R语言实战笔记--第十五章 处理缺失数据
R语言实战笔记–第十五章 处理缺失数据
标签(空格分隔): R语言 处理缺失数据 VIM mice
缺失值(NA),是导致我们计算错误的一大来源,处理缺失数据在实际的应用中有着较为重要的作用。
基本方法
使用函数中内置的缺失值处理参数:在一般的计算函数如sum中,就包括了na.rm=T/F来控制是否忽略缺失值,默认不忽略,计算结果为NA,若忽略,则返回排除缺失值之后的计算结果。
使用na.omiit()函数处理:na.omit()函数可以把含有缺失值(NA)的向量的元素、矩阵和数据框的行删除。对向量和矩阵,删除后返回一个omit对象,并且显示删除了元素的下标或矩阵的行号,返回对象名称;对数据框,则直接返回去除缺失所在行之后的数据框对象。具体可使用example(na.omit)查看。
高级方法
完整的处理步骤包含:
1、识别缺失数据;
2、检查导致缺失数据的原因;
3、删除含缺失值的实例或用合理的值代替(插补)缺失值。
很明显的是,识别缺失数据是可以由机器完成的,但是,缺失数据原因的检查,以及选择删除还是使用某种合理值代替缺失数据均需要人工来选择,需要对数据的收集过程有所理解才能知道数据缺失原因,知道数据的含义及实际作用才能理解使用什么样的值才合理(可靠、准确)。
识别缺失值
缺失值(NA)、不可能值(NaN)以及无穷值(-Inf,Inf)的识别方法分别是is.na(),is.nan()和is.infinite(),每个返回结果均为TRUE/FALSE,它会识别每一个元素并返回结果,再使用sum()函数及mean()函数来求得缺失值的数量以及缺失比例。
