数据分析实战之用户消费行为分析
数据分析的流程大致如下

一、分析目的
本次主要根据淘宝用户的行为数据,分析挖掘有价值的信息,通过数据清洗、数据分析、数据可视化、最后结合使用相关算法模型挖掘数据价值,从而为营销提供相应的数据支撑
二、数据来源
本次使用的数据来源于阿里天池:https://tianchi.aliyun.com/dataset/dataDetail?dataId=46&userId=1
数据说明如下:
| 字段 | 字段描述 |
| user_id | 用户ID |
| item_id | 商品ID |
| behavior_type | 行为类型 |
| user_geohash | 用户地理位置 |
| item_category | 商品类目 |
| time | 行为发生的具体时间 |
三、数据清洗
1、导入相关的第三方模块
import numpy as np
import pandas as pd
import matplotlib as mpl
from matplotlib import pyplot as plt
import seaborn as sns
import warnings
# 有时候运行代码时会有很多warning输出,像提醒新版本之类的,如果不想这些乱糟糟的输出,可以使用如下代码
warnings.filterwarnings('ignore')
# 用来显示中文标签
mpl.rcParams["font.family"] = "SimHei"
# 用来显示负号
mpl.rcParams["axes.unicode_minus"] = False2、读入数据并查看
# 写入数据
df = pd.read_csv(r"C:\Users\shanyonggang\Desktop\培训材料\tianchi_data\tianchi_mobile_recommend_train_user.csv",sep=',')分别查看数据的数量、数据的总体预览
# 显示前五行
df.head()
# 数据数量
df.shape
# 总体预览
df.info()结果如下:

可以看到用户地理位置数据缺失比较严重,同时用户行为采集时间点数据有一条缺失,其数据类型后续需要转换成时间格式进行分析。
3、缺失值处理
主要是为了处理原始数据中的缺失值,对于缺失值较多的,可以直接删除其特征,缺失比较小的,可以用其他数据进行替代(如:平均值、中位数、前后值填充等,具体根据实际情况)
# 查看空值(发现其中位置信息缺失比较严重,此处将该列删除,同时时间列有一行为空)
df.isnull().sum()
# 检索时间列为空的行
df[df["time"].isnull().values==True]
# 删除地理位置列(两种方式),主要是因为其缺省较多
# data.drop("user_geohash",axis=1)
data = df.drop(columns=["user_geohash"])
# 删除行中有空值的
data = data.dropna(axis=0,how='any')最终处理后的数据如下:
4、增加额外特征
此处主要是针对时间项,首先需要将时间由字符串形式转换成时间格式,另外增加日期、小时、年、月、星期等特征,具体操作如下:
# 将时间按照日期和时间点分开
data["date"] = data.time.apply(lambda x:x.split(" ")[0])
# 获取用户行为采集的时间点
data["hour"] = data.time.str[-2:]
# 日期转出时间格式
data["date"] = pd.to_datetime(data["date"])
# 时间戳转出时间格式
data["time"] = pd.to_datetime(data["time"])
# 小时转出整型格式
data["hour"] = data["hour"].astype(int)
# 获取年、月、周几(其中周一为1)
data["year"] = data.time.apply(lambda x:x.year)
data["month"] = data.time.apply(lambda x:x.month)
data["weekday"] = data.time.apply(lambda x:x.weekday()+1)
最终结果如下:
接下来我们按照时间进行排序,并重新设置索引
# 按照时间升序排序
data = data.sort_values(by="time",ascending=True)
# 删除原始索引,生成新的索引
data.reset_index(drop=True,inplace=True)最终结果如下:
四、数据分析
上面我们对数据进行了清洗,接下来我们针对清洗好的数据进行分析,首先对下面可能用的名词进行相应的解释
1、名词解释
