tensorflow入门教程(二十三)Object Detection API目标检测(上)
#
#作者:韦访
#博客:https://blog.csdn.net/rookie_wei
#微信:1007895847
#添加微信的备注一下是CSDN的
#欢迎大家一起学习
#
1、概述
上一讲,我们使用slim库对图片进行检测,每个物品用同一种颜色标注,显得乱七八糟的。这一讲,我们来学习目标检测。目标检测就是,输入一张图片,输出是将该图片中所含的所有目标物体识别,并标记出他们的位置。如下图所示,

下面,我们先介绍第一个成功的将深度学习应用到目标检测的算法R-CNN,然后再介绍其变体Fast R-CNN和Faster R-CNN,最后,学习tensorflow中用于目标检测的Tensorflow Object Detection API。
2、R-CNN
传统目标检测方法:
- 使用穷举法筛选出图片上所有物体可能出现的区域框
- 对这些区域框提取特征
- 使用图像识别的方法对区域框分类
- 通过非极大值抑制输出结果
R-CNN的思路类似,只是在提取特征这一步,将传统的特征提取方法,如SIFT、HOG,换成了深度卷积网络。R-CNN框架如下图所示,

对于原始图像,
- 首先使用Selective Seach搜寻可能存在物体的区域。Selective Search可以从图像中启发式地搜索出可能包含物体的区域,相比穷举而言,可以减少一部分计算量。
- 然后将取出的可能含有物体的区域送入CNN中提取特征。CNN通常接受一个固定大小的图像,而取出的区域大小却各有不同。所以,R-CNN的做法是将区域缩放到统一大小,再使用CNN提取特征。
- 提取出特征后,使用SVM进行分类,最后通过非极大值抑制输出结果。
得益于CNN优异的特征提取能力,R-CNN的效果比传统方法好很多,但缺点是计算量太大。Fast R-CNN和Faster R-CNN在一定程度上改进了R-CNN计算量大的缺点。
3、SPPNet
学习Fast R-CNN之前,先学一下SPPNet,SPPNet全称是Spatial Pyramid Pooling Convolutional Networks,中文名是“空间金字塔池化卷积网络”,这名称很长很拗口啊,主要做的事是,将CNN的输入从固定尺寸改进为任意尺寸。
CNN结构中,输入图像的尺寸往往是固定的,输出可以看作是固定维数的向量。SPPNet在普通CNN结构中加入ROI池化层,使得网络的输入图像可以是任意尺寸,输出则不变,同样是一个固定维数的向量。ROI池化层结构如下所示,

假设卷积层输出的宽度为w,高度为h,通道为c。不管输入图像尺寸为多少,卷积层的通道数量不会变,而w和h则随着输入图像尺寸的变化而变化。
以上图为例,
- 首先把卷积层划分为4×4的网络,每个网格的宽为w/4,高为h/4,通道数为c,当不能整除时,需要取整,接着对每个网络中的每个通道都取出其最大值,其实就是对每个网络内的特征做最大值池化,这个4×4的网络就形成了16c维的特征。
- 接着再把网络划分为2×2的网络,再用同样的方法提取特征,提取的特征为4c。
- 再把网络划分为1×1的网络,提取的特征为1c。
- 最后,将得到的特征拼接起来,得到16c+4c+1c=21c维特征。
所以,这个输出特征长度跟w、h无关,所以ROI池化层可以把任意宽度和高度的卷积特征转换为固定长度的向量。
嘿嘿,说了这么多,这个ROI池化层怎么用到目标检测中呢?
可以这样想,网络的输入是一张图像,中间经过若干卷积形成卷积特征,这个卷积特征实际上和原始图像在位置上是有一定对应关系的。

