JAVA语言规范 JAVA SE 8 - 类型转换与上下文
JAVA语言规范 JAVA SE 8 - 类型转换与上下文
- 转换的种类
- 标识转换
- 拓宽简单类型转换
- 窄化简单类型转换
- 拓宽和窄化简单类型转换
- 拓宽引用类型转换
- 窄化引用类型转换
- 装箱转换
- 拆箱转换
- 非受检转换
- 捕获转换
- 字符串转换
- 被禁止的转换
- 值集转换
- 赋值上下文
- 方法调用上下文
- 字符串上下文
- 强制类型转换上下文
- 引用类型强制类型转换
- 受检强制类型转换和非受检强制类型转换
- 运行时的受检强制类型转换
- 数字上下文
- 一元数字提升
- 二元数字提升
用Java编程语言编写的每一个表达式要么不产生任何结果,要么有一个可以在编译时推断出来的类型。当表达式出现在大多数的上下文中时,它都必须与该上下文所期望的类型兼容,这个类型被称为目标类型。为方便起见,表达式与其周围上下文的兼容性可以借助下面两种方式实现:
- 首先,对于被称为合成表达式的表达式推断出来的类型可能受到目标类型的影响,因此相同的表达式在不同的上下文中可能会有不同的类型。
- 其次,在表达式的类型被推断出来后,会执行从表达式的类型到目标类型的隐式类型转换。
如果这两种策略都无法产生恰当的类型,那么就会产生编译时错误。
确定一个表达式是否是合成表达式的规则,以及在是合成表达式的情况下,其在特定上下文中的类型与兼容性,将依据上下文的种类以及表达式的形式而变化。除了影响表达式的类型之外,目标类型在某些情况下还会影响表达式运行时的行为,以便产生具有恰当类型的值。
类似地,确定目标类型是否允许隐式转换的规则,将依据上下文的种类、表达式的类型以及作为特例的常量表达式的值而变化。从类型S到类型T的转换将允许S类型的表达式在编译时被当作T类型进行处理。在某些情况下,这样做要求在运行时要有相应的动作去检查这种转换的有效性,或者将该表达式运行时的值转译为适合新类型T的形式。
编译时和运行时的类型转换
- Object类型到Thread类型的转换要求进行运行时检查,以确保运行时的值确实是 Thread类或其子类的实例,如果不是,则抛出异常。
- Thread类型到Object类型的转换不要求在运行时做任何动作。Thread是Object的子类,因此任何Thread类型的表达式所产生的引用都是有效的Object类型的引用值。
- int类型到long类型的转换要求在运行时对32位整数值进行符号扩展,扩展成为64 位long表示形式。这种转换不会丢失任何信息。
- double类型到long类型的转换要求进行从64位浮点数值到64位整数表示形式的非平凡转换。这种转换有可能会造成信息丢失,具体取决于运行时的实际数值。
在Java编程语言中可能会执行的特定转换可以分为以下几种宽泛的种类:
- 标识转换;
- 拓宽简单类型转换;
- 窄化简单类型转换;
- 拓宽引用类型转换;
- 窄化引用类型转换;
- 装箱转换;
- 拆箱装换;
- 非受检转换;
- 捕获转换;
- 字符串转换;
- 值集转换。
在下列6种转换上下文中,合成表达式可能会受到上下文的影响,或者会发生隐式转换。每种上下文对于确定合成表达式的类型有不同的规则,并且都允许执行上述某些种类的转换,但是同时又会禁止其他种类的转换。这些上下文是:
- 赋值上下文:表达式的值被绑定到某个具名变量上。在这里,可以拓宽简单类型和引用类型,值可以被装箱和拆箱,也可以窄化某些简单常量表达式,还可以进行非受检转换。
- 严格的调用上下文:参数被绑定到构造器或方法的形参上。在这里,可以进行拓宽简单类型、拓宽引用类型和非受检转换。
- 宽松的调用上下文:与严格的调用上下文一样, 引元被绑定到形参上。如果只使用严格的调用上下文无法找到任何可应用的声明, 那么方法或构造器调用就可能提供这种上下文。除了拓宽转换和非受检转换,该上下文还允许执行装箱转换和拆箱转换。
- 字符串上下文:任何类型的值都会被转换为String类型 的对象。
- 强制类型转换上下文:表达式的值被转换为由强制类型转换操作符显式指定的类型。强制类型转换上下文比赋值上下文和宽松的调用上下文 更具包容性,因为它允许除字符串转换之外的任何具体转换,但是在运行时会检查某些强制类型转换到引用类型的操作的正确性。
- 数字上下文:数字型操作符的操作数会拓宽为公共类型,以确保操作可以执行。
“转换”还能用来非特指地描述在某个特定转换中的任何转换。例如,我们说某个局部变量的初始化器的表达式将接受“赋值转换”,这意味着系统会根据赋值上下文的规则隐式地为该表达式选择一种具体的转换。
各种转换上下文
class Test {
public static void main(String[] args) {
// Casting conversion (5.4) of a float literal to
// type int. Without the cast operator, this would
// be a compile-time error, because this is a
// narrowing conversion (5.1.3):
int i = (int)12.5f;
// String conversion (5.4) of i1s int value:
System.out.println(" (int) 12.5f==" + i);
// Assignment conversion (5.2) of i's value to type
// float. This is a widening conversion (5.1.2):
float f = i;
// String conversion of f's float value:
System.out.println("after float widening: " + f);
// Numeric promotion (5.6) of i' s value to type
// float. This is a binary numeric promotion.
// After promotion, the operation is float*float:
System.out.print(f);
f = f * i;
// Two string conversions of i and f:
System.out.println("*" + i + "==" + f);
// Invocation conversion (5.3) of f's value
// to type double, needed because the method Math.sin
// accepts only a double argument:
double d = Math.sin(f);
// Two string conversions of f and d:
System.out.println("Math.sin(" + f + ")==" + d);
}
}
这个程序会产生如下输出:
(int)12.5f==12
after float widening: 12.0
12.0*12=144.0
Math.sin(144.0)=-0.49102159389846934
转换的种类
Java编程语言中具体的类型转换可以分成13种。
标识转换
对任何类型来说,将其转换为同一种类型都是允许的。
这看起来可能根本不值一提,但是它具有两种实际意义。首先,对于表达式来说,总是允许一开始就具有想要的类型。因此,有了上面这条简单的规则,每一个表达式都可以执行简单的标识转换。其次,它意味着在程序中为了显得更清晰,允许包含冗余的强制类型转换操作符。
拓宽简单类型转换
我们把19种简单类型转换统称为拓宽简单类型转换:
- byte 转换为 short、int、long、float 或 double;
- short 转换为 int、long、float 或 double;
- char 转换为 int、long、float 或 double;
- int 转换为 long、float 或 double;
- long 转换为 float 或 double;
- float转换为double.
