Presto
Presto
1、简介
Hadoop提供了大数据存储和计算一套解决方案,完美地解决了大数据的存储和计算问题。但是Hadoop提供的Map-Reduce计算框架,适用于大数据量的离线和批量计算,它关注的吞吐量不是计算效率,在大数据量快速实时Ad-Hoc查询计算上表现很不友好。继Hive后,facebook公司在2012年开始开发Presto,与2013年正式开源,给Ad-Hoc查询带来了一股清凉的春风。Presto基于Java语言开发,在多数据源支持上,易用性,可扩展性上搜事大数据实时查询计算产品中的佼佼者。
2、特性
| 特点 | 说明 |
|---|---|
| 多数据源 | 目前Presto支持Mysql、PostgreSQL、Cassandra、Hive、Kafa等 |
| SQL | 完全兼容ANSI SQL,并提供sql shell 给用户 |
| 扩展性 | 基于SPI机制,易开发特定数据源连接器Connector |
| 混合计算 | 多数据的混合计算 |
| 高性能 | Presto官方测试是Hive性能的10倍以上 |
| PipeLine | 终端用户不用等待结果集处理完才看到结果,从一开始计算就可以产出一部分结果给终端 |
3、基本概念
3.1 服务进程
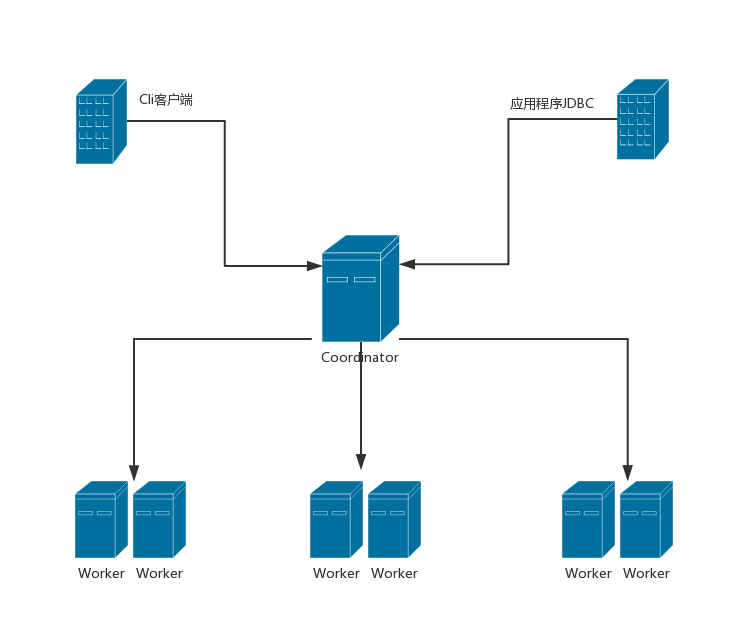
- Coordinator
一般Coordinator部署在集群中一个单独节点,是整个Presto集群的管理节点。它主要用户接受客户端提交的查询,解析查询并生成查询计划,对任务进行调度,对worker管理。
- Worker
工作节点,一般多个,主要进行数据的处理和Task的执行,它会周期性的向Coordinator进行Restful “沟通”,即心跳。
3.2 Presto模型
| 名称 | 说明 |
|---|---|
| Connector | Presto是通过Connector来访问不同的数据源的,可以将Connector当作访问不同数据源的驱动程序,每种Connector都实现了Presto里面的SPI接口。当需要使用某种Connnector时候需要在${PRESTO_HOME}/etc/catalog中配置。 |
| Catalog | 类似我们常规关系数据库Mysql里面实列。 |
| Schema | 类似我们常规关系数据库Mysql里面的database。 |
| Table | 类似我们常规关系数据库Mysql里面的table。 |
3.3 Presto查询模型
3.3.1 模型术语
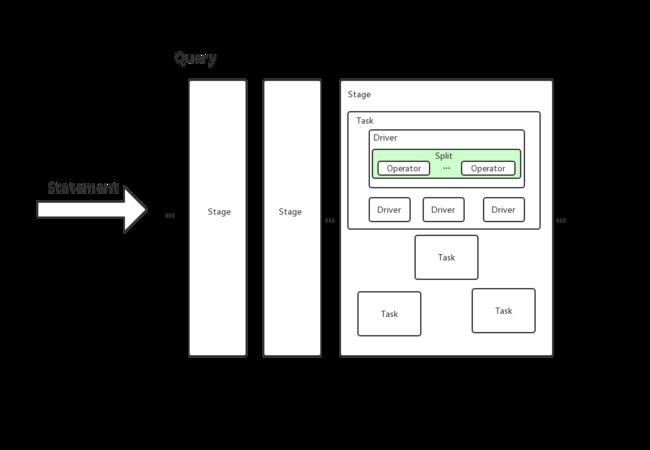
- Statement
客户端输入的SQL。
- Query
客户端输入的SQL在Presto内部的表述(实例)。由Stage、Task、Driver、Split、Operator、DataSource组成。
- Stage
Query的组成部分,多个有层级关系的Stage组合成Query。
