python爬取前程无忧当日的全部招聘信息
用了几天时间写成的爬取前程无忧的当日的招聘信息,通过多线程的方式同时爬取多个城市的信息,作为资料保存下来,一下是完整代码,可以直接复制粘贴爬取
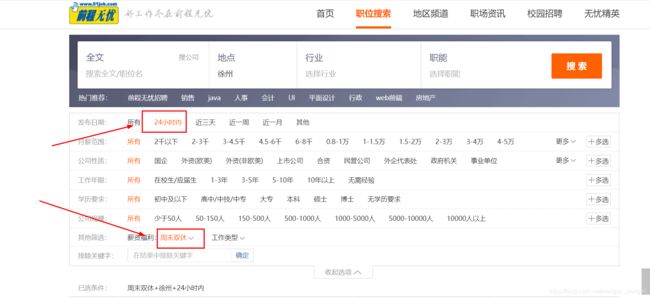
这里爬取的数据条件是是24小时内,周末双休的,会在当前文件下创建一个文件夹,并且在当前的文件夹下创建文件,如果昨天已经爬取过了,今天会将昨日的信息全部删除重新下载
import urllib.request
import urllib.parse
from bs4 import BeautifulSoup
import re
import os
import time
import datetime
from threading import Thread
def city_request(city, i, headers):
if city == '徐州':
arguments = '071100'
elif city == '广州':
arguments = '030200'
elif city == '北京':
arguments = '010000'
elif city == '上海':
arguments = '020000'
elif city == '杭州':
arguments = '080200'
url = "https://search.51job.com/list/" + arguments + ",000000,0000,00,0,99,%2B,2," + str(i) + '.html?welfare=04'
request_head = urllib.request.Request(url=url, headers=headers)
return request_head
def txt(list, file_name):
'''将获取的内容写入到TXT文件中'''
for i in list:
b = str(i)
b += '\n'
with open(file_name, 'a') as f:
f.write(b)
def analyze_data(data, now_time, city, i_step):
'''分析HTML源代码,获取自己要的部分'''
soup = BeautifulSoup(data, 'lxml')
data_list1 = soup.select('.el')
new_list = []
each_page_list = []
#获取网页总数,网页一共有多少页
data_tt = soup.select('.td')[0].get_text()
b = re.search(r'\d+', data_tt).group()
frequency = int(b)
#获取爬取的是第几页当前在第几页
# data_rr = soup.select('.p_in > ul > .on')[0].get_text()
# tt = int(data_rr)
#筛选出真正需要的内容
for x in data_list1:
data_list3 = x.select('.t5')
if data_list3 != []:
new_list.append(x)
#列表中第一个不是想要的内容,所以从下标为1的地方开始遍历
for i in range(1, len(new_list)):
content_list = new_list[i].select('.t5')
content = content_list[0].get_text()
if content == now_time:
data_list = new_list[i].select('.t1 > span > a')
a_content = data_list[0].get_text()
# 内容里有\r\n和空格,将无用的去除
b = re.findall(r'[^\r\n ]+', a_content)
string = ''
for t in b:
if string == "":
string += t
else:
string = string + '-' + t
a_url = data_list[0]["href"]
position_list = {}
position_list['职位:'] = string
position_list['地址:'] = a_url
each_page_list.append(position_list)
return each_page_list, frequency
def get_data(url):
"""向网站发起请求获取网页源代码"""
#伪装请求头部信息
response = urllib.request.urlopen(url)
html = response.read().decode('gbk')
return html
def thread_fun(city, headers, now_time):
'''多线程调用,这个函数是为了方便多线程爬取,而封装的方法'''
i = 1
while True:
# 伪装请求头部信息
request_head = city_request(city, i, headers)
file_name = '.\\当日职位大全\\' + city + '当日全部职位.txt'
print('城市:%s 开始爬取第%d页>>>>>' % (city, i))
# 向网站发起请求获取网页源代码
data = get_data(request_head)
# 分析数据
each_page_list, result = analyze_data(data, now_time, city, i)
# 写入TXT文件中
txt(each_page_list, file_name)
print('城市: %s 第%d页爬取结束……' % (city, i))
time.sleep(2)
if i >= result:
print('================================================================>>>>%s 信息已经全部爬取完成' % city)
break
i += 1
def del_file(path):
'''---判断当前同级目录下是否有‘当日职位大全’文件夹,没有就创建,---判断文件夹下是否有文件,有就全部删除'''
# 创建文件夹
path_dir = os.path.exists('当日职位大全')
if not path_dir:
os.mkdir('当日职位大全')
ls = os.listdir(path)
for i in ls:
c_path = os.path.join(path, i)
if os.path.isdir(c_path):
del_file(c_path)
else:
os.remove(c_path)
def main():
#判断当前同级目录下是否有‘当日职位大全’文件夹,没有就创建,判断文件夹下是否有文件,有就全部删除
CUR_PATH = r'.\\当日职位大全'
del_file(CUR_PATH)
# 要爬取的城市名称
# city_list = ['徐州']
city_list = ['北京', '上海', '广州', '徐州', '杭州']
#创建今日时间,月-日格式……如 02-23
now = datetime.datetime.now()
now_time = now.strftime('%m-%d')
#伪装头部信息
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'max-age=0',
'Connection': 'keep-alive',
'Cookie': 'guid=4b6f68576c5403002deafe70d8c84712; nsearch=jobarea%3D%26%7C%26ord_field%3D%26%7C%26recentSearch0%3D%26%7C%26recentSearch1%3D%26%7C%26recentSearch2%3D%26%7C%26recentSearch3%3D%26%7C%26recentSearch4%3D%26%7C%26collapse_expansion%3D; __guid=115568644.2223351635055879000.1579524085775.8896; adv=adsnew%3D1%26%7C%26adsnum%3D3213442%26%7C%26adsresume%3D1%26%7C%26adsfrom%3Dhttps%253A%252F%252Fwww.so.com%252Fs%253Fq%253D%2525E6%25258B%25259B%2525E8%252581%252598%2526src%253Dsrp%2526fr%253Dhao_360so_suggest_b%2526psid%253D4ee5e10e10d9dcb2544d04c27cea42a0; slife=lowbrowser%3Dnot%26%7C%26; partner=www_so_com; 51job=cenglish%3D0%26%7C%26; search=jobarea%7E%60010000%7C%21ord_field%7E%600%7C%21recentSearch0%7E%60010000%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FA%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21recentSearch1%7E%60071100%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FA%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21recentSearch2%7E%60071100%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA0%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FA%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21recentSearch3%7E%60071100%A1%FB%A1%FA000000%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA0%A1%FB%A1%FA%B9%E3%B8%E6%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21recentSearch4%7E%60010000%A1%FB%A1%FA010500%A1%FB%A1%FA0000%A1%FB%A1%FA00%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA99%A1%FB%A1%FA9%A1%FB%A1%FA99%A1%FB%A1%FA%A1%FB%A1%FA28%A1%FB%A1%FA%B9%E3%B8%E6%A1%FB%A1%FA2%A1%FB%A1%FA1%7C%21collapse_expansion%7E%601%7C%21; monitor_count=16',
'Host': 'search.51job.com',
'Upgrade-Insecure-Requests': 1,
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
#多线程的方式同时爬取数据
for city in city_list:
#多线程的方式爬取数据
t = Thread(target=thread_fun, args=(city, headers, now_time))
t.start()
if __name__ == '__main__':
main()