在下列情况下,拓宽简单类型转换不会丢失有关数字型值的整体大小信息,其中数字型值会被精确地保留:
- 从一种整数类型转换为另一种整数类型;
- 从byte、short或char类型转换为浮点类型;
- 从int转换为double类型;
- 在strictfp表达式中从float转换为double类型
非strictfp表达式中的从float到double类型的拓宽简单类型转换可能会丢失被转换值的整体大小的信息。
从int、long到float类型,或从long到double类型的拓宽简单类型转换可能会导致精度损失,即转换结果可能会丢失被转换值的最低几位。在这种情况下,所产生的浮点值是 使用IEEE 754最近舍入模式对整数值进行恰当舍入而得到的版本。
有符号整数值向整数类型T的拓宽转换将直接对该整数值的二进制补码表示进行符号扩展,以填充更宽的格式。
char类型到整数类型T的拓宽转换将对char值的表示进行0扩展,以填充更宽的格式。
尽管有可能会发生精度损失,但是拓宽简单类型转换永远不会导致运行时异常。
拓宽简单类型转换
class Test {
public static void main(String[] args) {
int big = 1234567890;
float approx = big;
System.out.println(big - (int)approx);
}
}
这个程序会打印:
-46
这表明在将int类型转换为float类型时信息丢失了,因为float类型的值无法精确到9位。
窄化简单类型转换
我们把22种简单类型转换统称为窄化简单类型转换:
- short 转换为 byte 或 char;
- char 转换为 byte 或 short;
- int 转换为 byte、short 或 char;
- long 转换为 byte、short、char 或 int;
- float 转换为 byte、short 、 char、int 或 long;
- double 转换为 byte、short、char、int、long 或 float。
窄化简单类型转换可能会丢失有关数字型值的整体大小信息,并且可能会丢失精度和范围。
从double到float类型的窄化简单类型转换是受IEEE 754舍入规则支配的。这种转换会丢失精度,还会丢失范围,导致从非0的double值产生float类型的0,从double的有穷大小的值产生float的无穷大的值。double类型的NaN会转换成float类型的NaN,而double的无穷大值会转换成同样符号的float的无穷大值。
有符号整数值向整数类型T的窄化转换将直接丢弃最低的n位数字之外的其他所有数字,其中n是用来表示T类型的位数。除了可能会丢失数字型值的大小信息外,这种方式还可能会导致所产生的值的符号位不同于输入值的符号位。
char类型到整数类型T的窄化转换同样将直接丢弃最低的n位数字之外的其他所有数字,其中n是用来表示T类型的位数。除了可能会丢失数字型值的大小信息外,这种方式还可能会导致所产生的值是负数,尽管字符表示的是16位的无符号整数值。
浮点数向整数类型T的窄化转换有两个步骤:
1)第一步,如果T是long类型,浮点数将按照下面的规则被转换为long, 或者如果T是byte、short、char或int类型,浮点数被转换为int:
- 如果该浮点数是NaN,转换的第一步的结果就是int类型或long类型的0。
- 否则,如果该浮点数不是无穷大,那么该浮点值将被舍入到整数值v, 使用IEEE 754的向0舍入模式进行向0舍入。这会产生下面两种情况:
a) 如果T是long类型,并且这个整数值可以表示成long类型,那么第一步的结果就是long类型的值V。
b) 否则,如果这个整数值可以表示成int类型,那么第一步的结果就是int类型的值V。 - 否则,必为下列两种情况之一:
c) 这个值太小了(具有很大绝对值的负值,或者是负无穷大),第一步的结果就是 int 或 long 类型能够表示的最小值。
d) 这个值太大了(具有很大绝对值的正值,或者是正无穷大),第一步的结果就是 int 或 long 类型能够表示的最大值。
2)第二步:
- 如果T是int或long类型,该转换的结果就是第一步的结果。
- 如果T是byte、char或short类型,该转换的结果就是第一步的结果进行窄化转换到T类型的结果。
尽管有可能出现向上溢出、向下溢出或信息丢失,但是窄化简单类型转换不会导致运行时异常。
窄化简单类型转换
class Test {
public static void main(String[] args) {
float fmin = Float.NEGATIVE_INFINITY;
float fmax = Float.POSITTVE_TNFINITY;
System.out.prlntln("long: " + (long) fmin + ".."+ (long)fmax);
System.out.prIntln("int: " + (int)fmin + ".."+ (int) fmax);
System.out.println("short: " + (short)fmin + ".."+ (short)fmax);
System.out.println("char: " + (int)(char)fmin + ".." + (int)(char)fmax);
System.out.println("byte: " + (byte)fmin + ".." + (byte)fmax);
}
}
这个程序会产生下面的输出:
long: -9223372036854775808..9223372036854775807
int: -2147483648..2147483647
short: 0..-1
char: 0..65535
byte: 0..-1
char、int 和 long 的处理结果并不奇怪,这些类型各自产生了它们能够表示的最小和最大的值。
byte和short的处理结果丢失了数值的符号和大小信息,并且丢失了精度。通过检查最大和最小的int值的最低位就可以理解为什么会产生这样的结果。最小的int值,用十六进制表示是0x80000000, 而最大的int值是0x7fffffff。这就解释了short的结果,它们是这两个值的低16位,即0x0000和0xffff ; 这也解释了 char的结果,它们也是这两个值的低16位,即'\u0000'和'\uffff';这同样解释了 byte的结果,它们是这些值的低8位,即 0x00 和 0xff。
丢失信息的窄化简单类型转换
class Test{
public static void main(String[] args) {
// A narrowing of int to short loses high bits:
System.out.println("(short)0xl2345678==0x" + Integer.toHexString((short)0x12345678));
// An int value too big for byte changes sign and magnitude:
System.out.println("(byte)255==" + (byte)255);
//A float value too big to fit gives largest int value:
System.out.println("(int)1e20f==" + (int)1e20f);
// A NaN converted to int yields zero:
System.out.println("(int)NaN==" + (int) Float.NaN);
// A double value too large for float yields infinity:
System.out.println("(float)-1el00==" + (float)-1el00);
// A double value too small for float underflows to zero:
System.out.println("(float)1e-50==" + (float)1e-50);
}
}
这个程序会产生下面的输出:
(short)0xl2345678==0x5678
(byte)255==-l
(int)1e20f=2147483647
(int)NaN==0
(float)-1e100==-Infinity
(float)1e-50=0.0
拓宽和窄化简单类型转换
下面的转换将拓宽和窄化简单类型转换结合在了一起:
- byte转换为char
首先,byte类型经过拓宽简单类型转换转换成了int类型,然后产生的int类型通过窄化简单类型转换转换成char类型。
拓宽引用类型转换
如果类型S是类型T的子类型,那么任何S类型的引用被转换成T类型的引用时,都会发生拓宽引用类型转换。
拓宽引用类型转换从来都不要求在运行时执行特殊动作,因此也就从来不会在运行时抛出异常。如果要将一个引用当作其他类型处理,而这种处理方式可以在编译时被证明是正确的,那么拓宽引用类型转换才会发生。
窄化引用类型转换
我们把6种转换统称为窄化引用类型转换:
- 将任意的S类型引用转换为任意的T类型引用,如果S是T的真超类型 。
有一种重要的特例,即从Object类类型到任意其他引用类型的窄化引用类型转换。 - 将任意的类类型C转换为任意的非参数化接口类型K,如果C不是final的并且没有实现K。
- 将任意的接口类型J转换为任意的不是final的非参数化类类型C。
- 如果J不是K的子接口,将任意的接口类型J转换为任意的非参数化接口类型K。
- 将接口类型Cloneable 和 java. io.Serializable 转换为任意的数组类型T[ ] 。
- 如果SC和TC是引用类型,并且存在从SC到TC的窄化引用类型转化,将任意数组类型SC[ ]转换为任意数组类型TC[ ]。
这些转换需要在运行时进行测试,以确认实际的引用值是否是新类型的合法值。如果不是,则抛出 ClassCastException。
真超类型这是按照真子集这样的概念翻译的。即A类型可以是A类型自身的超类型。此时这种转换就不属于窄化引用类型转换了。而只有S确定是T的超类型,且不是T自身时,才是窄化引用类型转换。
装箱转换
装箱转换将简单类型的表达式转换为相应的引用类型表达式。特别地,我们把9种转换统称为装箱转换:
- 从boolean类型转换为Boolean类型;
- 从byte类型转换为Byte类型;
- 从short类型转换为Short类型;
- 从char类型转换为Character类型;
- 从int类型转换为Integer类型;
- 从long类型转换为Long类型;
- 从float类型转换为Float类型;
