概述
在大部分的行业系统或者功能性需求中,对于程序员来说,接触到io的机会还是比较少的,其中大多也是简单的上传下载、读写文件等简单运用。最近工作中都是网络通信相关的应用,接触io、nio等比较多,所以尝试着深入学习并且描述下来。
io往往是我们忽略但是却又非常重要的部分,在这个讲究人机交互体验的年代,io问题渐渐成了核心问题。Java传统的io是基于流的io,从jdk1.4开始提供基于块的io,即nio,会在后面的文章介绍。
流
流的概念可能比较抽象,可以想象一下水流的样子。
io在本质上是单个字节的移动,而流可以说是字节移动的载体和方式,它不停的向目标处移动数据,我们要做的就是根据流的方向从流中读取数据或者向流中写入数据。
想象下倒水的场景:倒一杯水,水是连成一片往地上流动,而不是等杯中的水全部倒出悬浮在空中,然后一起掉落地面。最简单的Java流的例子就是下载电影,肯定不是等电影全部下载在内存中再保存到磁盘上,本质上是下载一个字节就保存一个字节。
一个流,必有源和目标,它们可以是计算机内存的某些区域,也可以是磁盘文件,甚至可以是Internet上的某个URL。流的方向是重要的,根据流的方向,流可分为两类:输入流和输出流。我们从输入流读取数据,向输出流写入数据。
io分类
Java对io的支持主要集中在io包下,显然可以分为下面两类:
- 基于字节操作的io接口:InputStream 和 OutputStream
- 基于字符操作的io接口:Writer 和 Reader
不管磁盘还是网络传输,最小的存储单位都是字节。但是程序中操作的数据大多都是字符形式的,所以Java也提供了字符型的流。io包下的类主要提供了io流本身的支持:流的形态,流里装的是什么。但是流并不等于io,还有很重要的一点:数据的传输方式,也就是数据写到哪里的问题,主要是以下两种:
- 基于磁盘操作的io接口:File
- 基于网络操作的io接口:Socket
对此Java的其他一些类库提供了支持。
字节流、字符流的io接口说明
字节流包括输入流InputStream和输出流OutputStream。字符流包括输入流Reader,
InputStream相关类图如下,只列举了一级子类:

InputStream提供了一些read方法供子类继承,用来读取字节。
OutputStream相关类图如下:

OutputStream提供了一些write方法供子类继承,用来写入字节。
Reader相关类图如下:

Reader提供了一些read方法供子类继承,用来读取字符。
Writer相关类图如下:

Writer提供了一些write方法供子类继承,用来写入字符。
每个字符流子类几乎都会有一个相对应的字节流子类,两者功能一样,差别只是在于操作的是字节还是字符。例如CharArrayReader和 ByteArrayInputStream,两者都是在内存中建立数组缓冲区作为输入流,不同的只是前者数组用来存放字符,每次从数组中读取一个字符;后 者则是针对字节。
| ByteArrayInputStream、CharArrayReader | 为多线程的通信提供缓冲区操作功能。常用于读取网络中的定长数据包 |
| ByteArrayOutputStream、CharArrayWriter | 为多线程的通信提供缓冲区操作功能。常用于接收足够长度的数据后进行一次性写入 |
| FileInputStream、FileReader | 把文件写入内存作为输入流,实现对文件的读取操作 |
| FileOutputStream、FileWriter | 把内存中的数据作为输出流写入文件,实现对文件的写操作 |
| StringReader | 读取String的内容作为输入流 |
| StringWriter | 将数据写入一个String |
| SequenceInputStream | 将多个输入流中的数据合并为一个数据流 |
| PipedInputStream、PipedReader、PipedOutputStream、PipedWriter | 管道流,主要用于2个线程之间传递数据 |
| ObjectInputStream | 读取对象数据作为输入流,对象中的 transient 和 static 类型的成员变量不会被读取或写入 |
| ObjectOutputStream | 将数据写入对象 |
| FilterInputStream、FilterOutputStream、FilterReader、FilterWriter | 过滤流通常源和目标是其他的输入输出流,大家可以看到有众多的子类,各有用途,就不一一介绍了 |
字节流和字符流转换
任何数据的持久化和网络传输都是以字节形式进行的,所以字节流和字符流之间必然存在转换问题。字符转字节是编码过程,字节转字符是解码过程。io包中提供了InputStreamReader和OutputStreamWriter用于字符和字节的转换。
来看一个小例子:
char[] charArr = new char[1];
StringBuffer sb = new StringBuffer();
FileReader fr = new FileReader("test.txt");
while(fr.read(charArr) != -1)
{
sb.append(charArr);
}
System.out.println("编码:" + fr.getEncoding());
System.out.println("文件内容:" + sb.toString());
FileReader类其实就是简单的包装一下FileInputStream,但是它继承InputStreamReader类,当调用read方法时其实调用的是StreamDecoder类的read方法,这个StreamDecoder正是完成字节到字符的解码的实现类。如下图:

