100-Days-Of-ML系列Day1
最近看到github上有100-Days-Of-ML系列的项目,出了中英文版,在这里做一下搬运工,加上自己的学习体会,与大家分享。英文原版地址:英文版,中文版地址:中文版。
第一天的标题为数据预处理,一共分为了6步,都比较简单,属于入门级的预处理。具体如下:

第一步:导入库
导入所需要的python库,首先确保已经安装了numpy库、pandas库,为了使用方便,用as进行重命名。
import numpy as np
import pandas as pd第二步:导入数据
导入准备好的csv数据,数据。注意这里的Data.csv存放在当前的工作目录下,否则要使用绝对路径。
dataset = pd.read_csv('Data.csv')可以查看一下数据的前几行:
dataset.head()
还可以查看数值型数据的统计信息:
dataset.describe()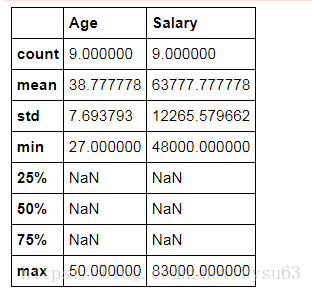
对数据进行切片,iloc表示取数据集中的某些行和某些列,逗号前表示行,逗号后表示列,这里表示取所有行,列取除了最后一列的其他列,而最后一列是应变量(Y)
X = dataset.iloc[ : , :-1].values
Y = dataset.iloc[ : , 3].values数据如下:


第三步:处理缺失值
刚才的X数据中我们可以看到部分数据为NaN,对于这些缺失值常用的处理办法有:1、删除包含缺失值的数据列,2、填补缺失值(平均值、众数)。对于本例中的数据,我们使用平均数填充缺失值。这里用到python机器学习中最常用的sklearn库。
from sklearn.preprocessing import Imputer
imputer = Imputer(missing_values = "NaN", strategy = "mean", axis = 0)
imputer = imputer.fit(X[ : , 1:3])
X[ : , 1:3] = imputer.transform(X[ : , 1:3])现在来观察一下处理后的X:

可以看到NaN值已经被处理为平均值了。
第四步:对分类变量的处理
我们可以看到上面X的Country列都是类别字符,这对机器学习来说是无法处理的类型,所以要对这一列进行类别编码。这里给的编码不太合理,不同的国家的地位应该是一样的,却给了不一样的数值,可能会造成机器学习的偏差,建议使用OneHot编码。
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X = LabelEncoder()
X[ : , 0] = labelencoder_X.fit_transform(X[ : , 0])现在来看看处理后的X:

处理完X,我们再来处理Y,这里我们用onehot编码:
onehotencoder = OneHotEncoder(categorical_features = [0])
X = onehotencoder.fit_transform(X).toarray()
labelencoder_Y = LabelEncoder()
Y = labelencoder_Y.fit_transform(Y)
第五步:划分测试集、训练集
训练集和测试集的比例为4:1
from sklearn.cross_validation import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split( X , Y , test_size = 0.2, random_state = 0)第六步:特征缩放
也就是常说的归一化处理,防止某些特征的值特别大而影响机器学习的效果。
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.fit_transform(X_test)来看看现在得到的数据:
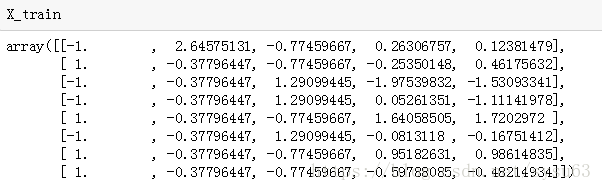
到这里,预处理就全部完成了,这样的数据就可以直接进行机器学习了。