- 从double类型转换为Double类型;
- 从空类型转换为空类型。
最后这条规则是必需的,因为条件操作符会将装箱转换应用于其操作数的类型,并在后续计算中使用转换所得的结果。
在运行时,装箱转换将按如下方式执行:
- 如果p是boolean类型的值,那么装箱转换将p转换为类的引用r ,并且其类型为Boolean ,使得
r.booleanValue() == p。 - 如果p是byte类型的值,那么装箱转换将p转换为类的引用r,并且其类型为Byte,使得
r.byteValue() == p。 - 如果p是char类型的值,那么装箱转换将p转换为类的引用r,并且其类型为Character,使得
r.charValue() == p。 - 如果p是short类型的值,那么装箱转换将p转换为类的引用r,并且其类型为Short, 使得
r.shortValue() == p。 - 如果p是int类型的值,那么装箱转换将p转换为类的引用r,并且其类型为Integer, 使得
r.intValue() == p。 - 如果p是long类型的值,那么装箱转换将p转换为类的引用r,并且其类型为Long,使得
r.longValue() == p。 - 如果p是float类型的值,那么:
-如果p不是NaN,那么装箱转换将p转换为类的引用r,并且其类型为Float, 使r.floatValue() == p。
-否则,装箱转换将p转换为类的引用r,并且其类型为Float,使得r.isNaN()的值为true。 - 如果p是double类型的值,那么:
-如果p不是NaN,那么装箱转换将p转换为类的引用r,并且其类型为Double,使 得r.doubleValue() == p。
-否则,装箱转换将p转换为类的引用工,并且其类型为Double,使得r.isNaN()的值为true。 - 如果p是任何其他类型的值,那么装箱转换等价于标识转换。
如果被装箱的p值是一个在-128〜127之间(闭区间)的int类型的整数字面常量,或者是布尔字面常量true或false,或者是一个在’\u0000’ 到-\u007f之间(闭区间)的char字符字面常量,那么若a和b是p的任意两个装箱转换的结果, 则 a == b 总是成立的。
理想状态下,装箱给定的简单类型的值p总是会产生同一个引用。但是在实际中,对于现有实现技术而言,也许并不可行,因此,上面这些规则是务实妥协的产物。上面这段话最后一个子句要求特定的常用值总是会被包装成不可区分的对象,而具体实现可以惰性地或积极地缓存这些对象。对于其他值,这些规则不允许程序员对被包装的值的标识做任何假设。 这将允许(但并非强制)共享部分或全部这些引用。注意,允许(非强制)共享long类型的整数字面常量。
这条规则将确保在最常见的情况中,其行为正是用户想要的,而不会因装箱导致过多的性能损害,这一点在小型设备上尤其重要。例如,内存受限的实现可以缓存所有char 和 short值,以及在-32K〜+32K 之间的所有int和long类型值。
如果需要为某种包装器类(Boolean、Byte、Character、Short、Integer、Long、Float 或Double)的一个新实例分配内存,但是却没有足够的可用内存了,那么装箱转换就会产生OutOfMetnoryError。
拆箱转换
拆箱转换将引用类型的表达式转换为相应的简单类型表达式。特别地,以下8种转换统称为拆箱转换:
- 从Boolean类型转换为boolean类型;
- 从Byte类型转换为byte类型;
- 从Short类型转换为short类型;
- 从Character类型转换为char类型;
- 从Integer类型转换为int类型;
- 从Long类型转换为long类型;
- 从Float类型转换为float类型;
- 从Double类型转换为double类型。
在运行时,拆箱转换将按如下方式执行:
- 如果r是Boolean类型的引用,那么拆箱转换将r转换为r.booleanValue();
- 如果r是Byte类型的引用,那么拆箱转换将r转换为r r.byteValue();
- 如果r是Character类型的引用,那么拆箱转换将r转换为r.characterValue();
- 如果r是Short类型的引用,那么拆箱转换将r转换为r.shortValue();
- 如果r是Integer类型的引用,那么拆箱转换将r转换为r.intValue();
- 如果r是Long类型的引用,那么拆箱转换将r转换为r.longValue();
- 如果r是Float类型的引用,那么拆箱转换将r转换为r.floatValue();
- 如果r是Double类型的引用,那么拆箱转换将r转换为r.doubleValue();
- 如果r是null,那么拆箱转换会抛NullPointerException。
如果某种类型是数字类型,或者是引用类型,但是可以通过拆箱转换将其转换为数字类型,那么它就被认为是可转换为数字类型的。
如果某种类型是整数类型,或者是引用类型,但是可以通过拆箱转换将其转换为整数类型,那么它就被认为是可转换为整数类型的。
非受检转换
假设G是带有n个类型参数的泛型声明,则:
存在从原生类或接口类型G到任意的形式为 G < T 1 , … , T n > G
存在从原生数组类型G[ ] k ^{k} k到任意的形式为 G < T 1 , … , T n > G
使用非受检转换会导致编译时非受检警告,除非所有类型引元 T i T_{i} Ti ( 1 ≤ i ≤ n 1\leq i \leq n 1≤i≤n) 都是无界通配符,或者非受检警告被SuppressWarning注解限制。
非受检转换被用来保证与遗留代码之间的平滑互操作,这些遗留代码是在泛型被引入到 Java之前编写的,并且用到了后来已经转而使用泛型机制(被称为“泛型化”的过程)的类库。在这种情况下(尤其是java.util中的集合框架的用户),遗留代码使用的是原生类型 (例如使用Collection而不是Collection )。原生类型表达式会作为引元传递给某些类库方法,这些方法使用的是原生类型的参数化版本,并将其作为相应的形参的类型。
这种调用在使用泛型的类型系统中无法证明是静态类型安全的,而拒绝这种调用会导致大量的现有代码无效,并且会阻止它们使用类库的新版本,进而会打击类库提供商使用泛型机制的积极性。为了防止这种令人不悦的情况发生,原生类型可以转换为对该原生类型所引用的泛型声明的任意调用。尽管这种转换并不完美,但是它作为一种向实用性的妥协,还是可以接受的。在这种情况下,会产生非受检警告。
捕获转换
假设G是带有n个类型参数 A 1 , … , A n A_{1},…,A_{n} A1,…,An,且其相应的边界为 U 1 , … , U n U_{1},…,U_{n} U1,…,Un的泛型声明,则存在从参数化类型 G < T 1 , … , T n > G
- 如果 T i T_{i} Ti是形式为 ?的通配符类型引元,那么 S i S_{i} Si就是一个全新的类型变量,其上界为 U i [ A i : = S i , … , A n : = S n ] U_{i}[A_{i}:=S_{i}, …,A_{n}:=S_{n}] Ui[Ai:=Si,…,An:=Sn],且其下界为空类型。
- 如果 T i T_{i} Ti是形式为 ?extends B i B_{i} Bi的通配符类型引元,那么 S i S_{i} Si就是一个全新的类型变量,
其上界为glb( B i B_{i} Bi , U i [ A i : = S i , … , A n : = S n ] U_{i}[A_{i}:=S_{i}, …,A_{n}:=S_{n}] Ui[Ai:=Si,…,An:=Sn]),且其下界为空类型。
glb( V 1 V_{1} V1,……, V m V_{m} Vm)被定义为 V 1 V_{1} V1 &…& V m V_{m} Vm。
对于任意两个类(而非接口) V i V_{i} Vi和 V j V_{j} Vj,如果 V i V_{i} Vi不是 V j V_{j} Vj的子类,则这是一种编译时错误,反之亦然。 - 如果 T i T_{i} Ti是形式为 ?super B i B_{i} Bi的通配符类型引元,那么 S i S_{i} Si就是一个全新的类型变量, 其上界为 U i [ A i : = S i , … , A n : = S n ] U_{i}[A_{i}:=S_{i}, …,A_{n}:=S_{n}] Ui[Ai:=Si,…,An:=Sn] ,且其下界为 B i B_{i} Bi。
- 否则, S i S_{i} Si = T i T_{i} Ti。
在除参数化类型之外的其他任意类型上的捕获转换都起到了标识转换的作用。
捕获转换不能被递归地使用。
捕获转换不需要在运行时执行特殊动作,因此也就不会在运行时抛出异常。
设计捕获转换的目的是使通配符更加有用。为了理解这种设计动机,我们先来了解 java.util.Collection.reverse () 方法:
public static void reverse (List<?> list);
这个方法会反转作为参数提供的列表对象,它可以应用于任何类型的列表,因此使用通配符类型List作为形参类型是完全合适的。
现在想想可以怎么实现reverse ():
public static void reverse(List<?> list) { rev(list); }
private static <T> void rev(List<T> list) {
List<T> tmp = new ArrayList<T>(list);
for (int i = 0; i < list.size(); i++) {
list.set(i, tmp.get(list.size() - i - 1));
}
}
这个实现需要复制列表,将元素从副本中抽取出来,并将它们插回到原来的数组中。为了以类型安全的方式实现此目的,我们需要给传递进来的列表的元素类型命名,即T , 在私有的服务方法rev()中我们就是这么做的。这需要我们将类型为List的传递给reverse的引元列表当作引元传递给rev()。 通常,List是未知类型的列表,对于任意类型T来说,它 都不是List的超类型,因为允许这种超类型关系是不妥当的。假如有下面的方法:
public static <T> void fill(List<T> l, T obj)
那么,下面的代码将会损坏类型系统:
List<String> ls = new ArrayList<String>();
List<?> 1 = ls;
Collections.fill(l, new Object()); // not legal - but assume it was!