InputStream 到 Reader 的过程要指定编码字符集,否则将采用操作系统默认字符集,很可能会出现乱码问题。上例代码输出如下:
编码:UTF8
文件内容:hello�����Dz����ļ�!
再来看一个例子,换一个字符集:
char[] charArr = new char[1]; StringBuffer sb = new StringBuffer(); //设置编码 InputStreamReader isr = new InputStreamReader( new FileInputStream("D:/test.txt") , "GBK"); while(isr.read(charArr) != -1) { sb.append(charArr); } System.out.println("编码:" + isr.getEncoding()); System.out.println("文件内容:" + sb.toString());
输出正常:
编码:GBK
文件内容:hello!我是测试文件!
编码过程也是类似的,就不再说了。
io包与设计模式
对于io包,下面的用法是经常看到的:
InputStream in = new BufferedInputStream(new ObjectInputStream(new FileInputStream(new File("xxx"))));
很自然的想到了Decorator(装饰器)模式,Java的io包属于Decorator模式的经典案例。GOF对于Decorator的适用性是这么描述的:
- 在不影响其他对象的情况下,以动态、透明的方式给单个对象添加职责。
- 处理那些可以撤销的职责。
- 当不能采用生成子类的方法进行扩充时。一种情况是,可能有大量独立的扩展,为支持每一种组合将产生大量的子类,使得子类数据呈爆炸性增长。另一种情况可能是因为类定义被隐藏,或类定义被隐藏,或类定义不能生成子类。
以InputStream为例。假设这么一种情况:现在只有InputStream类,需要根据需求设计它的子类。
需求1:读取某个文件到内存中的一个缓冲区的流
需求2:读取某个文件并提供行计数器的流
需求3:读取某个文件并反序列化为对象的流
理所应当,我们建立3个子类:FileBufferedInputStream、FileLineNumberInputStream、FileObjectInputStream。但是如果再来N个这样的需求,那么类图将会变为下图这样:

出现了“类爆炸”的情况,java显然没有这样做,以InputStream为例,实际情况如下图:

对应Decorator模式的类图,InputStream的角色是Component,它主要定义了read抽象方法;FileInputStream、ByteArrayInputStream、ObjectInputStream、PipedInputStream、 SequenceInputStream的角色是ConcreteComponent,它们都是具有某种功能的流。其中前四者,它们的源是byte数组、或者String对象、或者文件等,可以看作是真正的数据来源,被称作原始流。
FilterInputStream类即是Decorator模式中的Decorator角色,装饰器,部分代码如下:
protected volatile InputStream in; protected FilterInputStream(InputStream in) { this.in = in; }
它派生出的多个子类即是ConcreteDecorator,用来给输入流加上不同的功能。它们的源通常都是其他的输入流,所以也叫它们链接流。
那么java为什么要这么设计呢?前面说的“类爆炸”是一个原因;另外通过子类来扩展基类功能是静态的,而装饰器模式是动态的添加组合功能,使用中非常灵活,并且减少了大量的功能重复。
另一种在io包中普遍存在的设计模式是Adapter(适配器)模式,以InputStream子类FileInputStream为例,部分代码如下:
/* File Descriptor - handle to the open file */ private FileDescriptor fd; public FileInputStream(File file) throws FileNotFoundException { ... fd = new FileDescriptor(); ... }
在FileInputStream继承了InputStrem类型,同时持有一个对FileDiscriptor的引用。这是将一个FileDiscriptor对象适配成InputStrem类型的对象形式的适配器模式。如下图:

其他例子就不多说了。
磁盘IO工作机制
io中数据写到何处也是重要的一点,其中最主要的就是将数据持久化到磁盘。数据在磁盘上最小的描述就是文件,上层应用对磁盘的读和写都是针对文件而言的。在java中,以File类来表示文件,如:
File file = new File("D:/test.txt");
但是严格来说,File并不表示一个真实的存在于磁盘上的文件。就像上面代码的文件其实并不存在,File做的只是根据你所提供的文件描述符,返回某一路径的虚拟对象,它并不关心文件或路径是否存在,可能存在,也可能是捏造的。就好象一张名片,名片的背后代表的是人。为什么要这么设计?在我看来还是要提高访问磁盘的效率,有点延迟加载的意思。大部分情况下,我们最关心的并不是文件存不存在,而是文件要如何操作。比如你手里有很多名片,你可能更关心的是有没有某某局长的名片,而只有在需要联系时,才发现名片是假的。也就是关心名片本身要强过名片的真伪。
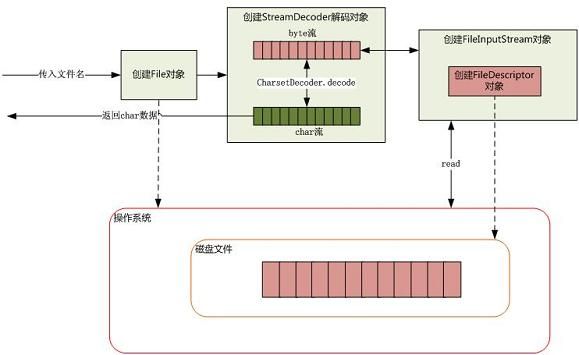
以FileInputStream读取文件为例,过程是这样的:当传入一个文件路径时,会根据这个路径创建File对象,作为这个文件的一个“名片”。当我们试图通过FileInputStream对象去操作文件的时候,将会真正创建一个关联真实存在的磁盘文件的文件描述符FileDescriptor,通过FileInputStream构造方法可以看出:
fd = new FileDescriptor();
如果说File是文件的名片,那么FileDescriptor就是真正指向了一个打开的文件,可以操作磁盘文件。例如FileDescriptor.sync()方法可以将缓存中的数据强制刷新到磁盘文件中。如果我们需要读取的是字符,还需要通过StreamDecoder类将字节解码成字符。至于如何从物理磁盘上读取数据,那就是操作系统做的事情了。过程如图(图摘自网上):
Socket工作机制
Socket要说起来并不那么形象,它的中文翻译是“插座”,至于“套接字”这个翻译我实在不知道从何而来。可以这样理解插座的概念,由于本身有电网的存在,如果我们买了一台新电器,我们只要插上插座连接到电网上就能够使用。Socket就像一个插座,计算机通过Socket就能和网络或者其他计算机上进行通讯;当有数据通讯的需求时,只需要建立一个Socket“插座”,通过网卡与其他计算机相连获取数据。
Socket位于传输层和应用层之间,向应用层统一提供编程接口,应用层不必知道传输层的协议细节。Java中对Socket的支持主要是以下两种:
(1)基于TCP的Socket:提供给应用层可靠的流式数据服务,使用TCP的Socket应用程序协议:BGP,HTTP,FTP,TELNET等。优点:基于数据传输的可靠性。
(2)基于UDP的Socket:适用于数据传输可靠性要求不高的场合。基于UDP的Socket应用程序协议:RIP,SNMP,L2TP等。
大部分情况下我们使用的都是基于TCP/IP协议的流Socket,因为它是一种稳定的通信协议。以此为例:
一台计算机要和另一台计算机进行通讯,获取其上应用程序的数据,必须通过Socket建立连接,要知道对方的IP和端口号。建立一个Socket连接需要通过底层TCP/IP协议来建立TCP连接,而建立TCP连接必须通过底层IP协议根据给定的IP在网络中找到目标主机。目标计算机上可能跑着多个应用,所以我们必须要根据端口号来制定目标应用程序,这样就可以通过一个 Socket 实例唯一代表一个主机上的一个应用程序的通信链路了。
那么Socket是如何建立通讯链路的呢?
假设有一台计算机作为客户端,另一台作为服务端。当客户端需要向服务端通信,客户端首先要创建一个Socket实例:
Socket socket = new Socket("127.0.0.1",1234);
若没有指定端口号,操作系统将为这个Socket实例分配一个没有被使用的本地端口号。此外创建了一个包含本地和远程地址和端口号的套接字数据结构,这个数据结构将一直保存在系统中直到这个连接关闭,代码如下:
public Socket(String host, int port) throws UnknownHostException, IOException { this(host != null ? new InetSocketAddress(host, port) : new InetSocketAddress(InetAddress.getByName(null), port), (SocketAddress) null, true); }
客户端试图和服务端建立TCP连接,此时会进行三次握手。
第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认;
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。