如上图所示,原始图像有一辆小车,它使得卷积特征在同样位置产生激活。所以,原始图像中的候选框,实际上也可以对应到卷积特征中相同位置的框。由于候选框的大小不确定,对应到卷积特征的区域形状也不确定。但是,我们可以利用ROI池化层把卷积特征中的不同形状的区域对应到同样长度的向量特征中,就可以将原始图像中的不同长宽的区域对应到一个固定长度的向量特征,这就完成了各个区域的特征提取工作。
重点来了,R-CNN要对每个区域计算卷积,而SPPNet只需要计算一次卷积,所以,SPPNet的效率比R-CNN高得多。
4、Fast R-CNN
R-CNN和SPPNet对区域分类时,使用的是SVM分类器,而Fast R-CNN使用神经网络作为分类器,这就可以同时训练特征提取网络和分类网络,从而准确度更高。结构如下图所示。

对于原始图像,
- 首先,将它映射到卷积特征的对应区域。
- 然后,使用ROI池化层对该区域提取特征。
- 接着,使用全连接层,全连接层有两个输出,一个输出负责分类(softmax),另一个输出负责框回归(bbox regressor)。
下面说说分类和框回归。
分类:
假设要在图像中检测K类物体,则最终输出K+1个数,每个数代表该区域为某个类别的概率。之所以为K+1是因为还需要一个“背景类”,针对该区域无目标物体的情况。
框回归:
框回归要做的是对原始的检测框进行某种程度的“校准”,因为Selective Search获得的框有时存在一定偏差。假设Selective Search得到的框的参数为(x,y,w,h),其中(x,y)表示框左上角坐标,(w,h)表示宽和高,实际框位置为(x’,y’,w’,h’),框回归就是要学习参数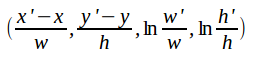 ,其中,
,其中,![]() 和
和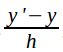 表示和尺度无关的平移量,
表示和尺度无关的平移量,![]() 和
和![]() 表示和尺度无关的缩放量。
表示和尺度无关的缩放量。
5、Faster R-CNN
Fast R-CNN需要使用Selective Search提取框,这个方法比较慢,大量时间都花在提取框上了,而Faster R-CNN就是解决这个问题的。Faster R-CNN用RPN(Region Proposal Network,区域提案网络)网络取代了Selective Search,不仅速度得到大大提高,而且获得了更加精准的结果。

上图为RPN网络结构,假设原始图片尺寸为3×224×224,前置CNN提取特征为51×39×256,然后对这个卷积特征再进行一次卷积计算,保持尺寸不变,再次得到一个新的51×39×256的卷积特征。为方便叙述,定义一个“位置”的概念:对于51×39×256的卷积特征,称它一共有51×39个“位置”。让新的卷积特征的每一个位置负责原图中对应位置的9种尺寸的框的检测,判断框中
是否存在一个物体,所以有51×39×9个框,这些框统称为“anchor”。anchor的结果如下图所示,
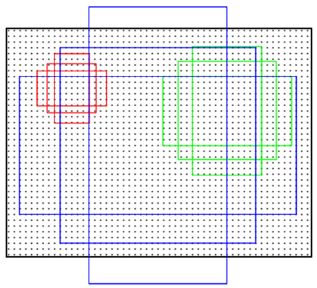
它们的面积分别为1282,2562,5122,每种面积又分为3中长宽比,分别为2:1, 1:2, 1:1,anchor的尺寸属于可调参数,不同任务可以选择不同尺寸。

上图展示了每个位置的计算步骤,假设k为单个位置对应的anchor个数,这里的k=9。首先使用一个3×3的滑动窗口,将每个位置转换为一个统一的256维特征,这个特征对应两个输出,一个表示该位置的anchor为物体的概率,这部分的总输出长度为2k。另一部分为框回归,一个anchor对应4个框回归参数,总输出长度为4k。
6、Tensorflow Object Detection API
接下来就是实战了,使用的是google开源的项目。
6.1、下载
首先将源码下载下来,地址:
https://github.com/tensorflow/models/
下载以后,就得到一个models文件夹,我们要的源码在
models/research/object_detection/文件夹里。
6.2、protoc版本
Tensorflow Object Detection API要求protoc版本为2.6.0以上,可以使用
protoc --version
命令查看版本,如果低于这个版本的或者编译出错,就得升级了。我的电脑的版本是2.6.1,先编译看看能不能通过再说。
6.3、编译protoc文件
protos文件下下有一些proto文件,我们要使用protoc将其编译,将其编译为python文件。