String s = ls.get(0); // ClassCastExGeption - Is contains
// Objects, not Strings.
这样,毫无例外地,我们可以看到在reverse () 中对rev ()的调用会被禁用。如果情况真是如此,那么不得不将reverse () 的签名写作:
public static <T> void reverse(List<T> list)
这并非我们想要的,因为它将实现的信息暴露给了调用者。更糟的是,API 的设计者可能会认为使用通配符的签名正是API的调用者所需要的,而以后才会意识到类型安全的实现被封杀了。
在reverse ()中调用 rev ()实际上是无害的,但是以List和List之间通常意义上的子类型关系为基础做出判断是不恰当的。这个调用无害是因为传递进来的引元无疑是某种类型(虽然是未知的)的列表。如果我们可以将这种未知类型捕获到类型变量x中,那么 就可以推断T是X。这就是捕获转换的精髓。本规范当然必须处理各种复杂性,例如非平凡的(并且可能是递归定义的)上界和下界,出现多个引元,等等。
精通数学的读者希望能够将捕获转换与已确立的类型理论关联起来,而不熟悉类型理论的读者可以跳过这项讨论,或者先学习合适的背景资料,例如Benjamin Pierce的《Types and Programming Languages》,然后再重读本节内容。
这里先总结一下捕获转换与已确立的类型理论概念之间的关系。通配符类型是既存类型的受限形式。捕获转换大致相当于既存类型的值的开放操作(opening)。表达式e的捕获转换可以看作是包围e的顶层表达式所构成的作用域中e的open操作。
在既存类型上的经典的open操作要求被捕获的类型变量不能转义被开放的表达式。对应于捕获转换的open总是位于足够大的作用域之上,该作用域大到被捕获的类型变量永远都不可能在该作用域之外可见。这种模式的好处在于不需要执行任何close操作,就像在 Atsushi Igarashi 和 Mirko Viroli 在 16th European Conference on Object Oriented Programming (ECOOP 2002 )上发表的论文《On Variance-Based Subtyping for Parametric Type》中所定义的那样。对于通配符的形式化讨论,可以参阅Mads Torgersen、Erik Ernst和Christian Plesner Hansen 在 12th workshop on Foundations of Object Oriented Programming ( FOOL 2005 )上发表的《Wild FJ》。
字符串转换
任意类型都可以通过字符串转换转换成String类型。
简单类型T的值x首先被转换为引用值,即将其作为引元传递给恰当的类实例创建表达式:
- 如果T是boolean,那么就使用new Boolean(x)。
- 如果T是char,那么就使用new Character(x)。
- 如果 T 是 byte、short 或 int,那么就使用 new Integer(x)。
- 如果T是long,那么就使用new Long(x)。
- 如果T是float,那么就使用new Float(x)。
- 如果T是double,那么就使用new Double(x)。
之后,这个引用值通过字符串转换转换为String类型。
现在只需要考虑引用值:
- 如果该引用为null,那么它将转换为字符串"null"(四个ASCII字符n、u、l、l)
- 否则,执行转换,即不传递任何引元而调用被引用对象上的tostring方法;但是如果调用tostring方法的结果是null,那么就用字符串"null"替代。
toString方法是由原始类Object定义的。许多类都覆盖了它,特别是 Boolean、 Character、 Integer、 Long、 Floaty 、Double 和 String。
被禁止的转换
任何不是明确允许的转换都是被禁止的。
值集转换
值集转换是将一个值集中的浮点值映射到另一个值集,但是不改变其类型的过程。
在不是精确浮点的表达式中,值集转换为Java编程语言的实现提供了多项选择:
- 如果要转换的值是浮点扩展指数值集中的元素,那么其实现方式可以是将该值映射为浮点值集中最接近的元素。这种转换可能会产生上溢(此时该值会替换为与其符号 m 相同的无穷大)或下溢(此时该值会丢失精度,因为它会被替换为与其符号相同的非规格化数或0)。
- 如果要转换的值是双精度浮点扩展指数值集中的元素,那么其实现方式可以是将该值映射为双精度浮点值集中最接近的元素。这种转换可能会产生上溢(此时该值会替 换为与其符号相同的无穷大)或下溢(此时该值会丢失精度,因为它会被替换为与其符号相同的非规格化数或0)。
在FP-严格的表达式中,值集转换不提供任何选择,所有实现都必须遵循相同的方式:
- 如果要转换的值是float类型,并且它不是浮点值集中的元素,那么其实现方式必须将该值映射为浮点值集中最接近的元素。这种转换可能会产生上溢或下溢。
- 如果要转换的值是double类型,并且它不是双精度浮点值集中的元素,那么其实现方式必须将该值映射为双精度浮点值集中最接近的元素。这种转换可能会产生上溢或下溢。
在精确浮点表达式中,只有在对声明为不是精确浮点的方法进行调用时,才需要对浮点扩展指数值集或双精度扩展指数值集中的值进行映射,并且其实现可以选择将方法调用的结果表示为扩展指数值集的元素。
无论是在精确浮点的代码还是非精确浮点的代码中,值集转换类型总是会保持既不是float类型,也不是double类型的值不变。
赋值上下文
赋值上下文允许将表达式的值赋值给变量;表达式的类型必须转换成变量的类型。
赋值上下文允许使用下列转换之一:
- 标识转换。
- 拓宽简单类型转换。
- 拓宽引用类型转换。
- 装箱转换,后跟可选的拓宽引用类型转换。
- 拆箱转换,后跟可选的拓宽简单类型转换。
在应用了上述转换之后,如果所产生的类型是原生类型,那么可能会进行非受检转换。
另外,如果表达式是byte、short、char或int类型的常量表达式,那么:
- 如果变量的类型是byte, short或char,并且常量表达式的值是可以用该变量的类型表示的,那么就可以使用窄化简单类型转换。
- 如果变量的类型是下列情形之一,那么就可以使用窄化简单类型转换,后跟装箱转换:
-Byte,并且常量表达式的值可以用byte类型表示。
-Short,并且常量表达式的值可以用short类型表示。
-Character,并且常量表达式的值可以用char类型表示。
常量表达式在编译时的窄化意味着诸如下面的代码:
byte theAnswer = 42;
是允许的。如果没有窄化,那么整数字面常量42的类型为int这个事实,将迫使我们必须将其强制类型转换为byte:
byte theAnswer = (byte)42; // cast is permitted but not required
最后,空类型的值(空引用是唯一的这种值)可以被赋值给任意引用类型,导致产生该类型的一个空引用。
如果转换链中包含两个参数化类型,并且它们之间不存在子类型关系,那么这就是一个编译时错误。
下面是这种非法转换链的一个实例:
Integer, Comparable<Integer>, Comparable, Comparable<String>
这个转换链的前三个元素与拓宽引用类型转换相关,而最后一项是由非受检转换从其前面的转换派生出来的。但是,这并非合法的赋值转换,因为该链条包含两个参数化类型 Comparable 和 Comparable ,它们彼此不是子类型。
如果表达式的类型不能经由在赋值上下文中所允许的类型转换而转换为变量的类型,那 么就会产生编译时错误。
如果表达式的类型可以经由赋值转换被转换为变量的类型,我们就称该表达式(或它的值)是可赋值给该变量的,或者称该表达式的类型与该变量的类型是赋值兼容的。
如果变量的类型是float或double,那么值集转换就会作用于下面的类型转换所产生的结果v上:
- 如果v是float类型,并且是浮点扩展指数值集的元素,那么Java语言的实现必须将v映射为浮点值集中最接近的元素。这种转换可能会产生上溢或下溢。
- 如果v是double类型,并且是双精度浮点扩展指数值集的元素,那么Java语言的实现必须将v映射为双精度值集中最接近的元素。这种转换可能会产生上溢或下溢。
赋值转换可能会产生下列异常:
- ClassCastException,如果在应用上述转换后所产生的值是对象,但是它不是待赋值的变量的类型的擦除的子类或子接口的实例,那么就会产生该异常。