| PV(Page View) | 页面的浏览量或点击率,其中点击或刷新一次总量增加一次 |
| UV(Unique Visitor) | 独立访客数,1天内访问某站点的用户数 |
| ARPU(average revenue per user ) | 总收入/用户数;是指在一段时间内从每位用户获得收入 |
| ARPPU(average revenue per paying user) | 指从每位付费用户身上获得的收入 |
| RFM(Recency Frequency Monetary) | 最近购买时间、某个时间段的购买次数、某个时间段的消费金额 |
2、不同时间的PV、UV流量统计
2.1、统计这个时间段内的PV、UV流量
# 总体维度下
total_pv = data["user_id"].count()
print("这个时间段内网页的总访量为:{}".format(total_pv))
total_uv = data["user_id"].nunique()
print("这个时间段内独立访客数量为:{}".format(total_uv))2.2、每天PV、UV的变化统计,如下:
# 日期维度下(发现双十二适合访问量突然增加)
# 每日总访问量统计
date_pv = data.groupby("date")["user_id"].count()
# print(date_pv)
# 每日独立访客数量统计
date_uv = data.groupby("date")["user_id"].apply(lambda x:x.nunique())
# print(date_uv)
plt.figure(figsize=(16,10))
plt.subplot(2,1,1)
plt.plot(date_pv,c="r")
plt.title("每天页面的总访问量(PV)")
plt.grid(color='y', linestyle='--', linewidth=0.5)
plt.subplot(2,1,2)
plt.plot(date_pv,c="g")
plt.title("每天的独立访客数量(UV)")
plt.tight_layout()
plt.grid(color='r', linestyle='--', linewidth=0.5)
plt.show()结果如下:
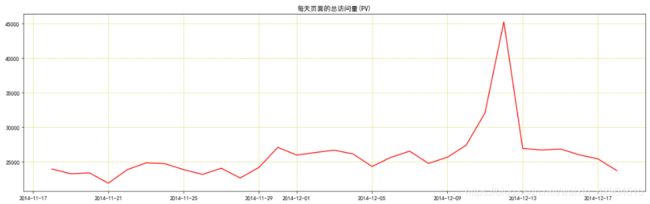
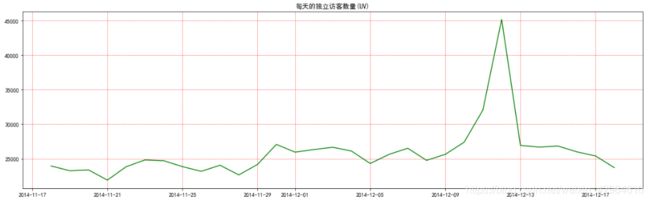
可以看出在双十二期间网站访问量激增,不用说我们也知道是因为双十二淘宝促销活动导致访客增加
2.3、分析一天内PV、UV的变化情况
# 时间维度下的统计情况(主要看访问时间的情况)
# 每日总访问量统计
hour_pv = data.groupby("hour")["user_id"].count()
print(hour_pv.head())
# 每日独立访客数量统计
hour_uv = data.groupby("hour")["user_id"].apply(lambda x:x.nunique())
print(hour_uv.head())
pv_uv_hour = pd.concat([hour_pv,hour_uv],axis=1)
pv_uv_hour.columns = ["hour_pv","hour_uv"]
print(pv_uv_hour.head())
plt.figure(figsize=(10,6))
pv_uv_hour["hour_pv"].plot(c="r",label="每个小时的页面总访问量")
plt.ylabel("页面访问量")
pv_uv_hour["hour_uv"].plot(c="g",label="每个小时的页面总访问量",secondary_y=True)
plt.ylabel("页面独立访客数")
plt.xticks(range(0,24),pv_uv_hour.index)
plt.legend(loc="best")
plt.grid(color='r', linestyle='--', linewidth=0.5)
plt.tight_layout()
plt.show()结果如下:
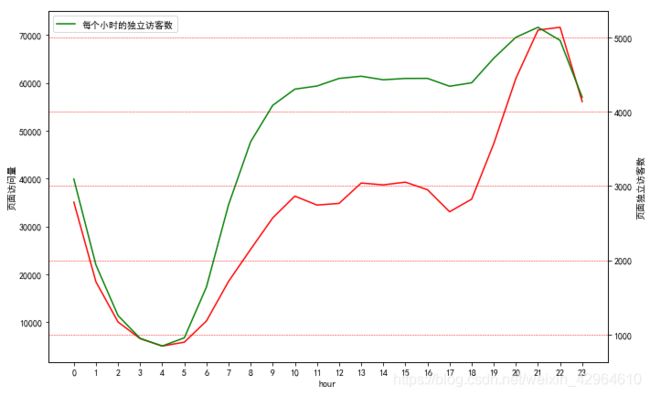
可以看出,早上五点之后,访问量不断增加,晚上6点之后访问量增加,晚上八点到十点是访问高峰期,符合人们日常的作息规律
2.4、按照星期分析PV、UV数据
下面的代码中使用了pyechart绘制图形变化,代码如下:
# 按星期统计访问量
# 星期总访问量统计
weekday_pv = data.groupby("weekday")["user_id"].count()
# 星期独立访客数量统计
weekday_uv = data.groupby("weekday")["user_id"].apply(lambda x:x.nunique())