- Exchage
Stage之间是通过Exchage来相互连接,完成数据交换。
- Task
正真运行在Worker上的,是Stage的逻辑上的拆分。
- Driver
组成Task的单位,操作的集合。一个Driver处理一个Split,并生成输入输出。
- Operator
具体作用在Split上的操作,如:过滤、加权、转换等。
- Split
分片,大的数据集中一个小的数据集。
3.3.1 查询过程
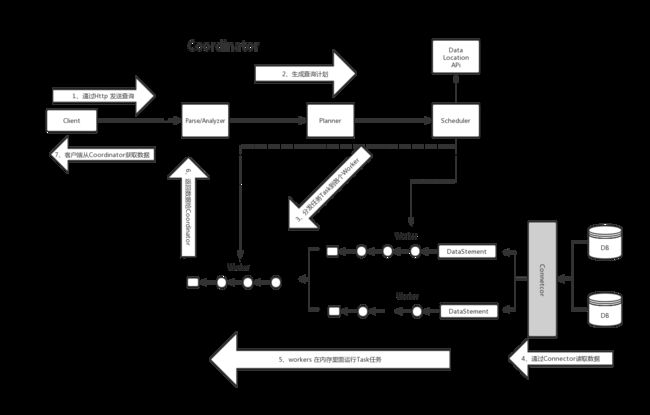
整个过程大致分为7步
- 客户端通过Http请求发送查询语句给Coordinator。
- Coordinator解析查询语句,生成查询计划。根据查询计划依次会生成:SqlQueryExecution、SqlStageExecution、HttpRemoteTask。
- 分发任务到各个Worker,全程是通过HttpRemoteTask里面的HttpClient将创建或者更新Task的请求发送到数据所在的节点。节点上的TaskResource接收到请求后在worker上启动/更新SqlTaskExecution对象,然后处理Split。
- 上游(距离数据源近的)Stage里面的Task,通过各种Connector从数据源里面读取数据。
- 下游Stage里面的Task读取上游Stage里输出的结果,拿到数据后在内存里面做计算和处理。
- Coordinator从分发Task后就可以从最顶层的Stage(Single Stage)里面获取Task计算结果,缓存到buffer,直到所有计算结束。
- Client从提交语句之后,会不停从Coordinator中获取本次查询的结果,不是等到查询结果都产生完毕才获取显示。
4、查询流程解析
presto 构建Restful服务使用的airlift框框。
4.1 客户端发起请求
public final class Presto {
private Presto() {
}
public static void main(String[] args) {
Console console = singleCommand(Console.class).parse(args);
if (console.helpOption.showHelpIfRequested() ||
console.versionOption.showVersionIfRequested()) {
return;
}
System.exit(console.run() ? 0 : 1);
}
}
4.2 执行客户端命令
类:Console
public boolean run() {
...
if (hasQuery) {
return executeCommand(queryRunner, query, clientOptions.outputFormat, clientOptions.ignoreErrors);
}
...