另外,使用complete.cases()函数可得到数据框中不含缺失值(NA)及不可能值(NaN)的行,!complete.cases()则相反。注意,它并不能识别无穷值!
探索缺失值模式
缺失值的识别不仅仅是知道哪里有缺失,也在于怎么样的缺失(即缺失模式),这样才更有较的帮助我们进行下一步(寻找缺失原因)。方法有如下几种,列表样式、图形样式以及相关性样式:
列表
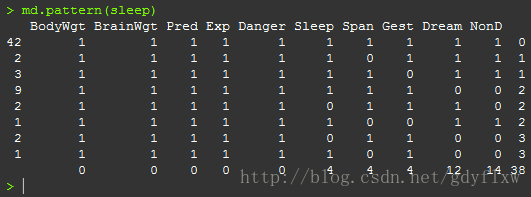
利用mice包中的md.pattern()函数,可得到一个信息列表,它的第一列是符合右边样式的行数,最后一列表示缺失值个数,中间的列是dataframe的原有列(顺序会改变,由缺失数量由小到大排列),它的下面使用1表示非缺失值,0表示缺失值,如下图,图中第二行表示数据框中,仅Span变量有缺失的行有2行,缺失数为1个。
图形
使用VIM包来进行图形解释,最新版的VIM包已不包含GUI,需要界面的需要另外安装VIMGUI包来使用。
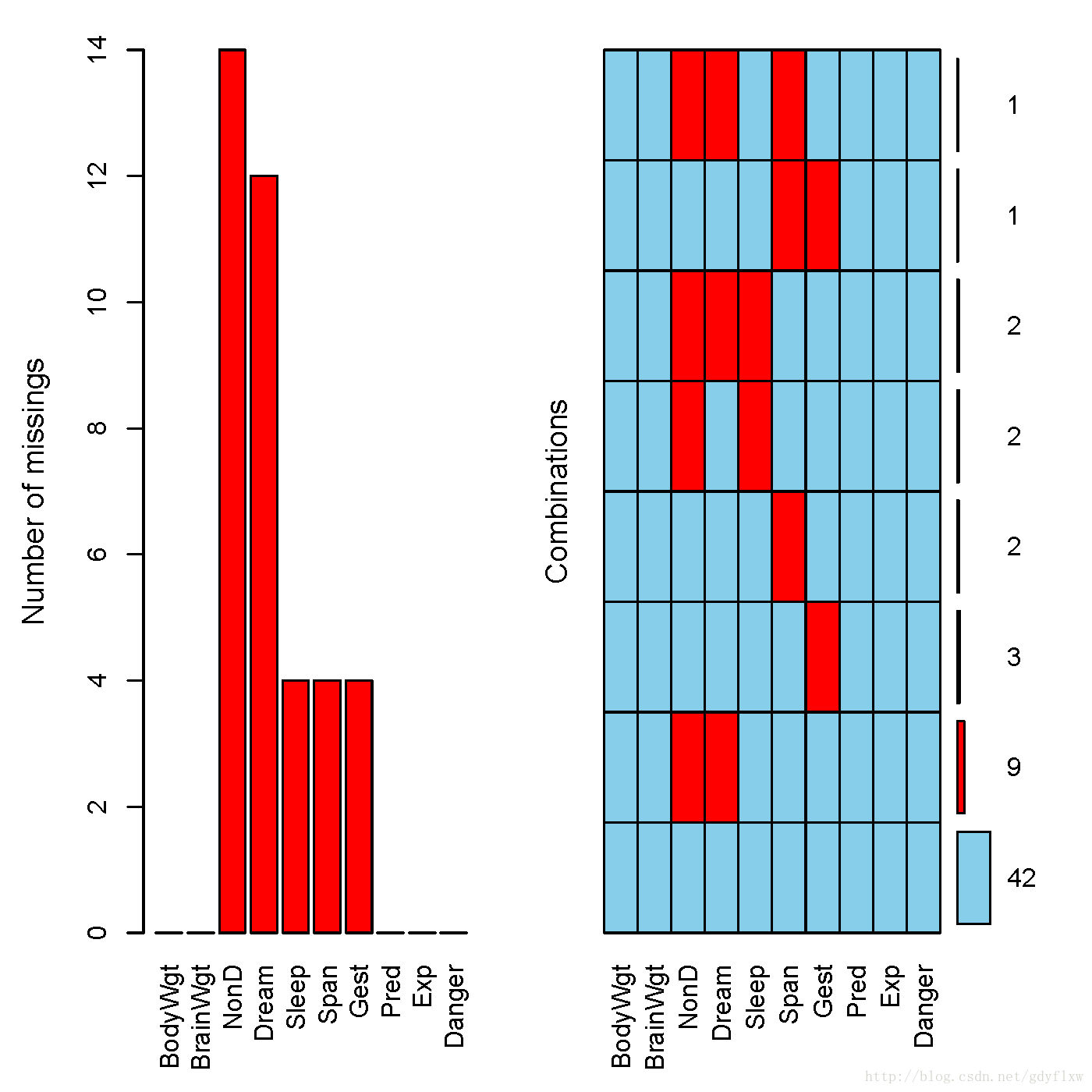
图形样式涉及aggr()、matrixplot()和scatteMiss()(实际上,R语言实战中并没有介绍此函数,而去讲了marginplot()这个函数)三个函数,各函数语法如下:
aggr(dataframe,prop=T/F,numbers=T/F),其中prop参数为是否以比例显示缺失数,T显示比例,F显示数值;numbers参数为是否显示数值标签,aggr图显示一个缺失数量的;
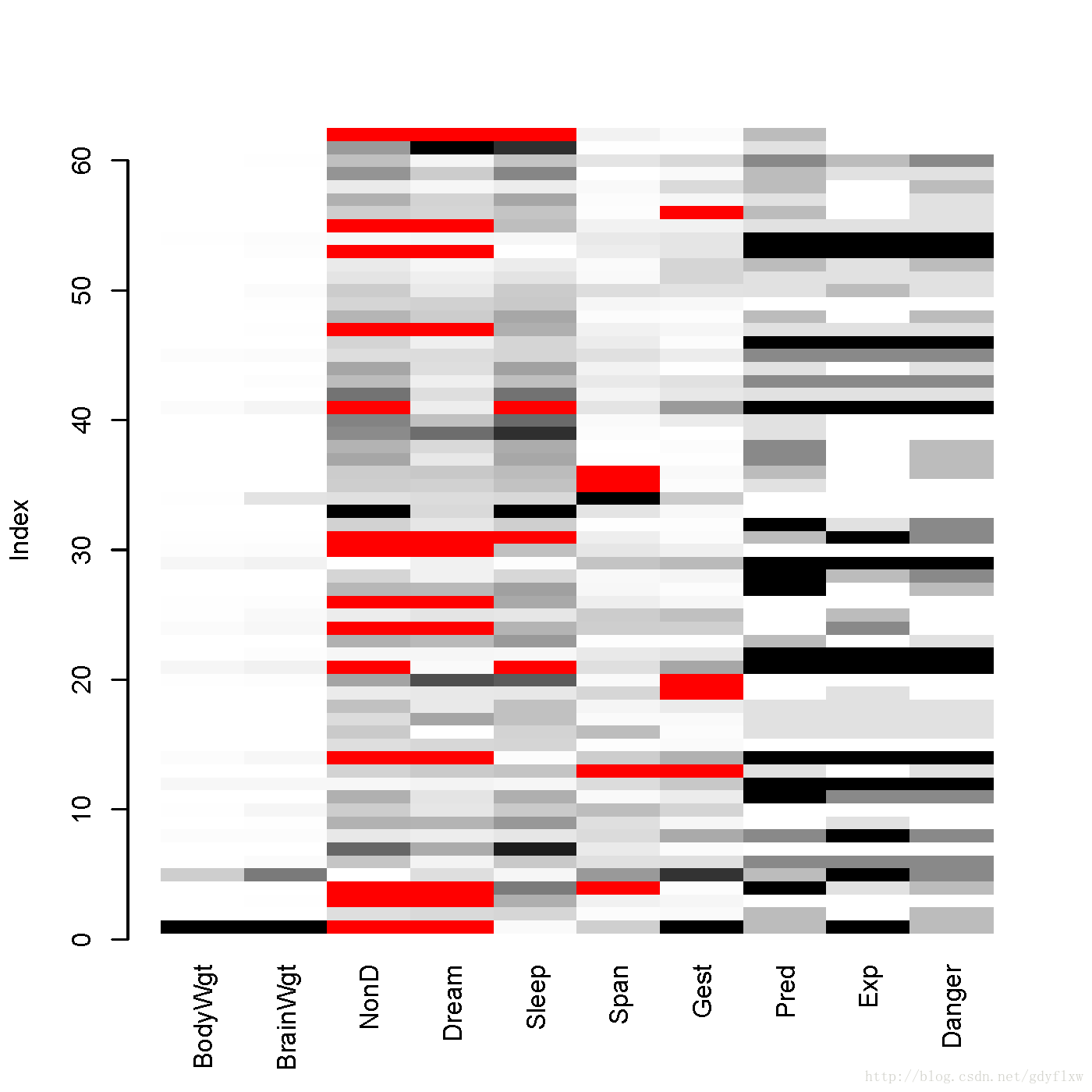
matrixplot(dataframe),矩阵图可以看出数据框中的各项数据缺失值是否存在某种关系,比如某些变量的缺失和另一个变量的某些值有关等,红色代表缺失,从浅到深色代表数值从小到大;
