面试精讲之面试考点及大厂真题 - 分布式专栏 09 缓存必问:Reids持久化,高可用集群
09缓存必问:Reids持久化,高可用集群

宝剑锋从磨砺出,梅花香自苦寒来。
引言
Redis 的优点中提到 Redis 支持持久化数据,宕机后可恢复数据,持久化就是基于内存读写的 Redis 数据一旦断电后,数据就无法恢复,为了解决这个问题,Redis 提供了可以将数据保存到磁盘的功能,这个过程称作持久化,被持久化的数据可以在机器重启后重新加载到内存中。
在过去的工作中,只要使用 Redis 都会遇到这两个问题需要思考:1.Redis 集群要不要开启数据持久化功能。2. 如果开启持久化,使用哪种刷盘方式。所以这部分知识点还是有必要掌握的。
1. 面试官:关于 Redis 持久化方式能说说吗?有哪两种。
问题分析:工作 8 年,几乎每个项目都有使用 Redis,但是 Redis 都被用作纯缓存使用,目的就是提高读写性能,所以线上 Redis 集群,Redis 数据持久化并没有开启,最大限度保证发挥 Redis 的优势。但是持久化作为 Redis 的亮点,这个问题还是每次面试被问。(当然,我没用过持久化不代表别人不用,所以更需要了解了),同时,了解 Redis 数据刷盘的设计思想,开阔思路。
我:
Redis 提供了两种持久化方式:RDB 和 AOF,时间限制,我大概概括下两种刷盘方式的区别和优缺点。
RDB(Redis DataBase)详解:
RDB 是 Redis 默认的持久化方案。在指定的时间间隔内,执行指定次数的写操作,则会将内存中的数据写入到磁盘中。即在指定目录下生成一个 dump.rdb 文件。Redis 重启会通过加载 dump.rdb 文件恢复数据。
Redis 提供了 SAVE 和 BGSAVE 两个命令来生成 RDB 文件,区别是前者是阻塞的,后者是后台 fork 子进程进行,不会阻塞主进程处理命令请求。载入 RDB 文件不需要手工运行,而是 server 端自动进行,只要启动时检测到 RDB 文件存在 server 端便会载入 RDB 文件重建数据集。当然上面简介中已经提到,如果同时存在 AOF 的话会优先使用 AOF 重建数据集,因为其保存的数据更完整。
优点:
- 适合大规模的数据恢复,如果业务对数据完整性和一致性要求不高,RDB 的启动速度更快,是很好的选择。
- RDB 文件简洁,它保存了某个时间点的 Redis 数据集,适合用于做备份。你可以设定一个时间点对 RDB 文件进行归档,如果 1s 间隔保存一次快照,这样就能在需要的时候很轻易地把数据恢复到不同的版本。
- 考虑到磁盘硬件故障问题,RDB 文件很适合用于灾备,因为单文件可以很方便地传输到另外的数据中心。
- RDB 的性能很好,需要进行持久化时,主进程会 fork 一个子进程出来,然后把持久化的工作交给子进程,自己不会有相关的 I/O 操作。
缺点:
1、数据的完整性和一致性不高,因为 SAVE 命令执行是有时间间隔的,比如 5min 备份一次,RDB 可能在最后一次备份时宕机,这 5min 的时间窗数据可能丢失。
2、备份时占用内存,因为 Redis 在备份时会独立创建一个子进程,将数据写入到一个临时文件(此时内存中的数据是原来的两倍),最后再将临时文件替换之前的备份文件。所以 Redis 的持久化和数据的恢复要选择在夜深人静的时候执行是比较合理的。
AOF 详解
AOF(Append Only File),Redis 默认不开启。它的出现是为了弥补 RDB 的不足(RDB 可能丢失一个时间窗口的数据),所以它采用日志的形式来记录每个写操作,生成一个 appendonly.aof 文件,并将日志追加到文件末尾。Redis 重启的会根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。有点类似 Mysql 的 binlog。
优点:
AOF 策略最大限度地保证数据不丢失,数据的完整性和一致性更高。
缺点:
AOF 备份产生的 appendonly.aof 文件较大,数据恢复的时候,也会比较慢,Redis 针对 AOF 文件大的问题,提供重写的瘦身机制。
面试官:OK(这不是简单概括了,至于具体配置参数就不问了,这一块用的不多。)
2. 面试官:关于 Redis 集群的设计,你了解如何搭建一个高可用集群设计吗?