这种情况只有在堆污染时才会发生。在实践中,Java语言的实现只有在访问参教化类型的对象的域或方法时,当被访问域的擦除类型或被访问方法的擦除结果类型与它们的未擦除类型不同时,才需要执行强制类型转换。 - OutOfMemoryError,在装箱转换时有可能会发生。
- NullPointerException,在空引用上进行拆箱转换时会发生。
- ArrayStoreException,在涉及数组元素或域访问的特例中有可能会发生。
简单类型的赋值转换
class Test {
public static void main(String[] args) {
short s = 12; // narrow 12 to short
float f = s; // widen short to float
System.out.println("f=" + f);
char c = '\u0123';
long 1 = c; // widen char to Long
System.out.priritln("l=0x" + Long.toString (1,16));
f = 1.23f;
double d = f; // widen float to double
System.out.println ("d=" + d);
运行该程序会产生如下输出:
f=12.0
1=0x123
d=l.2300000190734863
但是下面的程序却会产生编译时错误:
class Test {
public static void main(String[] args) {
short s = 123;
char c = s; // error: would require cast
s = c; // error: would require cast
).
)
因为并非所有short值都是char值,同样并非所有char值都是short值。
引用类型的赋值转换
class Point{ int x, y; }
class Point3D extends Point { int z; }
interface Colorable { void setColor(int color); }
class ColoredPoint extends Point implements Colorable {
int color;
public void setColor(int color) { this.color = color; }
}
class Test {
public static void main(String[] args){
// Assignments to variables of class type:
Point p = new Point();
p = new Point3D();
// OK because Point3D is a subclass of Point
Point3D p3d = p;
// Error: will require a cast because a Point
// might not be a Point3D (even though it is,
// dynamically, in this example,)
// Assignments to variables of type Object:
Object o = p; // OK: any object to pbject
int[] a = new int[3];
Object o2 = a; // OK: an array to Object
// Assignments to variables of interface type:
ColoredPoint cp = new ColoredPoint();
Colorable c = cp;
// OK: ColoredPoint implements Colorable
// Assignments to variables of array type:
byte[] b = new byte[4];
a = b;
// Error: these are not arrays of the same primitive type
Point3D[] p3da = new Point3D[3];
Point[] pa = p3da;
// OK: since we can assign a Point3D to a Point
p3da = pa;
// Error: (cast needed) since a Point
// can't be assigned to a Point3D
}
}
下面的测试程序解释了在引用值上进行的赋值转换,但是它不能编译,原因在注释中进行了阐述。可以将这个示例与上面的例子进行对比。
class Point { int x, y; }
interface Colorable { void setColor(int color); }
class ColoredPoint extends Point implements Colorable {
int color;
public void setColor(int color) { this.color = color; }
}
class Test {
public static void main(String[] args) {
Point p = new Point();
ColoredPoint cp = new ColoredPoint();
// Okay because ColoredPoint is a subclass of Point:
p = cp;
// Okay because ColoredPoint implements Colorable:
Colorable c = cp;
// The following cause compile-time errors because
// we cannot be sure they will succeed, depending on
// the run-time type of p; a run-time check will be
// necessary for the needed narrowing conversion and
// must be indicated by including a cast:
cp = p; // p might be neither a ColoredPoint
// nor a subclass of ColoredPoint
c = p; // p might not implement Colorable
}
}
数组类型的赋值转换
class Point{ int x, y; }
class ColoredPoint extends Point { int color; }
class Test {
public static void main(String[] args) {
long[] veclong = new long[100];
Object o = veclong; // okay
Long l = veclong; // compile-time error
short[] vecshort = veclong; // compile-time error
Point[] pvec = new Point[100];
ColoredPoint[] cpvec = new ColoredPoint[100];
pvec = cpvec; // okay
pvec[0] = new Point(); // okay at compile time,
// but would throw an
// exception at run time
cpvec =pvec; // compile-time error
在上面的例子中:
- veclong的值不能赋值给一个Long变量,因为Long是类类型,而不是Object类型。数组只能赋值给兼容的数组类型的变量,或Object、Cloneable或java.io.Serializable 类型的变量。
- veclong的值不能赋值给vecshort,因为它们是简单类型的数组,并且short和long不是相同的简单类型。
- cpvec可以赋值给pvec, 因为对于任意引用,如果它可以是ColoredPoint类型的表达式的值,那么就可以是Point类型的变量的值。随后将新的Point赋值给pvec元素的语句会抛出ArrayStoreException异常(假设该程序经过修正,能够通过编译),因为ColoredPoint数组不能将一个Point实例作为其元素的值。
