汇编语言——基础知识(1)
1、什么是汇编器和链接器?
汇编器(assembler)是一种工具程序,用于将汇编语言源程序转换为机器语言。链接器(linker)也是一种工具程序,它把汇编器生成的单个文件组合为一个可执行程序。还有一个相关的工具,称为调试器(debugger),使程序员可以在程序运行时,单步执行程序并检查寄存器和内存状态。
2、 MASM 能创建哪些类型的程序?
32 位保护模式(32-Bit Protected Mode):32 位保护模式程序运行于所有的 32 位和 64 位版本的 Microsoft Windows 系统。它们通常比实模式程序更容易编写和理解。从现在开始,将其简称为 32 位模式。
64 位模式(64-Bit Mode):64 位程序运行于所有的 64 位版本 Microsoft Windows 系统。
16 位实地址模式(16-Bit Real-Address Mode):16 位程序运行于 32 位版本 Windows 和嵌入式系统。 64 位 Windows 不支持这类程序。
3、 汇编语言可移植吗?
一种语言,如果它的源程序能够在各种各样的计算机系统中进行编译和运行,那么这种语言被称为是可移植的(portable)。
例如,一个 C++ 程序,除非需要特别引用某种操作系统的库函数,否则它就几乎可以在任何一台计算机上编译和运行。
Java 语言的一大特点就是,其编译好的程序几乎能在所有计算机系统中运行。
汇编语言不是可移植的,因为它是为特定处理器系列设计的。目前广泛使用的有多种不同的汇编语言,每一种都基于一个处理器系列。
C 和 C++ 语言具有一个独特的特性,能够在高级结构和底层细节之间进行平衡。直接访问硬件是可能的,但是完全不可移植。大多数 C 和 C++ 编译器都允许在其代码中嵌入汇编语句,以提供对硬件细节的访问。
4、解释和翻译
- 解释(Interpretation):运行 L1 程序时,它的每一条指令都由一个用 L0 语言编写的程序进行译码和执行。L1 程序可以立即开始运行,但是在执行之前,必须对每条指令进行译码。
- 翻译(Translation):由一个专门设计的 L0 程序将整个 L1 程序转换为 L0 程序。然后,得到的 L0 程序就可以直接在计算机硬件上执行。
注:计算机通常可以执行用其原生机器语言编写的程序。这种语言中的每一条指令都简单到可以用相对少量的电子电路来执行。为了简便,称这种语言为 L0。 由于 L0 极其详细,并且只由数字组成,因此,程序员用其编写程序就非常困难。如果能够构造一种较易使用的新语言 L1,那么就可以用 L1 编写程序。
5、机器
与实际机器和语言相对,用 Level 2 表示 VM2,Level 1 表示 VM1,如下图所示。计算机数字逻辑硬件表示为 Level 1 机器。其上是 Level 2,称为指令集架构(ISA, Instruction Set Architecture) 。通常,这是用户可以编程的第一个层次,尽管这种程序包含的是被称为机器语言的二进制数值。

指令集架构(Level 2)计算机芯片制造商在处理器内部设计一个指令集来实现基本操作,如传送、加法或乘法。这个指令集也被称为机器语言。每一个机器语言指令或者直接在机器硬件上执行,或者由嵌入到微处理器芯片的程序来执行,该程序被称为微程序。
汇编语言(Level 3)在 ISA 层,编程语言提供了一个翻译层,来实践大规模软件开发。汇编语言出现在 Level 3,使用短助记符,如 ADD、SUB 和 MOV,易于转换到 ISA 层。汇编语言程序在执行之前要全部翻译(汇编)为机器语言。
高级语言(Level 4)Level 4 是高级编程语言,如 C、C++ 和 Java。这些语言程序所包含的语句功能强大,并翻译为多条汇编语言指令。比如,查看 C++ 编译器生成的列表文件输出,就可以看到这样的翻译。汇编语言代码由编译器自动汇编为机器语言。
6、二进制整数
位自右向左,从 0 开始顺序增量编号。左边的位称为最高有效位(Most Significant Bit, MSB)右边的位称为最低有效位(LSB, least significant bit)。一个 16 位的二进制数,其 MSB 和 LSB 如下图所示:
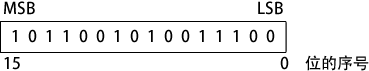
二进制整数可以是有符号的,也可以是无符号的。有符号整数又分为正数和负数,无符号整数默认为正数,零也被看作是正数。
两个二进制整数相加时,是位对位处理的,从最低的一对位(右边)开始,依序将每一对位进行加法运算。两个二进制数字相加,有四种结果,如下所示:
0 + 0 = 0 0 + 1 = 1
1 + 0 = 1 1 + 1 = 10
1 与 1 相加的结果是二进制的 10(等于十进制的 2)。多出来的数字向更高位产生一个进位
有些情况下,最高有效位会产生进位。这时,预留存储区的大小就显得很重要。比如,如果计算 1111 1111 加 0000 0001,就会在最高有效位之外产生一个 1,而和数的低 8 位则为全 0
