。 -
对象创建模式
关于对象的创建,由于本次作业对象的耦合性较高,我并没有使用工厂模式来进行创建。在第一次作业之中,我甚至只有一种类用来管理所有的业务逻辑和数据。在第二次和第三次,我则是把对象创建的工作交给了专家类
Parser来在分析表达式的同时直接创建对象,在类的功能上并不是良好的风格。 -
化简方法分析
实际上,第二次作业就已经出现了严重的内卷,表达式的化简若不做到较为完美就会被扣除大量的性能分。化简的方法见仁见智,是谓八仙过海。我尝试了两种不同的做法,并将其结合了起来。
对于一个表达式
Expression记作e,我遍历TreeMap中的每一个乘积项Product,记作p,尝试以p的每一个正弦因子作为基础,对表达式进行检查。具体做法是,将p的正弦因子次数降2,再将p乘以具有相同内部表达式的2次余弦因子,得到一个新的Product记作q,并在e中查找有没有除常数外与q完全相同的项。如果有,则可以进行化简。称如此遍历-化简一次为一趟化简,我做多趟化简,直到发现某一趟并没有查找到可以化简的项,或是化简的次数达到了某个阈值(防止因算法不当而陷入死循环),则停止化简。试想
a*sin(x)**2+b*cos(x)**2这样的式子,我们实际上有三种可选方案进行化简:不化简、对正弦降次、对余弦降次。选择何种策略进行化简,是一个重要的问题。我尝试的第一种做法,是完全贪婪式的合并,我称其为Best Fit。对于查询到的因子,我寻找两个因子合并时最短的一种选项,并选择相应的化简方案。这种方案我本以为可以得到较为简短的结果,但我后来发现并非如此。我后来发现,这是因为有些时候表达式中的因子是含有某种秩序的,若是每次降次的对象不同,有时是正弦,有时是余弦,就会打乱这种秩序,使得下一趟化简无法进行。
我尝试的第二种做法,是简单化简策略,我称其为Fixed Fit,因为我每趟化简都是先仅对正弦进行降次,再仅对余弦进行降次,降次的对象是固定的。我本以为这样得不到最优的结果,但我后来才发现这是一种大智若愚的做法,原因就在于这样不会改变表达式的秩序。
实际上,三角函数的化简还涉及到更多的公式,比如
sin(x)**4-cos(x)**4=1-2*cos(x)**2,这里不赘述。通过对一些构造的样例进行分析,我发现多数时候第二种方法更优,但我并没有对第二种方法是否会导致表达式反而变长做进一步验证。相对地,第一种更优的情况少之又少,但确实有,而且第一种化简方法化简的表达式从数学上不可能比化简之前更长。因此,我选择了两种都试用,取更短者的策略。
对于第三次作业,化简除了三角函数的化简,还多了一个括号的化简。我采用的化简策略比较简单,首先是内部只含有一个乘积项的括号可以拆开,其次是在表达式化简的时候,尝试把所有的括号都拆开,若拆开后再经过一趟化简能够比原来的表达式更短,那么就使用化简后的形式,否则保持不变。这样的化简方式使得在递归求导时不会出现大量对括号的无意义求导,不仅使表达式变短,还加速了运行,避免了TLE的产生。
三、程序结构分析
如图所示,可以看出,第二次作业和第三次作业差距很小,只是增加了一个Bracket类用于表示括号,以及两个工具类;而第一次作业则与这两次有很大的差异,从表达式的构建到计算,全部都被包含在同一个类中,这样的高内聚结构是不应该出现的。
对于这几次作业的代码,我使用了DesigniteJava等工具进行了分析。
--Analysis summary--
Total LOC analyzed: 641 Number of packages: 1
Number of classes: 4 Number of methods: 73
-Total architecture smell instances detected-
Cyclic dependency: 0 God component: 0
Ambiguous interface: 0 Feature concentration: 0
Unstable dependency: 0 Scattered functionality: 0
Dense structure: 0
-Total design smell instances detected-
Imperative abstraction: 0 Multifaceted abstraction: 0
Unnecessary abstraction: 0 Unutilized abstraction: 4
Feature envy: 0 Deficient encapsulation: 1
Unexploited encapsulation: 0 Broken modularization: 0
Cyclically-dependent modularization: 0 Hub-like modularization: 0
Insufficient modularization: 2 Broken hierarchy: 0
Cyclic hierarchy: 0 Deep hierarchy: 0
Missing hierarchy: 0 Multipath hierarchy: 0
Rebellious hierarchy: 0 Wide hierarchy: 0