scattMiss(x),x是一个仅包含两列数据的数据框,显示的是这两个变量的散点图,横坐标的缺失值用竖虚线标记,个人理解,此图可以看出在横坐标上的缺失值之间包含有多少数据。
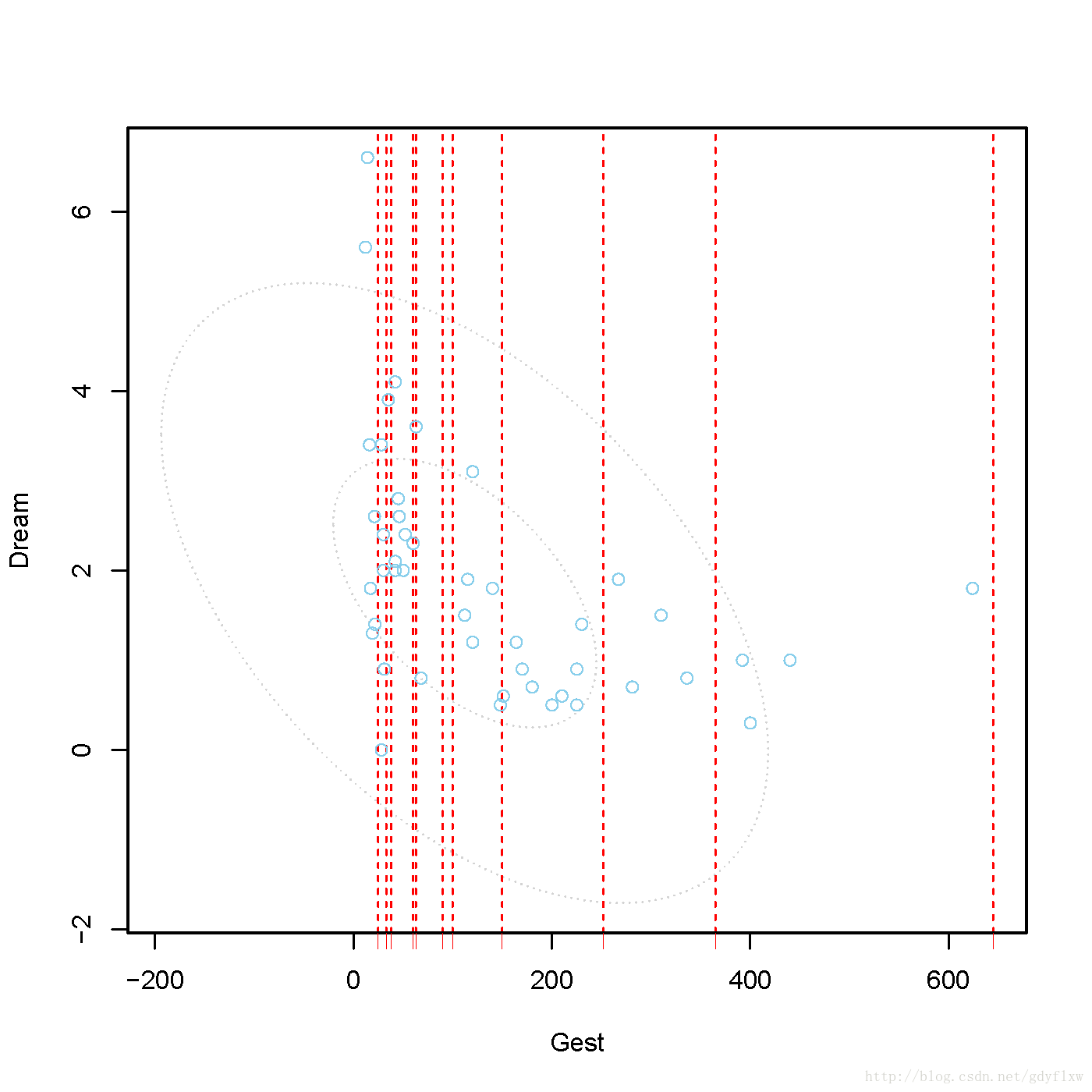
marginplot(x),x是一个仅包含峡谷列数据的数据框,与scattMiss的数据源一致,也是绘制一副散点图,但是它还包括了两个变量包含与不包含另一个变量的缺失值时的箱线图,缺失值对应的数据点,以及散点图。
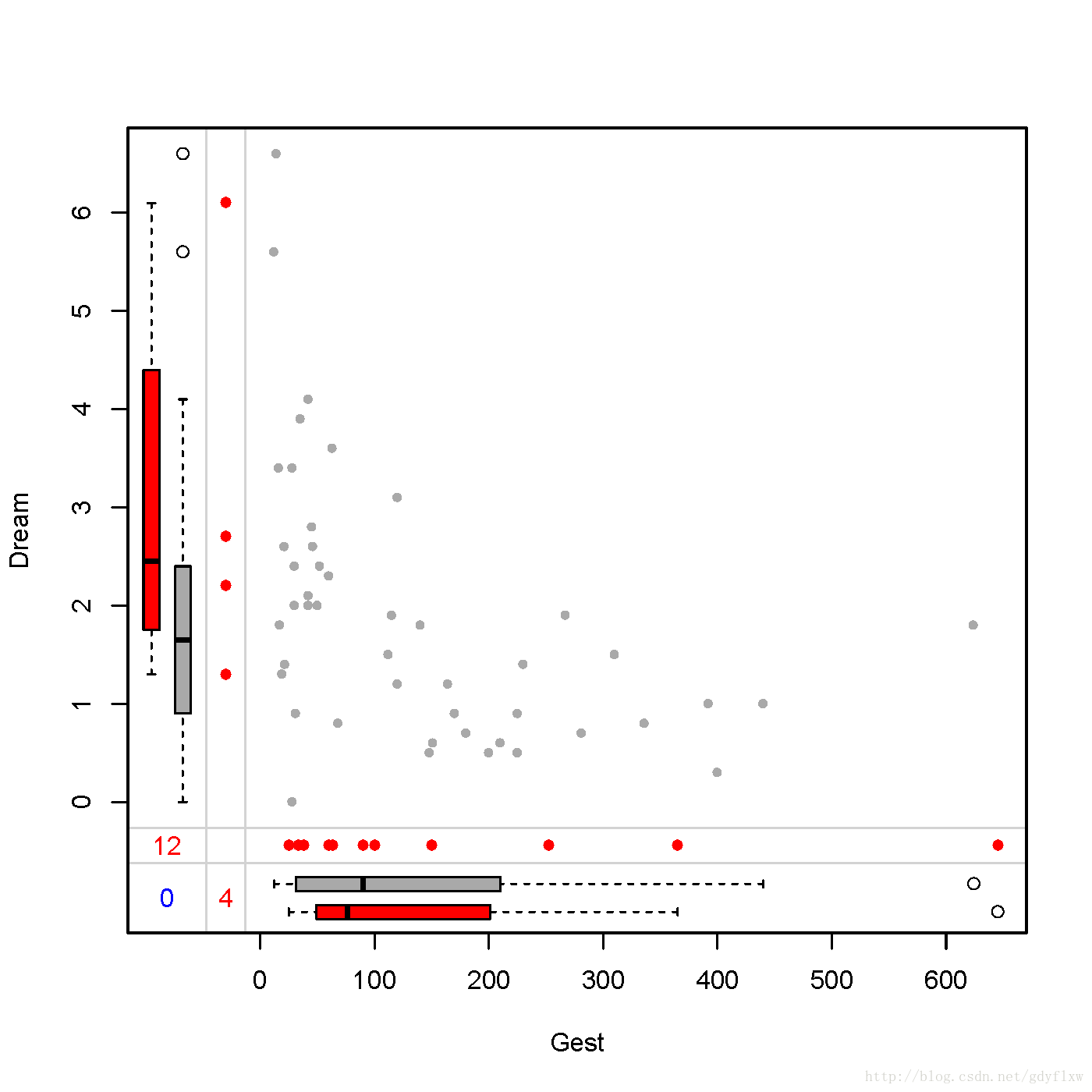
相关性
相关性探索,对于图形来说,相关性探索更为具体,它包含了所胡数据的具体相关关系,对于判断缺失数据的类型有巨大的帮助。首先说一下缺失数据的类型,分别为三种:完全随机缺失(MCAR),随机缺失(MAR)和非随机缺失(NMAR):
MCAR:若某变量的缺失数据与其它任何已观测和未观测变量都不相关则数据称为完全随机缺失
MAR:若某变量的缺失数据与其它观测变量相关,但与它自己的未观测值不相关,则称之为随机缺失
NMAR:若某变量即不是MCAR也不是MAR,则称之为非随机缺失。
用例子来说明这三种数据,假设有一份工作情况问卷,工作类型经常缺失,这个项目被放在了问卷的背面,以致被调查者可能忽略了这个项目,那么这个项目缺失值属于MCAR,某个区域的被调查者年收入情况存在较多缺失,那么这一项属于MAR,女性的年龄通常也会缺失,并且年龄越大越容易缺失,那么此项属于NMAR。
检查相关性代码如下:
#先把数据框转化为以指示变量代替的矩阵(有时称为影子矩阵,它的缺失数据显示为1,非缺失数据显示0)
x<-as.data.frame(abs(is.na(sleep)))
head(sleep,n=5)
head(x,n=5)
#把含有(但不全是)缺失值的变量提取出来,R语言实战中的sd不能使用,变为colMeans或colSums才可以使用
y<-x[which(colMeans(x)>0)]
#求各缺失变量之间的相关关系
cor(y)
#求含缺失值变量与其它观测变量的关系
cor(sleep,y,use=”pairwise.complete.obs”)
最后所得的数据表即变缺失值变量与其它观测变量的关系,可忽略其中的NA值及后面的警告信息。例子中的相关值并不是非常大,但也不小,可以排除MCAR,但有可能是MAR。
缺失值的来由及影响
识别缺失数据的数目、分布和模式有两个目的:(1)分析生成缺失数据的潜在机制;(2)评价缺失数据对回答实质性问题的影响。具体来讲,我们想弄清楚以下几个问题:
1)缺失数据的比例多大?
2)缺失数据是否集中在少数几个变量上,抑或广泛存在?
3)缺失是随机产生的吗?
4)缺失数据间的相关性或与可观测数据间的相关性,是否可以表明产生缺失值的机制呢?
理性处理缺失值
数据存在即有它的意义,对缺失值并不能一棒子打死,全部删除,这样会导致数据的失真,缺失值的处理目前有三种较为流行的方法:恢复数据的推理方法、涉及删除缺失值的传统方法、涉及模拟的现代方法。而我们的目标一直未变:在没有完整信息的情况下,尽可能精确地回答收集数据所要解决的实质性问题。
推理方法