pv_uv_weekday = pd.concat([weekday_pv,weekday_uv],axis=1)
pv_uv_weekday.columns = ["weekday_pv","weekday_uv"]
week_name_list = ["周一", "周二", "周三", "周四", "周五", "周六", "周日"]
# from pyecharts.charts import Line
# from pyecharts import options as opts
line = (
Line(init_opts=opts.InitOpts(width="1000px", height="500px"))
.add_xaxis(xaxis_data=week_name_list)
.add_yaxis(
series_name="按星期展示的总访问人数",
y_axis=pv_uv_weekday["weekday_pv"],
markpoint_opts=opts.MarkPointOpts(
data=[
opts.MarkPointItem(type_="max", name="最大值"),
opts.MarkPointItem(type_="min", name="最小值"),
]
),
markline_opts=opts.MarkLineOpts(
data=[opts.MarkLineItem(type_="average", name="平均值")]
),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="按星期统计用户访问量", subtitle="访问人数"),
tooltip_opts=opts.TooltipOpts(trigger="axis"),
# toolbox_opts=opts.ToolboxOpts(is_show=True),
xaxis_opts=opts.AxisOpts(type_="category", boundary_gap=False),
)
)
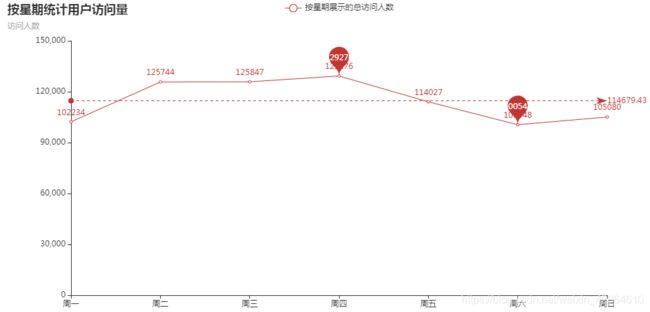
line.render_notebook()结果如下:
绘制相关的饼图如下:
from pyecharts.charts import Pie
from pyecharts.charts import Line
pie = (
Pie()
.add(
" ",[list(z) for z in zip(week_name_list,pv_uv_weekday["weekday_pv"])],
radius=["30%", "75%"],
rosetype="radius"
)
.set_global_opts(
title_opts=opts.TitleOpts(title="按星期统计的独立访客饼状分布图"),
legend_opts=opts.LegendOpts(pos_left="5%",pos_bottom='1%'),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
pie.render_notebook() 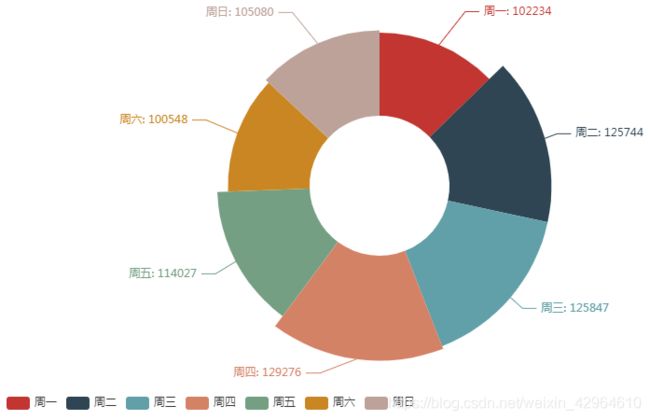
可以看出,一周内,周一开始访问量不断增加,从周四开始访问量逐渐下降,周六、周日逐渐到最低点,初步分析可能会是因为周末用户出游或者去做自己的一些别的事情,访问淘宝的时间减少。
3、用户行为分析
主要分析用户点击、收藏、加购、下单等行为,首先分析各个行为的用户数量,如下:
# 用户行为分析
user_type_1 = data[data["behavior_type"]==1]["user_id"].count()
user_type_2 = data[data["behavior_type"]==2]["user_id"].count()
user_type_3 = data[data["behavior_type"]==3]["user_id"].count()
user_type_4 = data[data["behavior_type"]==4]["user_id"].count()
print("点击用户:",user_type_1)
print("收藏用户:",user_type_2)
print("加购用户:",user_type_3)
print("下单用户:",user_type_4)结果如下:

3.1、日期维度下用户行为分析
此处用到了pandas中的透视表功能,也可以使用groupby功能,如下:
# 日期维度下的用户行为分析
pv_date_type = pd.pivot_table(data,index="date",columns="behavior_type",values="user_id",aggfunc=np.size,fill_value=0)