- pvec的值不能赋给cpvec ,因为对于所有可以是ColoredPoint类型的表达式的值的引用,并非都可以是正确的Point类型的变量的值。如果pvec的值在运行时是对 Point[]实例的引用,并且将其赋值给cpvec是允许的,那么对cpvec的元素的直接引用,例如cpvec[0],就可以返回一个Point,而Point并非ColoredPoint。因此, 如果允许这样的赋值,那么就是允许对类型系统的违例。可以使用强制类型转换来确保pvec引用的是ColoredPoint():
cpvec = (ColoredPoint.[] ) pvec; // OK, but may throw an
// exception at run time
方法调用上下文
方法调用上下文将方法调用或构造器调用中的引元值赋值给对应的形参。
严格的调用上下文允许使用下列转换:
- 标识转换。
- 拓宽简单类型转换。
- 拓宽引用类型转换。
宽松的调用上下文允许使用更多的转换,因为对于使用它们的特定调用,是无法使用严 格的调用上下文来找到可应用的任何声明的。宽松的调用上下文允许使用下列转换:
- 标识转换。
- 拓宽简单类型转换。
- 拓宽引用类型转换。
- 装箱转换,后跟可选的拓宽引用类型转换。
- 拆箱转换,后跟可选的拓宽简单类型转换。
在应用了上述用于调用上下文的转换之后,如果所产生的类型是原生类型, 那么就可能会进行非受检转换。
空类型的值(空引用是唯一的这种值)可以赋值给任意引用类型。
如果转换链中包含两个参数化类型,并且它们之间不存在子类型关系,那么这就是一个编译时错误。
如果表达式的类型不能通过宽松的调用上下文中所允许的类型转换而被转换为参数的类型,那么就会产生编译时错误。
如果引元表达式的类型是float或double,那么就会在类型转换之后应用值集转换:
- 如果要转换的float类型的引元值是浮点扩展指数值集中的元素,那么其实现方式必须将该值映射为浮点值集中最接近的元素。这种转换可能会产生上溢或下溢。
- 如果要转换的double类型的引元值是双精度浮点扩展指数值集中的元素,那么其实现方式必须将该值映射为双精度浮点值集中最接近的元素。这种转换可能会产生上溢或下溢。
调用上下文可能会抛出的异常包括:
- ClassCastException,如果在应用上述类型转换后所产生的值是对象,但是它不是对 应的形参类型的擦除的子类或子接口的实例,那么就会产生该异常。
- OutOfMemoryError,在装箱转换时有可能会发生。
- NullPointerException ,在空引用上进行拆箱转换时会发生。
特别地,无论是严格的调用上下文还是宽松的调用上下文,都不包括在赋值上下文中所允许的隐式整数常量表达式窄化转换。Java编程语言的设计者们认为包含这类隐式窄化转换 将会对重载方法的匹配解析规则带来额外的复杂性。
因此,下面的程序:
class Test {
static int m(byte a, int b) { return a+b; }
static int m(short a, short b) { return a-b; }
public static void main(String[] args) {
System.out.println(m(12r 2)); // compile-time error
}
}
将会导致编译时错误,因为整数字面常量12和2都是int类型,因此无论是哪个m方法在重载解析规则之下都不能匹配。包含隐式整数常量窄化转换的语言都需要添加额外的规则来解决像这个示例这样的情况。
字符串上下文
字符串上下文只能应用于二元操作符+的两个操作数之一,该操作数不是String,但另一个操作数是String。
在这些上下文中,目标类型总是String,并且非String操作数的String转换总是会发生,然后+操作符会按照第15.18.1节中指定的方式进行计算。
强制类型转换上下文
强制类型转换上下文允许强制类型转换操作符的操作数被转换为强制类型转换操作符显式指定的类型。
强制类型转换上下文允许使用下列转换:
- 标识转换。
- 拓宽简单类型转换。
- 窄化简单类型转换。
- 拓宽和窄化简单类型转换。
- 拓宽引用类型转换,后跟可选的拆箱转换或非受检转换。
- 窄化引用类型转换,后跟可选的拆箱转换或非受检转换。
- 装箱转换,后跟可选的拓宽引用类型转换。
- 拆箱转换,后跟可选的拓宽简单类型转换。
在该类型转换之后可以应用值集转换。
强制类型转换的编译时合法性允许下列情况:
- 对简单类型表达式,可以经由标识转换(如果类型相同)、拓宽简单类型转换、窄化简单类型转换,或拓宽和窄化简单类型转换来实现它到其他简单类型的强制类型转换。
- 对简单类型表达式,可以经由装箱转换来实现它到引用类型的强制类型转换。
- 对引用类型表达式,可以经由拆箱转换来实现它到简单类型的强制类型转换。
- 对引用类型表达式可以实施到其他引用类型的强制类型转换,但必须符合第5.5.1节给出的规则,且没有产生任何编译时错误。
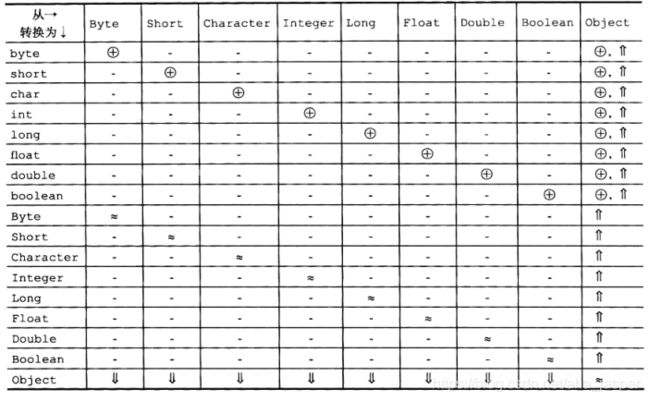
表5-1和表5-2枚举了在给定的强制类型转换中使用到的转换,其中,每种转换用一个符号来表示:
- -表示不允许任何强制类型转换
- 表示标识转换
- 表示拓宽简单类型转换
- 表示窄化简单类型转换
- 表示拓宽和窄化简单类型转换
- 表示拓宽引用类型转换
- 表示窄化引用类型转换
- 表示装箱转换
- 表示拆箱转换
在表中,符号中间的逗号表示强制类型转换可以使用某种转换,后面跟着另外一种转换。Object 类型表示除了 8 种包装器类型 Boolean、Byte、Short、Character、 Integer、 Long、Float 和 Double之外的任意引用类型。
表5-1到简单类型的强制类型转换
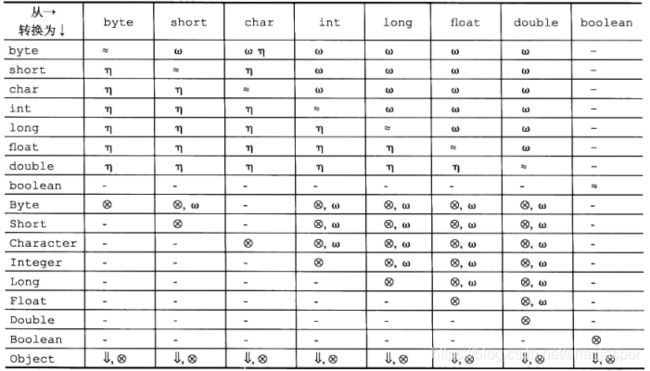
表5-2到引用类型的强制类型转换
引用类型强制类型转换
给定编译时引用类型S (源)和T (目标),如果在下列规则中不会产生任何编译时错误, 那么就存在从S到T的强制类型转换。
如果S是类类型:
- 如果T是类类型,那么要么|S| <: |T|,要么|T| <: |S|,否则,就会产生编译时错误。
而且,如果T有超类型X, S有超类型Y,且X和Y都是可证不同的参数化类型,而X和Y的擦除又是相同的,那么就会产生编译时错误。
- 如果T是接口类型:
■如果S不是final类,那么如果T有超类型X, S有超类型Y,且X和Y都是可证不同的参数化类型,而X和Y的擦除又是相同的,那么就会产生编译时错误。
否则,这种强制类型转换在编译时总是合法的(因为即使S没有实现T, S的某个子类也可能会实现T)。
■如果S是final类,那么S必须实现T,否则会产生编译时错误。 - 如果T是类型变量,那么通过用T的上界来替换T,可以递归地应用这个算法。
- 如果T是数组类型,那么S必须是Object类,否则会产生编译时错误。
- 如果T是交集类型 T 1 T_{1} T1&…& T n T_{n} Tn,若存在某个 T i T_{i} Ti( 1 ≤ i ≤ n 1\leq i \leq n 1≤i≤n), 使得S不能通过这个算法被强制类型转换为 T i T_{i} Ti那么就是一个编译时错误。即,强制类型转换成功与否是由交集类型最严苛的组成部分所决定的。
如果S是接口类型:
- 如果T是数组类型,那么S必须是java.io.Serializable类型或Cloneable类型(仅由数组实现的接口),否则会产生编译时错误。
- 如果T是非final的类或接口类型,那么如果T有超类型X, S有超类型 Y,且X和Y都是可证不同的参数化类型,而X和Y的擦除又是相同的,那么就会产生编译时错误。
否则,这种强制类型转换在编译时总是合法的(因为即使S没有实现T, S的某个子类也可能会实现T)。 - 如果T是final的类类型,那么:
■ 如果S不是参数化类型或原生类型,那么T必须实现S,否则会产生编译时错误。
■ 如果S是参数化类型或原生类型,那么S要么是对某个泛型声明G的调用而产生的参数化类型,要么是相应的泛型声明G的原生类型,这样就必然存在T的超类型X,使得X是G的一个调用,否则会产生编译时错误。
而且,如果S和X是可证不同的参数化类型,那么就会产生编译时错误。 - 如果T是类型变量,那么通过用T的上界来替换T,可以递归地应用这个算法。
- 如果T是交集类型 T 1 T_{1} T1&…& T n T_{n} Tn,若存在某个 T i T_{i} Ti( 1 ≤ i ≤ n 1\leq i \leq n 1≤i≤n)使得S不能通过这个算法被强制类型转换为 T i T_{i} Ti,那么就是一个编译时错误。