}
4.3 发送Http请求
类:StatementClientV1
private Request buildQueryRequest(ClientSession session, String query)
{
HttpUrl url = HttpUrl.get(session.getServer());
if (url == null) {
throw new ClientException("Invalid server URL: " + session.getServer());
}
// 注意路径
url = url.newBuilder().encodedPath("/v1/statement").build();
Request.Builder builder = prepareRequest(url).post(RequestBody.create(MEDIA_TYPE_TEXT, query));
...
return builder.build();
}
4.4 Coordinator处理请求
类:StatementResource
@Path("/v1/statement")
public class StatementResource {
@POST
@Produces(MediaType.APPLICATION_JSON)
public Response createQuery(
String statement,
@HeaderParam(X_FORWARDED_PROTO) String proto,
@Context HttpServletRequest servletRequest,
@Context UriInfo uriInfo) {
...
// 核心
Query query = Query.create(
sessionContext,
statement,
queryManager,
sessionPropertyManager,
exchangeClient,
responseExecutor,
timeoutExecutor,
blockEncodingSerde);
queries.put(query.getQueryId(), query);
// 获取结果
QueryResults queryResults = query.getNextResult(OptionalLong.empty(), uriInfo, proto, DEFAULT_TARGET_RESULT_SIZE);
...
return toResponse(query, queryResults);
}
}
后面逻辑较多,具体怎么个处理,有兴趣的可以参考:一条sql如何倍presto执行的。
5、Hive Connector
Presto查询过程和Hive不同,它是从Hive-Metastore里面获取表的元数据信息和与之关联的数据文件信息,然后利用HdfsEnvironment操作HDFS文件。

-
persto配置的hive.properties文件
connector.name=hive-hadoop2 hive.metastore.uri=thrift://p1:9083 hive.metastore-cache-ttl=0s hive.metastore-refresh-interval=0s // hdfs信息相关配置文件位置 hive.config.resources=/etc/hive/conf/core-site.xml,/etc/hive/conf/hdfs-site.xml -
获取Hive Metastore元数据
类:HiveMetastoreClientFactory
public HiveMetastoreClient create(HostAndPort address)throws TTransportException { return new ThriftHiveMetastoreClient(Transport.create(address, sslContext, socksProxy, timeoutMillis, metastoreAuthentication)); } -
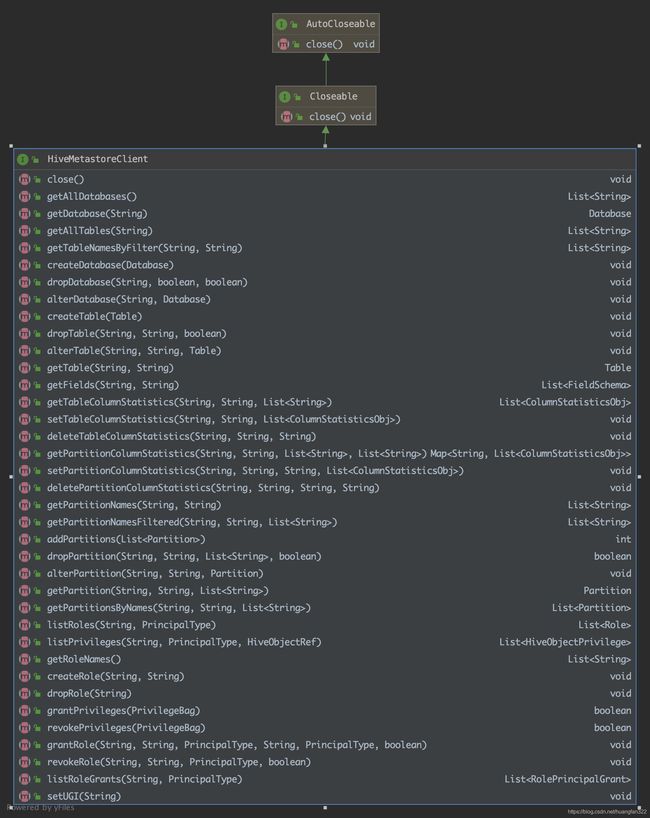
HiveMetastoreClient 里面方法,curd操作
- 加载元数据
类:CachingHiveMetastore
@ThreadSafe
public class CachingHiveMetastore implements ExtendedHiveMetastore{
//这里面有2个关键配置项,其他配置可以参看MetastoreClientConfig里面配置
// hive.metastore-refresh-interval,默认0
// hive.metastore-cache-ttl,默认0
public CachingHiveMetastore(...){
// 主要的逻辑都是在构造函数里面完成的,太多了,省略了
...