为了方便,我们将object_detection文件夹拷贝到自己的项目文件夹my_object_detection下,在my_object_detection文件夹下,使用下面命令进行编译,
$ protoc object_detection/protos/*.proto --python_out=.
编译出错了,打印如下:
object_detection/protos/ssd.proto:87:3: Expected "required", "optional", or "repeated".
object_detection/protos/ssd.proto:87:12: Expected field name.
object_detection/protos/model.proto: Import "object_detection/protos/ssd.proto" was not found or had errors.
object_detection/protos/model.proto:12:5: "Ssd" is not defined.
没办法,看来得升级protoc了。先执行下面命令卸载旧版本,
sudo apt-get remove libprotobuf-dev
然后,去这个网页下载最新的源码包,
https://github.com/google/protobuf/releases

目前更新到3.6.0版本了。
下载完后解压,然后执行下面的命令编译安装。
$ cd protobuf-3.6.0/
$ ./configure --prefix=/usr
$ make -j8
$ make check -j8
$ sudo make install -j8
$ sudo ldconfig # refresh shared library cache.
安装完了以后,再来看看protoc版本,
$ protoc --version
libprotoc 3.6.0
ok,升级成功,再来执行我们的编译命令,
$ protoc object_detection/protos/*.proto --python_out=.
也没错误。
可以看到,protos文件夹下也成功生成了很多python文件。
6.4、加入slim
Tensorflow Object Detection API也是以slim为基础实现的,所以需要将slim加入才能正常运行。将slim文件夹复制到my_object_detection下,再将object_detection/builders/model_builder_test.py拷贝到my_object_detection文件夹下。
6.5、测试
执行完上面步骤后,就可以测试我们是否安装正确,执行下面的命令,
$ python model_builder_test.py
很不幸,出现如下错误,
Traceback (most recent call last):
File "model_builder_test.py", line 21, in
from object_detection.builders import model_builder
File "/home/wilf/tensorflow-master/demo/my_object_detection/object_detection/builders/model_builder.py", line 17, in
from object_detection.builders import anchor_generator_builder
File "/home/wilf/tensorflow-master/demo/my_object_detection/object_detection/builders/anchor_generator_builder.py", line 21, in
from object_detection.protos import anchor_generator_pb2
File "/home/wilf/tensorflow-master/demo/my_object_detection/object_detection/protos/anchor_generator_pb2.py", line 15, in
from object_detection.protos import grid_anchor_generator_pb2 as object__detection_dot_protos_dot_grid__anchor__generator__pb2
File "/home/wilf/tensorflow-master/demo/my_object_detection/object_detection/protos/grid_anchor_generator_pb2.py", line 22, in
serialized_pb=_b('\n3object_detection/protos/grid_anchor_generator.proto\x12\x17object_detection.protos\"\xcd\x01\n\x13GridAnchorGenerator\x12\x13\n\x06height\x18\x01 \x01(\x05:\x03\x32\x35\x36\x12\x12\n\x05width\x18\x02 \x01(\x05:\x03\x32\x35\x36\x12\x19\n\rheight_stride\x18\x03 \x01(\x05:\x02\x31\x36\x12\x18\n\x0cwidth_stride\x18\x04 \x01(\x05:\x02\x31\x36\x12\x18\n\rheight_offset\x18\x05 \x01(\x05:\x01\x30\x12\x17\n\x0cwidth_offset\x18\x06 \x01(\x05:\x01\x30\x12\x0e\n\x06scales\x18\x07 \x03(\x02\x12\x15\n\raspect_ratios\x18\x08 \x03(\x02')
TypeError: __new__() got an unexpected keyword argument 'serialized_options'
serialized_options这个参数有问题,那试着将所有的
serialized_options=None,
都去掉,然后再编译试试,
$ python model_builder_test.py
...............
----------------------------------------------------------------------
Ran 15 tests in 0.094s
OK
这样就可以了。为什么会这样?我也不知道,估计还是版本的问题吧,以前没接触过protoc。
如果您感觉本篇博客对您有帮助,请打开支付宝,领个红包支持一下,祝您扫到99元,谢谢~~