如果S是类型变量,那么通过用S的上界来替换S,可以递归地应用这个算法。
如果S是交集类型 A 1 A_{1} A1&…& A n A_{n} An, 若存在某个 A i A_{i} Ai( 1 ≤ i ≤ n 1\leq i \leq n 1≤i≤n),使得 A i A_{i} Ai不能通过这个算法被强制类型转换为T,那么就是一个编译时错误。即,强制类型转换成功与否是由交集类型最严苛组成部分所决定的。
如果S是数组类型SC[],即由sc类型的元素构成的数组:
- 如果T是类类型,那么如果T不是Object,那么就会产生编译时错误(因为Object 是唯一的可以将数组赋值给它的类类型)。
- 如果T是接口类型,那么除非T是java.io.Serializable或Cloneable类型(仅由数 组实现的接口),否则就会产生编译时错误。
- 如果T是类型变量,那么通过用T的上界来替换T,可以递归地应用这个算法。
- 如果T是数组类型TC[],即由TC类型的元素构成的数组,那么除非下列情况有一种为真,否则就会产生编译时错误:
■ TC和SC是相同的简单类型。
■ TC和SC都是引用类型,并且SC类型可以经过强制类型转换而转换成TC。 - 如果T是交集类型 T 1 T_{1} T1&…& T n T_{n} Tn,那么如果存在某个 T i T_{i} Ti( 1 ≤ i ≤ n 1\leq i \leq n 1≤i≤n),使得S不能通过这 个算法被强制类型转换为 T i T_{i} Ti,那么就是一个编译时错误。
引用类型的强制类型转换
class Point { int x, y; }
interface Colorable { void setColor(int color); }
class ColoredPoint extends Point implements Colorable {
int color;
public void setColor(int color) { this.color = color; }
}
final class EndPoint extends Point {}
class Test (
public static void main(String[] args) {
Point p = new Point();
ColoredPoint cp = new ColoredPoint();
Colorable c;
// The following may cause errors at run time because
// we cannot be sure they will succeed; this possibility
// is suggested by the casts:
cp = (ColoredPoint)p;
c = (Colorable)p;
// The following are incorrect at compile time because
// they can never succeed as explained in the text:
Long l = (Long)p; // compile-time error #1
EndPoint e = new EndPoint();
c = (Colorable)e; // compile-time error #2
}
}
这里,第一个编译时错误是因为类类型Long和Point是不相关的(即,它们并不相同, 并且互相之间没有子类关系),因此它们之间的强制类型转换总是失败。
第二个编译时错误是因为EndPoint类型的变量不能引用实现了 Colorable接口的值, 因为EndPoint是final类型,而final类型的变量总是持有运行时类型和编译时类型相同的值。因此,变量e的运行时类型必须精确地是EndPoint类型,而EndPoint类型没有实现Colorable。
数组类型的强制类型转换
class Point{
int x, y;
Point(int x, int y) { this.x = x; this.y = y; }
public String toString() { return "(" + x + "," + y + ")"; }
}
interface Colorable { void setColor(int color); }
class ColoredPoint extends Point implements Colorable {
int color;
ColoredPoint(int x, int y, int color) {
super(x, y); setColor(color);
}
public void setColor(int color) {
this.color = color;
}
public String toString() {
return super. toString () + "@" + color;
}
}
class Test {
public static void main(String[] args) {
Point[) pa = new ColoredPoint[4];
pa[0] = new ColoredPoint(2, 2, 12);
pa[1] = new ColoredPoint(4, 5, 24);
ColoredPoint[] cpa = (ColoredPoint[])pa;
System.out.print("cpa: {");
for (int i = 0; i < cpa.length; i++)
System.out.print((i == 0 ? " " : ", ") + cpa[i]);
System.out.printin(" }");
这个程序不会产生任何编译时错误,并且会产生如下输出:
cpa: { (2,2)@12, (4,5)@24, null, null )
受检强制类型转换和非受检强制类型转换
当且仅当S <: T 时,从类型S到类型T的强制类型转换是静态可知正确的。
从类型S到参数化类型T的强制类型转换是非受检的,除非下面的条件至少满足一条:
- S <: T
- T的所有类型引元都是无界通配符。
- T <: S,并且对于S除T之外的任何子类型X,不存在X的类型引元未包含在T的类型引元中的情况。
从类型S到类型变量T的强制类型转换是非受检的,除非S<:T。
如果存在某个 T i T_{i} Ti( 1 ≤ i ≤ n 1\leq i \leq n 1≤i≤n),使得从S到 T i T_{i} Ti的强制类型转换是非受检的,那么从类型 S到交集类型 T 1 T_{1} T1&…& T n T_{n} Tn的强制类型转换就是非受检的。
如果从|S|到|T|的强制类型转换是静态可知正确的,那么从S到非交集类型T的非受检强制类型转换是完全非受检的,否则,这种类型转换就是部分非受检的。
如果对于所有 i ( 1 ≤ i ≤ n 1\leq i \leq n 1≤i≤n) , 从S到 T i T_{i} Ti的强制类型转换要么是静态可知正确的,要么是完全非受检的,那么从类型S到交集类型 T 1 T_{1} T1&…& T n T_{n} Tn的强制类型转换就是完全非受检的。 否则,这种类型转换就是部分非受检的。
非受检强制类型转换会产生编译时非受检警告,除非用Suppresswarnings注解进行了压制。
如果某个强制类型转换不是静态可知正确的,并且不是非受检的,那么它就是受检的。 如果某个到引用类型的强制类型转换不产生编译时错误,那么它必是以下几种情况之一:
- 该强制类型转换是静态可知正确的。
对这种强制类型转换不需要执行任何运行时动作。 - 该强制类型转换是完全非受检强制转型。
对这种强制类型转换不需要执行任何运行时动作。 - 该强制类型转换是部分非受检或受检的到交集类型的强制类型转换。
其中交集类型为 T 1 T_{1} T1&…& T n T_{n} Tn, 对于所有的 i ( 1 ≤ i ≤ n 1\leq i \leq n 1≤i≤n) 任何从S到 T i T_{i} Ti的强制类型转换所必需的运行时检查,对于强制类型转换到该交集类型也是必需的。 - 该强制类型转换是到非交集类型的部分非受检强制类型转换。
这种强制类型转换要求在运行时进行有效性检查。这项检查执行时就像是该强制类型 转换是|S|和|T|之间的受检强制类型转换一样,就像下面将要描述的那样。 - 该强制类型转换是到非交集类型的受检强制类型转换。
这种强制类型转换要求进行运行时有效性检查。如果被类型转换的值在运行时是 null,那么该强制类型转换是允许的。否则,设R是运行时引用值所引用的对象的类,T是在强制类型转换操作符中命名的类型的擦除,那么该强制类型转换必须在运行时通过第5.5.3节中描述的算法检查类R与类型T之间的赋值兼容性。