pv_date_type.columns=["点击","收藏","加入购物车","支付"]
pv_date_type.head()结果如下:
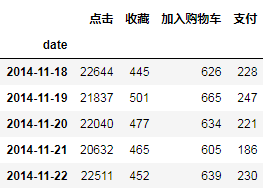
绘制变化曲线图,如下:
# 绘制变化图表
plt.figure(figsize=(8,5))
sns.lineplot(data=pv_date_type[["收藏","加入购物车","支付"]])
plt.tight_layout()
plt.xticks(rotation=30)
plt.savefig("不同日期不同用户行为的PV变化趋势",dpi=300)
plt.show()如下:
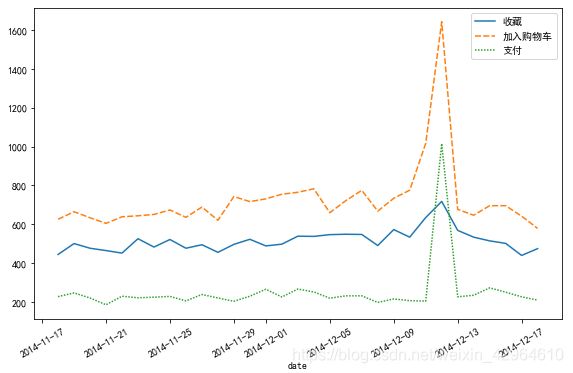
不同行为每天的PV变化趋势一致,其中12-12当天的付款人数高于收藏人数,表名双十二活动促销效果好
3.1、时间维度下用户行为分析
# 时间维度下的用户行为分析
pv_hour_type = pd.pivot_table(data,index='hour',
columns='behavior_type',
values='user_id',
aggfunc=np.size)
pv_hour_type.columns = ["点击","收藏","加入购物车","支付"]
pv_hour_type.head()
# 绘制变化图表
plt.figure(figsize=(10,5))
sns.lineplot(data=pv_hour_type[["收藏","加入购物车","支付"]])
plt.legend(loc="best")
pv_hour_type["点击"].plot(c="yellow",linewidth=5,label="点击",secondary_y=True)
plt.legend(loc="lower right")
plt.tight_layout()
plt.savefig("不同小时不同用户行为的PV变化趋势",dpi=300)
plt.show()结果如下:
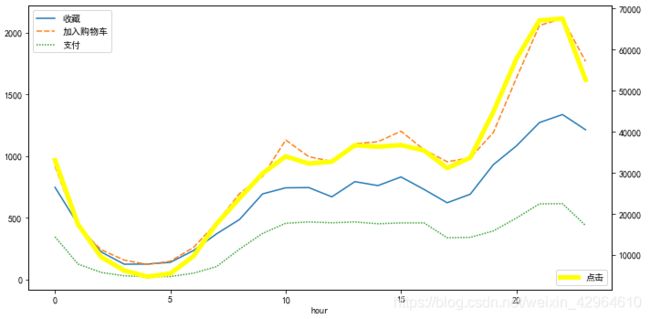
可以看出变化趋势和整体访问趋势一致,各个行为的变化趋势也大致相似。
4、用户消费情况分析
首先筛选出用户下单的相关数据,如下:
total_custome = data[data['behavior_type'] == 4].groupby(["date","user_id"])["behavior_type"].count().reset_index().rename(columns={"behavior_type":"total"})
print(total_custome.head())4.1、分析用户每天的每用户的消费金额情况,因为没有用户消费金额数据,因此使用用户消费次数代替,如下:
# 每天消费的总次数/每天消费的人数
total_custome1 = total_custome.groupby("date").sum()["total"]/total_custome.groupby("date").count()["total"]
# 绘图如下
x = len(total_custome1.index.astype(str))
y = total_custome1.index.astype(str)
plt.figure(figsize=(10,5))
plt.plot(total_custome1.index.astype(str),total_custome1.values)
# plt.xticks(range(0,30,7),[y[i] for i in range(0,x,7)],rotation=90)
plt.xticks(rotation=90)
plt.title("每天的人均消费次数")
plt.grid(color='r', linestyle='--', linewidth=0.2)
plt.show()结果如下:
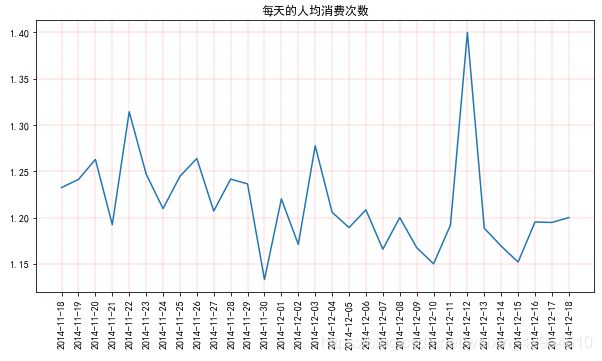
可以看出,人均消费次数在1.1到1.3上下波动,其中12-12日达到峰值1.4,主要是因为双十二促销导致的数据激增。
4.2、复购率分析
主要是通过用户下单次数超过两次的人数/总人数
# 复购率分析
re_buy = data[data["behavior_type"]==4].groupby("user_id")["date"].apply(lambda x:x.nunique())
print(len(re_buy))
re_buy[re_buy >= 2].count() / re_buy.count()5、转化漏斗分析
数据转换,如下:
# 漏斗分析
data_count = data.groupby("behavior_type").size().reset_index().rename(columns={"behavior_type":"环节",0:"人数"})
type_dict = {
1:"点击",
2:"收藏",
3:"加购",
4:"支付"
}
data_count["环节"] = data_count["环节"].map(type_dict)结构如下:
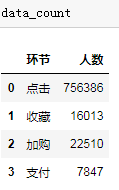
分析单一转化率和总体转化率,如下:
click_num = data_count.iloc[0]["人数"]
collect_num = data_count.loc[1]["人数"]
add_num = data_count.loc[2]["人数"]
pay_num = data_count.iloc[3]["人数"]
funnel = pd.DataFrame({"环节":["点击","收藏及加入购物车","支付"],"人数":[click_num,collect_num+add_num,pay_num]})
funnel["总体转化率"] = [i/funnel["人数"][0] for i in funnel["人数"]]
funnel["单一转化率"] = np.array([1.0,2.0,3.0])
for i in range(0,len(funnel["人数"])):
if i == 0:
funnel["单一转化率"][i] = 1.0
else:
funnel["单一转化率"][i] = funnel["人数"][i] / funnel["人数"][i-1]
绘制漏斗图
# 绘制漏斗图
from pyecharts import options as opts
from pyecharts.charts import Funnel
funnels = (
Funnel()
.add(
"商品",
[list(z) for z in zip(funnel["环节"], funnel["总体转化率"]*100)],
tooltip_opts=opts.TooltipOpts(trigger="item", formatter="{a}
{b} : {c}%"),
label_opts=opts.LabelOpts(position="outside"),
)
.set_global_opts(title_opts=opts.TitleOpts(title="用户购物行为分析漏斗图"))
)
funnels.render_notebook()结果如下:

可以看出,点击到点击到收藏及加购的转化率为5.09%,再到支付的转化率为1.04%,可以看到从浏览到加入购物车或者收藏这一环节的流失率较大,可能是因为用户不感兴趣或者页面设计不合理等因素,需要具体分析。
6、用户价值模型分析
RFM模型说明参考:RFM模型说明
因为数据中没有金额数据,所以暂时用R\F进行划分,计算着两个值,如下:
# 客户价值分析
from datetime import datetime
# 最近一次购买距离现在的天数
recent_buy = data[data["behavior_type"]==4].groupby("user_id")["date"].apply(lambda x:datetime(2014,12,20) - x.sort_values(ascending=False).iloc[0]).reset_index().rename(columns={"date":"recent"})
recent_buy["recent"] = recent_buy["recent"].apply(lambda x: x.days)
# 购买次数计算
buy_freq = data[data["behavior_type"]==4].groupby("user_id")["date"].count().reset_index().rename(columns={"date":"freq"})
# 将两组数据合并
new_recent_buy_freq = pd.merge(recent_buy,buy_freq,how='inner',on="user_id")
new_recent_buy_freq结果如下:
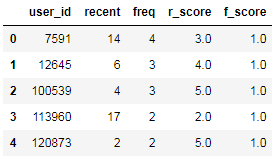
不同类型打分
# 不同类型打分
r_bins = [0,5,10,15,20,50]
f_bins = [1,20,40,60,80,100]
new_recent_buy_freq['r_score'] = pd.cut(x=new_recent_buy_freq['recent'],bins=r_bins,labels=[5,4,3,2,1],right=False)