推理方法是根据变量间的数据或逻辑关系来填补或恢复缺失值,比如sleep中的Sleep是NonD和Dream的和,那么,这三者任意缺失一个,都可以通过这个数学关系(Sleep=NonD+Dream)来进行恢复,这是数学关系填补缺失值,又比如调查问卷中出生年月以及年龄这两项,可以通过填写问卷的日期以及前两项中的任意一项大致推理出另一项。
前面两个例子是通过数学关系来填补或恢复缺失值,下面举例子说明通过逻辑关系填补数据:调查问卷中涉及性别项有缺失值,此时,一般来说,通过名字可以大致确定男女,比如说包含“昊”、“龙”之类的名字通常是男,包含“诗”、“琪”之类的名字通常是女,这样就可以通过名字来确定大部分的性别。
推理方法可以是准确的(明确的数学关系),也可以是近似的(逻辑关系),选择推理方法常需要创造性和想法,数学关系及逻辑关系通常是隐藏的,并不是直接的,所以需要数据有一定的了解才能更好的探寻隐含的关系,并推理出合理的关系来进行填补。
行删除法
行删除法,也是完整实例分析,即把所有含缺失数据的行都删除,留下没有缺失数据的完整子集,这种方法叫行删除法,注意的是,行删除法对MCAR且缺失数据比例不高的情况下有效,若数据为MAR或比例过高,则会使统计效力降低。
对sleep数据集,缺失数据可以通过如下代码实现,并探寻某些线性关系,下面各种方法等效。
cor(na.omit(sleep))
cor(sleep[complete.cases(sleep),])
cor(sleep,use="complete.obs")
#回归分析Dream与Span、Gest的关系
fit<-lm(Dream~Span+Gest,data=na.omit(sleep)
summary(fit)
多重插补(MI)
多重插补方法在R语言实战中简略介绍了mice包的使用,若要更多的了解多重插补,需要自行翻阅更多的文献。除了mice包,还有Amelia和mi两个包也可以实现多重插补方法。