完成三次握手后Socket的构造函数成功返回,Socket实例创建完毕。
互联网是一种尽力而为(best-effort)的网络,客户端的起始消息或服务器端的回复消息都可能在传输过程中丢失。出于这个原因,TCP 协议实现将以递增的时间间隔重复发送几次握手消息。如果TCP客户端在一段时间后还没有收到服务器的返回消息,则发生超时并放弃连接。这种情况下,构造函数将抛出IOException 异常。
而服务端也需要创建与之对应的ServerSocket,ServerSocket的创建比较简单,只需要指定端口号:
ServerSocket serverSocket = new ServerSocket(10001);
同时操作系统也会为ServerSocket实例创建一个底层数据结构:
bind(new InetSocketAddress(bindAddr, port), backlog); //见构造方法
这个数据结构中包含指定监听的端口号和包含监听地址的通配符,通常情况下是监听所有地址,下面是比较典型的ServerSocket代码:
public void testSocket() throws Exception { ServerSocket serverSocket = new ServerSocket(10002); Socket socket = null; try { while (true) { socket = serverSocket.accept(); System.out.println("socket连接:" + socket.getRemoteSocketAddress().toString()); BufferedReader in = new BufferedReader(new InputStreamReader(socket.getInputStream())); while(true) { String readLine = in.readLine(); System.out.println("收到消息" + readLine); if("end".equals(readLine)) { break; } //客户端断开连接 socket.sendUrgentData(0xFF); } } } catch (SocketException se) { System.out.println("客户端断开连接"); } catch (IOException e) { e.printStackTrace(); } finally { System.out.println("socket关闭:" + socket.getRemoteSocketAddress().toString()); socket.close(); } }
当调用accept()方法时,服务端将进入阻塞状态,等待客户端的请求。当有客户端请求到来时,将为这个链接创建一个套接字数据结构,包括请求客户端的地址和端口号。该数据结构将被关联到ServerSocket实例的一个未连接列表里。此时连接并没有成功建立,处于三次握手阶段,Socket构造函数并未成功返回。当三次握手成功后,会将Socket实例对应的数据结构从未完成列表移到完成列表中。所以 ServerSocket 所关联的列表中每个数据结构,都代表与一个客户端的建立的 TCP 连接。
当连接成功创建后,我们要做的就是传输数据,这才是主要目的。如上例代码,在客户端和服务端都有一个Socket实例,而每个Socket实例都会拥有一个InputStream和OutputStream,我们正是通过它们传输数据。当Socket对象创建时,操作系统将会为InputStream和OutputStream分别分配一定大小的缓冲区,数据的写入和读取都是通过缓存区完成的。发送端的缓冲区称之为SendQ,是一个FIFO的队列,接收端的缓冲区称之为RecvQ,同样也是FIFO队列。
数据传输时,发送端将数据写入到OutputStream对应的SendQ队列中,以字节为单位发送到接收端InputStream的RecvQ队列中。当SendQ队列填满时,发送端的write方法将会阻塞住;而当RecvQ队列中没有数据时,接收端的read方法也将被阻塞。
一些情况下,客户端和服务端之间可能会产生死锁问题,例如:
- 如果在连接建立后,客户端和服务器端都立即尝试接收数据,显然将导致死锁。
- 客户端和服务端都尝试向对方write数据,并且数据长度大于两端缓冲区的和。此时会导致不管客户端还是服务端RecvQ和SendQ都满了,剩下的数据无法发送,两个write操作都不能完成,两个程序都将永远保持阻塞状态,产生死锁。
死锁的问题是要注意的,需要对数据的写入和读取做一个协调,解决死锁的方式可以使用多线程,也可以使用非阻塞的io,这里就不再深究了。
关于Java中IO的内容大概就说这么多了,后面会写写NIO的内容。