-Total implementation smell instances detected-
Abstract function call from constructor: 0 Complex conditional: 0
Complex method: 4 Empty catch clause: 0
Long identifier: 0 Long method: 0
Long parameter list: 0 Long statement: 0
Magic number: 0 Missing default: 0
--Analysis summary--
Total LOC analyzed: 1931 Number of packages: 1
Number of classes: 15 Number of methods: 166
-Total architecture smell instances detected-
Cyclic dependency: 0 God component: 0
Ambiguous interface: 0 Feature concentration: 1
Unstable dependency: 0 Scattered functionality: 0
Dense structure: 0
-Total design smell instances detected-
Imperative abstraction: 0 Multifaceted abstraction: 0
Unnecessary abstraction: 0 Unutilized abstraction: 12
Feature envy: 0 Deficient encapsulation: 10
Unexploited encapsulation: 0 Broken modularization: 0
Cyclically-dependent modularization: 0 Hub-like modularization: 0
Insufficient modularization: 2 Broken hierarchy: 0
Cyclic hierarchy: 0 Deep hierarchy: 0
Missing hierarchy: 0 Multipath hierarchy: 0
Rebellious hierarchy: 0 Wide hierarchy: 0
-Total implementation smell instances detected-
Abstract function call from constructor: 0 Complex conditional: 3
Complex method: 8 Empty catch clause: 0
Long identifier: 0 Long method: 0
Long parameter list: 4 Long statement: 0
对比第一次和第三次的分析结果,可以发现随着工程量的不断增加,代码中各种不当的结构的个数也在增加。第三次作业的代码中出现了3个复杂条件语句和8个复杂方法,这些是需要注意的,因为都会减少代码的可读性。

如图,通过第三次作业的类图,可以发现我的类之间耦合度非常高。这很大程度上是因为我没有使用工厂类进行对象的创建,而是选择了直接使用构造函数。
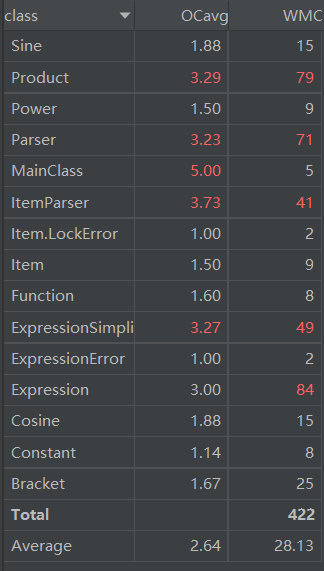
从代码复杂度等指标上看,可以发现我的设计的结构化程度有很大需要改进的地方,有一些方法呈现一种非正常的结构。对于类的方法的平均循环复杂度和总循环复杂度,尽管最后的运行时间并没有超标,我的实现也称不上优美,有很多地方值得改进。
四、Bug分析与发现
本次作业由于输入数据较为有规律,我使用了自动化测试的方法进行测试。Python有一个第三方库名叫xeger/'zi:gə/,这个库可以根据正则表达式生成相应的随机字符串。利用xeger库,我生成了随机的输入数据,用来测试程序中有没有bug。自动化测试在第三次作业中帮我找出了3个bug,虽然耗费时间,实际上非常划算。
我的程序的bug几乎全部出自化简部分,且多数属于浅拷贝问题。浅拷贝可以极大程度上节省程序运行的时间和空间开销,但也为程序的鲁棒性带来了很大的风险,我在这次作业中选择铤而走险来保证时间性能,使得我的程序绝对不会发生TLE的问题。我出现的另一种bug是在TreeMap中使用的compareTo方法编写失误,造成了项的错误合并。这些bug全都在强测开始之前被我找到并修复。我认为本次作业中我出的bug与设计结构的关系并不是很大,都出在一些细节的地方。
我在互测时,基本上采用随机生成数据的方式测试别人的bug,但由于三次都在A房间,随机生成的数据测试效果并不是很理想,我靠随机样例找到的bug很少。而我也手动构建了一些样例。这些样例大多数是用来测试是否产生化简的bug的。但是我发现很多人选择放弃复杂的化简来保证进入A房,而且我并没有仔细地阅读其他人的代码逻辑,因此针对性不是很高,在互测时检测到的bug并不多。
五、总结与心得