如果和数的存储大小最少有 9 位,那么就可以将和数表示为 1 0000 0000。但是,如果和数只能保存 8 位,那么它就等于 0000 0000,也就是计算结果的低 8 位。
7、字节(byte)
在 x86 计算机中,所有数据存储的基本单位都是字节(byte),一个字节有 8 位。其他的存储单位还有字(word)(2 个字节),双字(doubleword)(4 个字节)和四字(quadword)(8 个字节)。
8、补码
有符号二进制整数有正数和负数。在 x86 处理器中,MSB 表示的是符号位:0 表示正数,1 表示负数。下图展示了 8 位的正数和负数:
补码表示:
负整数用补码(two`s-complement)表示时,使用的数学原理是:一个整数的补码是其加法逆元。(如果将一个数与其加法逆元相加,结果为 0。)
补码表示法对处理器设计者来说很有用,因为有了它就不需要用两套独立的电路来处理加法和减法。例如,如果表达式为 A-B,则处理器就可以很方便地将其转换为加法表达式:A+(-B)。 将一个二进制整数按位取反(求补)再加 1,就形成了它的补码。
十六进制数的补码
将一个十六进制整数按位取反并加 1,就生成了它的补码。一个简单的十六进制数字取反方法就是用 15 减去该数字。下面是一些十六进制数求补码的例子:
6A3D --> 95C2 + 1 --> 95C3
95C3 --> 6A3C + 1 --> 6A3D
最大值和最小值
n 位有符号整数只用 n-1 来表示该数的范围。下表列出了有符号单字节、字、双字、四字和八字的最大值与最小值。
类型 范围 存储位数 类型 范围 存储位数
有符号字节 -27 到 +27-1 8 有符号四字 -263 到 +263-1 64
有符号字 -215 到 +215-1 16 有符号八字 -2127 到 +2127-1 128
有符号双字 -231 到 +231-1 32
二进制减法
执行二进制减法的方法,即将被减去数的符号位取反,然后将两数相加。这个方法要求用一个额外的位来保存数的符号。
现在以(01101-00111)为例来试一下这个方法。
首先,将 00111 按位取反 11000 加 1,得到 11001。然后,把两个二进制数值相加,并忽略最高位的进位
9、字符在计算机中是如何表示的?
如果计算机只存储二进制数据,那么它如何表示字符呢?计算机使用的是字符集,将字符映射为整数。早期,字符集只用 8 位表示。即使是现在,在字符模式(如 MS-DOS)下运行时,IBM 兼容微机使用的还是 ASCII(读为“askey”)字符集。
ASCII 是美国标准信息交换码(AmeTican Standard Code for Information Interchange)的首字母缩写。在 ASCII 中,每个字符都被分配了一个独一无二的 7 位整数。
由于 ASCII 只用字节中的低 7 位,因此最高位在不同计算机上被用于创建其专有字符集。比如,IBM 兼容微机就用数值 128〜255 来表示图形符号和希腊字符。
ANSI 字符集
美国国家标准协会(ANSI)定义了 8 位字符集来表示多达 256 个字符。前 128 个字符对应标准美国键盘上的字母和符号。后 128 个字符表示特殊字符,诸如国际字母表、重音符号、货币符号和分数。
Microsoft Windows 早期版本使用 ANSI 字符集。
Unicode 标准
当前,计算机必须能表示计算机软件中世界上各种各样的语言。因此,Unicode 被创建出来,用于提供一种定义文字和符号的通用方法。
Unicode 定义了数字代码(称为代码点(code point)),定义的对象为文字、符号以及所有主要语言中使用的标点符号,包括欧洲字母文字、中东的从右到左书写的文字和很多亚洲文字。代码点转换为可显示字符的格式有三种:
UTF-8 用于 HTML,与 ASCII 有相同的字节数值。
UTF-16 用于节约使用内存与高效访问字符相互平衡的环境中。比如,Microsoft Windows 近期版本使用了 UTF-16,其中的每个字符都有一个 16 位的编码。
UTF-32 用于不考虑空间,但需要固定宽度字符的环境中。每个字符都有一个 32 位的编码。
ASCII 字符串
有一个或多个字符的序列被称为字符串(string)。更具体地说,一个 ASCII 字符串是保存在内存中的,包含了 ASCII 代码的连续字节。比如,字符串“ABC123”的数字代码是 41h、42h、43h、31h、32h 和 33h。
以空字节结束(null-terminated)的字符串是指,在字符串的结尾处有一个为 0 的字节。C 和 C++ 语言使用的是以空字节结束的字符串,一些 Windows 操作系统函数也要求字符串使用这种格式。
使用 ASCII 表

在查找字符的十六进制 ASCII 码时,先沿着表格最上面一行,再找到包含要转换字符的列即可。表格第二行是该十六进制数值的最高位;左起第二列是最低位。
例如,要查找字母 a 的 ASCII 码,先找到包含该字母的列,在这一列第二行中找到第一个十六进制数字 6。然后,找到包含 a 的行的左起第二列,其数字为 1。因此,a 的 ASCII 码是十六进制数 61