}
}
- 获取FileSystem
public FileSystem getFileSystem(String user, Path path, Configuration configuration)
throws IOException {
return hdfsAuthentication.doAs(user, () -> {
// 从我们配置的hive的catalog文件里面读取hdfs相关信息
FileSystem fileSystem = path.getFileSystem(configuration);
fileSystem.setVerifyChecksum(verifyChecksum);
return fileSystem;
});
}
6、插件开发
6.1 Connector开发
Presto目前支持很多的数据源,数据源都是以plugin形式添加的。下面是我安装的presto里面的plugin
drwxr-xr-x 2 root root 4096 Oct 29 13:34 tpch
drwxr-xr-x 2 root root 4096 Oct 29 13:34 mongodb
drwxr-xr-x 2 root root 4096 Oct 29 13:34 session-property-managers
drwxr-xr-x 2 root root 4096 Oct 29 13:34 postgresql
drwxr-xr-x 2 root root 4096 Oct 29 13:34 kudu
drwxr-xr-x 2 root root 4096 Oct 29 13:34 geospatial
drwxr-xr-x 2 root root 4096 Oct 29 13:34 example-http
drwxr-xr-x 2 root root 4096 Oct 29 13:34 localfile
drwxr-xr-x 2 root root 4096 Oct 29 13:34 mysql
drwxr-xr-x 2 root root 4096 Oct 29 13:34 atop
drwxr-xr-x 2 root root 4096 Oct 29 13:34 accumulo
drwxr-xr-x 2 root root 4096 Oct 29 13:34 sqlserver
drwxr-xr-x 2 root root 4096 Oct 29 13:34 redis
drwxr-xr-x 2 root root 4096 Oct 29 13:34 presto-elasticsearch
drwxr-xr-x 2 root root 4096 Oct 29 13:34 password-authenticators
drwxr-xr-x 2 root root 4096 Oct 29 13:34 blackhole
drwxr-xr-x 2 root root 4096 Oct 29 13:34 redshift
drwxr-xr-x 2 root root 4096 Oct 29 13:34 kafka
drwxr-xr-x 2 root root 4096 Oct 29 13:34 jmx
drwxr-xr-x 2 root root 4096 Oct 29 13:34 teradata-functions
drwxr-xr-x 2 root root 4096 Oct 29 13:34 resource-group-managers
drwxr-xr-x 2 root root 4096 Oct 29 13:34 presto-thrift
drwxr-xr-x 2 root root 4096 Oct 29 13:34 memory
drwxr-xr-x 2 root root 4096 Oct 29 13:34 tpcds
drwxr-xr-x 2 root root 4096 Oct 29 13:34 raptor
drwxr-xr-x 2 root root 4096 Oct 29 13:34 ml
drwxr-xr-x 2 root root 4096 Oct 29 13:34 cassandra
drwxr-xr-x 2 root root 4096 Nov 25 21:39 hive-hadoop2
步骤
源代码里面有presto-example-http 的自定义connector代码示例。
- 添加插件
presto-main/etc/config.properties下
plugin.bundles=\
../presto-blackhole/pom.xml,\
../presto-memory/pom.xml,\
../presto-jmx/pom.xml,\
../presto-raptor/pom.xml,\
../presto-hive-hadoop2/pom.xml,\
//*******官方示例 example-http *********
../presto-example-http/pom.xml,\
../presto-kafka/pom.xml, \
../presto-tpch/pom.xml, \
../presto-local-file/pom.xml, \
../presto-mysql/pom.xml,\
../presto-sqlserver/pom.xml, \
../presto-postgresql/pom.xml, \
../presto-tpcds/pom.xml
- 需要实现的接口
// presto 会加载所有实现了Plugin的实现类
Plugin
// 实例化Connector工厂
ConnectorFactory
// connector连接器,里面有metadata、splitManager、recordSetProvider等实例
Connector
// 元数据管理(schemas、tables等)
ConnectorMetadata
// 数据分片
ConnectorSplitManager
// 数据读取类
ConnectorRecordSetProvider
...
- 示例代码
// 插件
public class ExamplePlugin implements Plugin {
@Override
public Iterable getConnectorFactories() {
return ImmutableList.of(new ExampleConnectorFactory());
}
}
// 连接器工厂
public class ExampleConnectorFactory implements ConnectorFactory {
...
