《A Deep Generative Framework for Paraphrase Generation》论文笔记--方法
概述
Our framework uses a variational autoencoder (VAE) as a generative model for paraphrase generation. In contrast to the standard VAE, however, we additionally condition the encoder and decoder modules of the VAE on the original sentence. This enables us to generate paraphrase(s) specific to an input sentence at test time.
使用VAE作为复述句的生成模型,并在原始句子上对VAE的encoder和decoder模型进行训练。
一、VAE
1. VAE中的encoder
(参考资料:https://zhuanlan.zhihu.com/p/42870213、https://www.cnblogs.com/xueqiuqiu/articles/7602231.html、https://www.cntofu.com/book/85/dl/gan/vae.md)
(1)概述:
The VAE (Kingma and Welling 2014; Rezende, Mohamed, andWierstra2014)is a deep generative latent variable model that allows learning rich, nonlinear representations for highdimensional inputs.
VAE:基于变分思想的深度学习生成模型,可以学习高维输入的非线性表示。
(2)实现方式:

VAE实现的方式是:学习输入x的隐编码z(z可以很好的实现对x的重构)。
(3)理论知识:

标准的自动编码是通过确定函数来学习隐编码z的;但VAE编码则是通过后验分布实现的。
在实现过程中,一般将后验分布假定伟高斯分布,同时涉及到的参数既是输入x的非线性变换,也是将x作为输入的前馈神经网络的输出。
此外,VAE也希望后验分布与前验相近,即可视为标准正态分布。
2. VAE中的decoder

decoder也是一种分布:以隐编码z为输入,以x作为输出。分布中涉及到的参数与VAE中encoder类似,是另一种前馈神经网络的输出。
3. VAE中encoder和decoder的参数:
The parameters defining the VAE are learned by maximizing the following objective:
通过目标函数最大化来学习VAE的参数:


其中,KL表示KL散度(相对熵,用来度量两个函数的相似程度或者相近程度。当两个随机分布相同时,它们的相对熵为零;当两个随机分布的差别增大时,它们的相对熵也会增大)。
4. VAE中的z:
Endowing the latent code z with a distribution “prepares” the VAE decoder for producing realistic looking inputs even when z is a random latent code not representing the encoding of any of the previously seen inputs. This makes VAE very attractive for generative models for complex data, such as images and text data such as sentences.
当VAE解码中的z满足分布时,即使z是一个随机的隐编码(不能代表输入内容的encoding),也能应用于VAE的解码器得到与输入相近的结果。这使得VAE适用于复杂数据(例如图像和文本数据)的生成模型。
5. 本文应用VAE的方式:
Our work is in a similar vein but the key difference lies in the design of a novel VAE-LSTM architecture, specifically customized for the paraphrase generation task, where the training examples are given in form of pairs of sentences (original sentence and its paraphrased version), and both encoder and decoder of the VAE-LSTM are conditioned on the original sentence. We describe our VAE-LSTM architecture in more detail in the next section.
本文结构设计:VAE-LSTM
训练数据:句子对(原始句+复述句)
VAE-LSTM的编码器和解码器均以原始句子为条件。
二、模型架构(作者提出)
1. 数据介绍

数据集:N组训练数据,每一组包含一个原始句子和一个复述句子。![]() 、
、![]() 分别表示第n组数据中原始句和复述句的单词集,在下文中简化为:
分别表示第n组数据中原始句和复述句的单词集,在下文中简化为:![]() 、
、![]() 。此外,
。此外,![]() 、
、![]() 为原始句和复述句的向量表示,通过LSTM网络学习,其参数将与模型的其余部分一起以端到端的方式学习。
为原始句和复述句的向量表示,通过LSTM网络学习,其参数将与模型的其余部分一起以端到端的方式学习。
2. 模型架构--大体
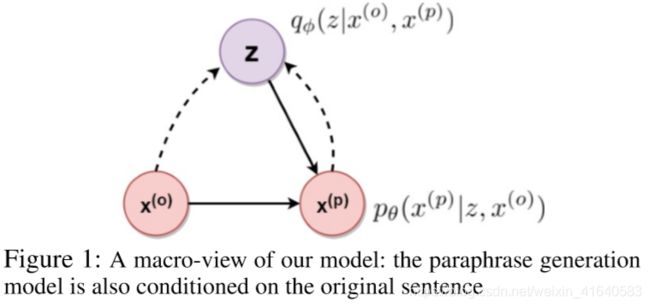
去掉LSTM后,本文的宏观模型如图1所示。

本文的宏观模型本质上是:用来生成复述向量![]() (由隐编码z和原始句
(由隐编码z和原始句![]() 生成)的一个基于VAE的生成模型。
生成)的一个基于VAE的生成模型。
与标准VAE相比,本文的编码和解码过程都以原始句![]() 为条件。
为条件。
(如图1:实线部分为decoder过程,![]() 表示以隐编码z和原始句
表示以隐编码z和原始句![]() 为条件生成
为条件生成![]() ;虚线部分为encoder过程,
;虚线部分为encoder过程,![]() 表示以复述句
表示以复述句![]() 和原始句
和原始句![]() 为条件生成隐编码z)
为条件生成隐编码z)
3. 模型架构--细节
A detailed zoomed-in view of our model architecture is shown in Fig. 2, where we show all the components, including the LSTM encoders and decoders. In particular, our model consists of three LSTM encoders and one LSTM decoder (thus a total of four LSTMs), which are employed by our VAE based architecture as follows:
由三个LSTM编码器和一个LSTM解码器(总共四个LSTM)组成,如图2所示:

(1)VAE Input (Encoder) 部分:

如图2所示,VAE输入部分用了2个LSTM。
第一个LSTM,将原始句![]() 转换成向量形式
转换成向量形式![]() ;
;
第二个LSTM,输入为![]() 和复述句
和复述句![]() ,输出为经过一个前馈神经网络得到的
,输出为经过一个前馈神经网络得到的![]() 。
。
进而得到均值和方差。
(2)VAE Output (Decoder)部分:

如图2所示,VAE Output部分的输入内容:隐编码z、原始句的向量表示![]() (由第三个LSTM生成);输出:复述句
(由第三个LSTM生成);输出:复述句![]() 。
。
![]() :应用于decoder的第一阶段,用来初始化LSTM decoder(第四个LSTM);
:应用于decoder的第一阶段,用来初始化LSTM decoder(第四个LSTM);
z :(z与第三个LSTM生成的![]() 串联后)应用于LSTM decoder(第四个LSTM)的各个阶段。
串联后)应用于LSTM decoder(第四个LSTM)的各个阶段。
(3)计算:
目标函数:

(与标准VAE类似)

最大化公式2,以平衡复述向量![]() 的重构期望,同时确保 z 的后验与前验接近。之后,按照(Bowman et al.2015,https://www.aclweb.org/anthology/K16-1002.pdf)中采用的相同训练过程训练模型。
的重构期望,同时确保 z 的后验与前验接近。之后,按照(Bowman et al.2015,https://www.aclweb.org/anthology/K16-1002.pdf)中采用的相同训练过程训练模型。