问题分析: 不管是用 Mysql 还是 Redis,肯定避免不了这个问题,还没见过哪个公司使用的 Mysql or Redis 集群是单机的,至少也是个主从读写分离的,Reids 官方给出了 Redis-cluster 方案,无中心架构,可线性扩展到 1000 个节点。
我:
过去的项目中, 公司主要使用的是 Redis-cluster 无中心结构。
(开始画图,能画就画,必须专业一点)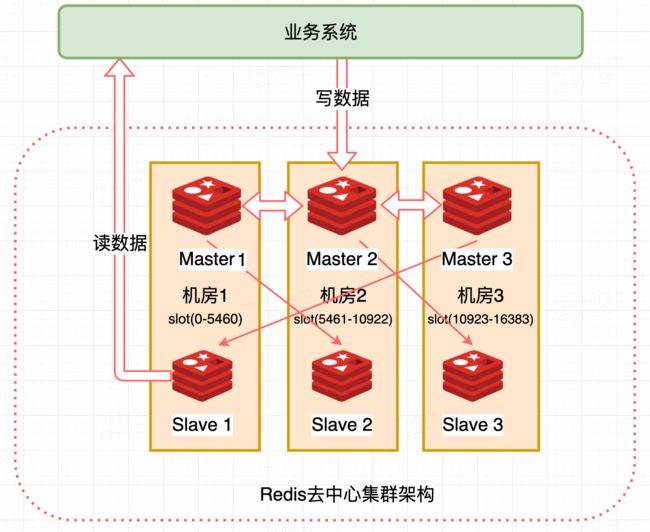
Redis Cluste 集群模式
Master-slave 模式中,Master 成为集群中至关重要的一个节点,Master 的稳定性决定整个系统的稳定性,为解决这一问题,Redis Cluster 应需求而生,Redis Cluster 是官方在 Redis 3.0 版本正式推出的高可用以及分布式的解决方案。 内置数据自动分片机制,由多个 Redis 实例组成的整体,数据按照槽 (slot) 存储分布在多个 Redis 实例上,集群内部将所有的 key 映射到 16384 个 Slot 中。
Redis Cluster 实现的功能:
- 将数据分片到多个实例 (按照 slot 存储);
- 集群节点宕掉会自动 failover;
- 提供相对平滑扩容 (缩容) 节点。
优点:
- 无中心架构:三机房部署,其中一主一从构成一个分片,之间通过异步复制同步数据,异步复制存在数据不一致的时间窗口,保证高性能的同时牺牲了部分一致性一旦某个机房掉线,则分片上位于另一个机房的 slave 会被提升为 master 从而可以继续提供服务
- 可扩展性:可线性扩展到 1000 多个节点,节点可动态添加或删除。
- 降低运维成本,提高系统的扩展性和可用性。
面试官:分析的不错,时间有限,这个问题先聊到这。(关于 Redis 花的时间有点多)
深入分析
一主多从的模式已经无法支撑这么大量的数据存储,于是架构演进成多个主从模式结合在一起对外提供服务。
在官方文档 Redis Cluster Specification 中,作者详细介绍了官方集群模式的设计考量,主要有如下几点:
- Redis 集群模式采用去中心化的设计,即 P2P 而非之前业界衍生出的 Proxy 方式
- master 与 slave 之间采用异步复制,存在数据不一致的时间窗口,保证高性能的同时牺牲了部分一致性(还记得前面章节讲过的 CAP 定理吗?)
- Redis Cluste 可以线性扩展至 1000 个节点。
- Redis Cluster 本身就能自动进行 master 选举和 failover
还是上面的图,有同学还是不太明白这样设计有什么好处。详细分析下。
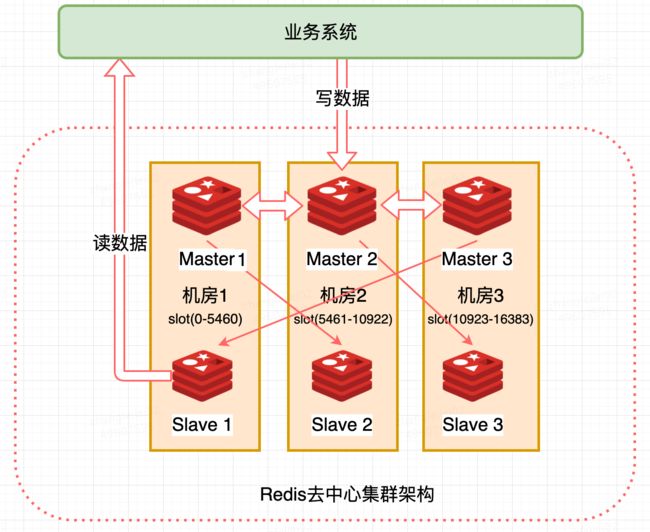
三机房部署,每个机房有一主一从,即一个 Master 对应一个 Slave ,但是你会发现,机房 1 中的 Master 1 连接的 Slave 在机房 2,机房 2 中的 Master 2 连接的 Slave 在机房 3,机房 3 中的 Master 3 连接的 Slave 在机房 1,这样构成一个环,为什么要这样设计?
三机房部署(其中一主一从构成一个分片,之间通过异步复制同步数据,一旦某个机房掉线,则分片上位于另一个机房的 slave 会被提升为 master 从而可以继续提供服务) ;每个 master 负责一部分 slot,数目尽量均摊;客户端对于某个 Key 操作先通过公式计算(计算方法见下文)出所映射到的 slot,然后直连某个分片,写请求一律走 master,读请求根据路由规则选择连接的分片节点,
假设机房 1 的全部机器断电了,1 机房数据都不能访问了吗?这显然是我们不希望的。前面已经说了 Master 负责写,Master 会自动同步到 Slava,如果 Master 写服务宕机,Slave 读服务会被提升为 master ,也就是说机房 1 的数据在机房 2 的 Slava2 上还有备份,数据还在,在宕机的 master 没有恢复前 Slave 要同时承担读写服务,虽然累一点,但是系统仍然能提供服务。
但是你会发现,单个机房如果距离很远, Master 1 的数据同步到 Slave2 上是跨机房,跨机房同步肯定不如同机房块,这样一来 Slave2 负责的读就会有延迟,Master1 要更新的数据还没有同步到他在另一个机房的备份前,读操作就是不一致的,这样设计牺牲掉一致性(C)。
总结
这一篇主要分析了 Redis 面试必须掌握的关于持久化和高可用集群方面的知识点,个人感觉属于中等难度。请务必多看,重点掌握。