注意 当上述规则首次应用于任意给定的强制类型转换时,R不能是接口,但是如果这些规则后续进行递归地应用,那么R就可以是接口,因为运行时的引用值可以引用元素类型是接口类型的数组。
运行时的受检强制类型转换
下面的算法用于检查某个对象的运行时类型R是否与在强制类型转换操作符中命名的类型的擦除具有赋值兼容性。如果该检查会抛出运行时异常,那么应该是 ClassCastException。
如果R是普通类(不是数组类):
- 如果T是类类型,那么R必须要么是与T相同的类,要么是T的子类, 否则会抛出运行时异常。
- 如果T是接口类型,那么R必须实现接口 T,否则会抛出运行时异常。
- 如果T是数组类型,那么会抛出运行时异常。
如果R是接口:
- 如果T是类类型,那么T必须是Object,否则会抛出运行时异常。
- 如果T是接口类型,那么R必须要么是与T相同的接口,要么是T的子接口,否则会抛出运行时异常。
- 如果T是数组类型,那么会抛出运行时异常。
如果R是表示数组类型RC[ ] 的类,即由RC类型的元素构成的数组:
- 如果T是类类型,那么T必须是Object,否则会抛出运行时异常。
- 如果T是接口类型,那么除非T是java.io.Serializable或Cloneable类型(仅有的由数组实现的接口),否则会抛出运行时异常。
这种情况可能会悄然跳过编译时检查,例如,存储在Oktject类型的变量中的对数组的引用。 - 如果T是数组类型TC[ ],即由TC类型的元素构成的数组,那么除非下列情况有一种为真,否则会抛出运行时异常:
■ TC和RC是相同的简单类型。
■ TC和RC都是引用类型,并且RC类型可以通过递归地应用针对强制类型转换的运行时规则,经过强制类型转换而转换成TC。
运行时不兼容的类型
class Point { int x, y; }
interface Colorable { void setcolor(int color); }
class ColoredPoint extends Point implements Colorable {
int color;
public void setcolor(int color) { this.color = color; }
}
class Test {
public static void main(String[] args) {
Point[] pa = new Paint.[100];
// The following line will throw a CLassCastException:
ColoredPoint[] cpa =(ColoredPoint[])pa;
System.out.printin(cpa[0]);
int[] shortvec = new int[2];
Object o = shortvec;
// The following line will throw a ClassCastException:
Colorable c = (Colorable)o;
c.setColor(0);
}
}
这个程序使用了强制类型转换,可以通过编译,但是它会在运行时抛出异常,因为要类型转换的类型之间不兼容。
数字上下文
数字上下文可以应用于算术操作符的操作数。
数字上下文允许使用下列转换之一:
- 标识转换。
- 拓宽简单类型转换。
- 拆箱转换,后面可选地跟着扩宽简单类型转换。
数字提升的处理过程如下:给定算术操作符及其引元表达式,其引元会被转换为推断出来的目标类型T。T是在提升过程中确定的,它使得每个引元表达式都可以被转换为T,并且该算术操作就是针对T类型的值而定义的。
有两种数字提升:一元数字提升和二元数字提升。
一元数字提升
某些操作符会将一元数字提升应用于单个操作数,而应用的结果必须产生一个数字类型的值:
- 如果该操作数的编译时类型为Byte、Short、Character或Integer,那么它会接受拆箱转换。转换的结果之后通过拓宽简单类型转换或标识转换被提升为int类型的值。
- 如果该操作数的编译时类型为Long、Float或Double,那么它会接受拆箱转换。
- 如果该操作数的编译时类型为byte、short或char,那么它会通过拓宽简单类型转换被提升为int类型的值。
- 否则,一元数字操作数会保持原样而不进行转换。
在上述转换之后,如果需要,还可以应用值集转换。
一元数字提升是在属于下列情况的表达式上执行的:
- 数组创建表达式中的每一维表达式。
- 数组访问表达式中的索引表达式。
- 一元加号操作符+ 的操作数。
- 一元减号操作符-的操作数。
- 按位取反操作符~ 的操作数。
- 移位操作符>>、>>>和<<对应的操作数。
- long类型的移位距离(右操作数)不会导致被移位的值(左操作数)被提升到long。
一元数字提升
class Test {
public static void main(String[] args) {
byte b = 2;
int a[] = new int[b]; // dimension expression promotion
char c = '\u0001';
a[c] = 1; // index expression promotion
a[0] = -c; // unary 一 promotion
System.out.println("a: " + a[0] + "," + a[1]);
b = -1;
int i = ~b; // bitwise complement promotion
System.out.println("~Ox" + Integer.toHexString(b) + "==0x" + Integer.toHexString(i));
i = b << 4L; // shift promotion (left operand)
System.out.println("0x" + Integer.toHexString(b) + "<<4L=0x" + Integer.toHexString(i));
}
}
这个程序将产生如下输出:
a: -1,1
-Oxffffffff==OxO
Oxffffffff<<4L==0xfffffff0
二元数字提升
如果一个操作符将二元数字提升应用于一对操作数,其中每个操作数表示的都必须是能够转换成某种数字类型的值,那么就会依次应用下面的规则:
1 )如果任意一个操作数是引用类型,那么它会接受拆箱转换。
2)拓宽简单类型转换按照下面指定的规则转换其中一个操作数或同时转换两个操作数:
- 如果任意一个操作数是double类型,那么另一个就被转换为double。
- 否则,如果任意一个操作数是float类型,那么另一个就被转换为float。
- 否则,如果任意一个操作数是long类型,那么另一个就被转换为long。
- 否则,两个操作数都被转换为int类型。
在类型转换之后,如果需要,那么值集转换可以应用于每个操作数。
二元数字提升是在特定操作符的操作数上执行的:
- 乘除操作符* 、/ 和%
- 用于数字类型的加法和减法操作符+和-
- 数字比较操作符<、<=、> 和 >=
- 数字判等操作符==和!=
- 整数位操作符 &、^ 和 I
- 在特定情况下的条件操作符 ?:
二元数字提升
class Test {
public static void main(String[] args) {
int i = 0;
float f = 1.Of;
double d = 2.0;
// First int*float is promoted to float*float, then
// float==double is promoted to double==double:
if (i * f == d) System.out.println("oops");
// A char&byte is promoted to int&int:
byte b = Ox1f;
char c = 'G';
int control = c & b;
System.out.println(Integer.toHexString(control));
// Here int:float is promoted to float:float:
f = (b==0) ? i : 4.Of;
System.out.println(1.0/f) ;
这个程序将产生如下输出: fl26l
7
0.25
这个示例将ASCII字符G转换成了 ASCII控制字符control-G ( BEL), 方法是屏蔽除该字符的低5位之外的其他所有位。7是这个控制字符的数值。