@Override
public Connector create(String catalogName, Map requiredConfig, ConnectorContext context) {
...
// 获取Connector 实例
return injector.getInstance(ExampleConnector.class);
}
}
// 连接器,里面包含元数据管理,数据分片,数据读取类 等实例变量
public class ExampleConnector implements Connector{
private static final Logger log = Logger.get(ExampleConnector.class);
private final LifeCycleManager lifeCycleManager;
private final ExampleMetadata metadata;
private final ExampleSplitManager splitManager;
private final ExampleRecordSetProvider recordSetProvider;
// get/set 方法 ...
}
6.2 函数开发
Presto自定义了很多函数,在presto-mainmodule下,有个operator文件夹。
-
函数分类:
- 标量函数(scalar)
- 聚合函数(aggregation)
- 开窗函数(window)
-
代码示例
// 标量函数
@Description("return array containing elements that match the given predicate")//函数描述
@ScalarFunction(value = "filter", deterministic = false)
public final class ArrayFilterFunction{
@TypeParameter("T")
@TypeParameterSpecialization(name = "T", nativeContainerType = long.class) // 参数类型
@SqlType("array(T)")// 返回函数类型
public static Block filterLong(
@TypeParameter("T") Type elementType,
@SqlType("array(T)") Block arrayBlock,
@SqlType("function(T, boolean)") FilterLongLambda function){
...
实现逻辑
...
BlockBuilder resultBuilder = elementType.createBlockBuilder(null, positionCount);
return resultBuilder.build();
}
}
// 开窗函数
@WindowFunctionSignature(name = "rank", returnType = "bigint")
public class RankFunction extends RankingWindowFunction{
private long rank;
private long count;
@Override
public void reset(){
rank = 0;
count = 1;
}
@Override
public void processRow(BlockBuilder output, boolean newPeerGroup, int peerGroupCount, int currentPosition){
if (newPeerGroup) {
rank += count;
count = 1;
}
else {
count++;
}
BIGINT.writeLong(output, rank);
}
}
// 聚合函数
@AggregationFunction("count")
public final class CountAggregation {
private CountAggregation() {
}
// 数据在每个worker上分片输入
@InputFunction
public static void input(@AggregationState LongState state) {
state.setLong(state.getLong() + 1);
}
// worker间数据聚合
@CombineFunction
public static void combine(@AggregationState LongState state, @AggregationState LongState otherState) {
state.setLong(state.getLong() + otherState.getLong());
}
// 规约输出结果
@OutputFunction(StandardTypes.BIGINT)
public static void output(@AggregationState LongState state, BlockBuilder out) {
BIGINT.writeLong(out, state.getLong());
}
}
7、性能优化
- Order by + limit
order by 会扫描worker上表数据,耗内存,结合limit 使用减少计算消耗。
- Group By
需要分组的字段,distinct后数量倒序放置
select count(1),uid,age from user_sales group by uid,age;
- 使用模糊聚合函数
用精准误差换性能。
//不推荐
select count(distinct(age)) from user_sales;
//推荐
select count(approx_distinct(age)) from user_sales;
- 合并like
//不推荐
select * from user_sales where name like '%a%' or name like '%b%' or name like '%c%';
//推荐
select * from user_sales where name regexp_like(name, a|b|c);
- 大表 join 小表
Presto 使用的是Distributed Hash Join,优先将右表进行hash分区的数据配发到集群中所有woker上(请确保此时的woker内存>右表大小),然后才将左表hash的分区依次传输到相应的集群节点上。即,右表数据的分区会先全部到分布到所有计算节点,左表hash分区是流式传输到相应的计算节点。
- 关闭 Distributed Hash Join
如果数据存在倾斜,hash join 性能急剧下降,此时可以通过 ```set session distributes_join='false’关闭hash join。那么2表就不会进行hash重分布,右表会被广播到左表Source Stage 的每个节点做join。
- 使用ORC存储和snappy压缩
针对hive创建表,建议使用orc格式存储,preto在代码层面对orc格式做了很多优化。 数据压缩可以减少节点间数据传输对IO带宽压力,对于即席查询需要快速解压,snappy比较合适。