new_recent_buy_freq['f_score'] = pd.cut(x=new_recent_buy_freq['freq'],bins=f_bins,labels=[1,2,3,4,5],right=False)
for i in ["r_score","f_score"]:
new_recent_buy_freq[i] = new_recent_buy_freq[i].astype(float)
new_recent_buy_freq.head()结果如下:
# 根据用户打分划分用户
new_recent_buy_freq["r"] = np.where(new_recent_buy_freq["r_score"]>3.059531,"高","低")
new_recent_buy_freq["f"] = np.where(new_recent_buy_freq["f_score"]>1.003007,"高","低")
new_recent_buy_freq["value"] = new_recent_buy_freq["r"].str[:] + new_recent_buy_freq["f"].str[:]
# 根据打分为用户划分标签
def trans_labels(x):
if x == "高高":
return"重要价值客户"
elif x == "低高":
return"重要唤回客户"
elif x == "高低":
return"重要深耕客户"
else:
return"重要挽回客户"
new_recent_buy_freq["标签"] = new_recent_buy_freq["value"].apply(trans_labels)
label_data = new_recent_buy_freq["标签"].value_counts()
label_data结果如下:

可以看出重要挽回客户和重要深耕客户,可以针对这部分用户设定相应的营销策略。
7、机器学习算法简介
数据建模的大致流程:

最简单的KNN算法,是一种比较简单的有监督学习算法,主要用于分类,其基本原理是主要是根据需要分类的数据与已经分好的数据特征之间的距离来划分,若K个值中有较多的距离与A相近,则属于A类,若与B相近,则属于B类
还是以上面的为例,假设我们知道用户最近一次距现在的天数、最近的消费次数,以及用户标签,其中前两个可以作为特征,后面的作为划分结果,转化数据,如下:
new_data = new_recent_buy_freq[["user_id","recent","freq","标签"]]
dict = {
"重要挽回客户":1,
"重要深耕客户":2,
"重要价值客户":3,
"重要唤回客户":4,
}
new_data["标签"] = new_data["标签"].map(dict)本次我们直接调用sklearn中的KNN算法,则具体实现为:
# 选取特征
x = new_data[["recent","freq"]]
y = new_data["标签"]
# 引入包
from sklearn.model_selection import train_test_split,cross_val_score
from sklearn.neighbors import KNeighborsClassifier
# 划分训练数据和测试数据
x_train,x_test,y_train,y_test = train_test_split(x,y, test_size=0.29, random_state=42)
# 训练模型
estimator = KNeighborsClassifier()
estimator.fit(x_train,y_train)
# 测试模型
y_predicted = estimator.predict(x_test)
accuracy = np.mean(y_predicted == y_test)*100
print('The accuracy is {0:.1f}%'.format(accuracy))最终准确率为:99.6%,可以看出模型效果比较好。
五、总结
本次主要分析了用户的消费行为数据,可以得出相应的结论,其中:
1、用户在双十二期间访问量激增,主要是因为商家的优惠促销活动导致的,因为商家可以不定期针对自己的用户群体做相应的促销活动
2、可以看到用户在早上6:00-8:00之间、晚上下班时间点、晚上8:00-10:00访问量较大,可能是因为上下班期间用户在路上逛淘宝,晚上下班吃完饭后玩手机,因此可以在这个时间段内推出用户比较感兴趣的商品或者提供相应的优惠券
3、针对不同的用户实行不同的营销策略,对于比较忠诚的用户可以给予更多的关爱
4、浏览到收藏/加入购物车这一环节转化率低,需对其进一步挖掘分析转化率低的原因,可以通过AB测试等进行分析
5、对于销量排名靠前的商品可以通过不同的方式进行产品曝光