mice包的插补分析过程分为三个步骤
1. 插补并划分子集:它将从一个含缺失值的数据集中生成一个完整子集,每个子集中,将使用蒙特卡洛方法来填补缺失值,通过会生成3-10子集。插补方法可以是使用预测的均值、Logistic或多元Logistic回归、贝叶斯线性回归、判别分析、两水平正态插补和从观测值中随机抽样等,也可以是用户自定方法。
2. 使用标准的统计方法分析各子集数据:如线性模型(lm)、广义线性模型(glm)、广义可加模型(gam)或负二项模型(nbrm)等
3. 组合各子集的统计分析结果:组合分析结果,给出引入缺失值时的置信区间。
以例子说明使用步骤:
library(mice) #载入mice包
data(sleep,package=VIM) #载入sleep数据
imp<-mice(sleep,m=5,seed=1234) #插补并划分子集
fit<-with(imp,lm(Dream~Span+Gest)) #对每个子集使用统计分析方法
pooled<-pool(fit) #组合结果
summary(pooled) #显示组合结果,fmi栏给出引入缺失而引起的变异占整体不确定性的比例
imp #查看插补并划分之后各子集的汇总情况,可以看到缺失情况、插补使用的方法、以及预测变量矩阵(PredictorMatrix,行代表插补变量,列代表所使用的变量,1代表已使用)
imp$imp$Dream #查看Dream变量的5次插补值信息,检查该数据可以判断插补值是否合理
complete(imp,action=#) #action后的“#”代表第几个划分子集,本函数用于查看第几个子集的数据明细。
处理缺失值的其它方法
先看一下处理缺失值的包的列表:
| 软件包 | 描述 |
|---|---|
| Hmisc | 包含多种函数,支持简单插补、多重插补和典型变量插补 |
| mvnmle | 对多元正态分布数据中缺失值的最大似然估计 |
| cat | 对数线性模型中多元类别型变量的多重插补 |
| arrayImpute、arrayMissPattern、SeqKnn | 处理微阵列缺失数据的实用函数 |
| longitudinalData | 相关的函数列表,比如对时间序列缺失值进行插补的一系列函数 |
| kmi | 处理生存分析缺失值的Kaplan-Meier多重插补 |
| mix | 一般位置模型中混合类别型和连续型数据的多重插补 |
| pan | 多元面板数据或聚类数据的多重插补 |
各个包的使用需要后续自行寻找相关资料理解使用,还有两种还在使用但不建议使用的处理缺失值方法:成对删除和简单(非随机)插补。
成对删除
在之前分析缺失数据集的相关性的时候就已经使用过了
cor(sleep,use="pairwise.complete.obs")
在这种方法中,任何两个变量的相关系数都只利用了这两个变量的可用观测,但这种方法看似利用了所有可用数据,但实现上每次计算使用了不同的子集,这将会导致一些扭曲的,难以理解的结果。需要谨慎使用此种方法。
简单(非随机)插补
即使用某个定值(如均值、中位数、众数等)来替换变量中缺失的值。它的优点是不会减少分析时的可用样本量,不会引入随机误差,缺点是对非MCAR数据会产生有偏结果,若缺失数目较大时,还会低估标准差,曲解变量的相关性生成不正确的检验统计p值。因此,也需要谨慎使用。