在线最优化求解(Online Optimization)之五:FTRL
在上一篇博文中中我们从原理上定性比较了L1-FOBOS和L1-RDA在稀疏性上的表现。有实验证明,L1-FOBOS这一类基于梯度下降的方法有比较高的精度,但是L1-RDA却能在损失一定精度的情况下产生更好的稀疏性。那么这两者的优点能不能在一个算法上体现出来?这就是FTRL要解决的问题。
FTRL(Follow the Regularized Leader)是由Google的H. Brendan McMahan在2010年提出的[1],后来在2011年发表了一篇关于FTRL和AOGD、FOBOS、RDA比较的论文[2],2013年又和Gary Holt, D. Sculley, Michael Young等人发表了一篇关于FTRL工程化实现的论文[3]。
本节我们首先从形式上将L1-FOBOS和L1-RDA进行统一,然后介绍从这种统一形式产生FTRL算法,以及介绍FTRL算法工程化实现的算法逻辑。
1. L1-FOBOS和L1-RDA在形式上的统一
L1-FOBOS在形式上,每次迭代都可以表示为(这里我们令![]() ,是一个随
,是一个随 变化的非增正序列):
变化的非增正序列):
把这两个公式合并到一起,有:
通过这个公式很难直接求出![]() 的解析解,但是我们可以按维度将其分解为
的解析解,但是我们可以按维度将其分解为 个独立的最优化步骤:
个独立的最优化步骤:
![]()
由于![]() 与变量
与变量 无关,因此上式可以等价于:
无关,因此上式可以等价于:
再将这N个独立最优化子步骤合并,那么L1-FOBOS可以写作:
而对于L1-RDA,我们可以写作:
这里 ;如果令
;如果令![]() ,
,![]() ,上面两个式子可以写作:
,上面两个式子可以写作:
需要注意,与论文[2]中的Table 1不同,我们并没有将L1-FOBOS也写成累加梯度的形式。
比较公式(1)和公式(2),可以看出L1-FOBOS和L1-RDA的区别在于:(1) 前者对计算的是累加梯度以及L1正则项只考虑当前模的贡献,而后者采用了累加的处理方式;(2) 前者的第三项限制 的变化不能离已迭代过的解太远,而后者则限制不能离
的变化不能离已迭代过的解太远,而后者则限制不能离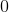 点太远。
点太远。
2. FTRL算法原理
FTRL综合考虑了FOBOS和RDA对于正则项和W限制的区别,其特征权重的更新公式为:
 公式(3)
公式(3)
注意,公式(3)中出现了L2正则项![]() ,在论文[2]的公式中并没有这一项,但是在其2013年发表的FTRL工程化实现的论文[3]却使用到了L2正则项。事实上该项的引入并不影响FRTL的稀疏性,后面的推导过程会显示这一点。L2正则项的引入仅仅相当于对最优化过程多了一个约束,使得结果求解结果更加“平滑”。
,在论文[2]的公式中并没有这一项,但是在其2013年发表的FTRL工程化实现的论文[3]却使用到了L2正则项。事实上该项的引入并不影响FRTL的稀疏性,后面的推导过程会显示这一点。L2正则项的引入仅仅相当于对最优化过程多了一个约束,使得结果求解结果更加“平滑”。
公式(3)看上去很复杂,更新特征权重貌似非常困难的样子。不妨将其进行改写,将最后一项展开,等价于求下面这样一个最优化问题:
上式中最后一项相对于来说是一个常数项,并且令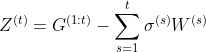 ,上式等价于:
,上式等价于:

针对特征权重的各个维度将其拆解成N个独立的标量最小化问题:
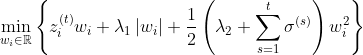
到这里,我们遇到了与上一篇RDA中类似的优化问题,用相同的分析方法可以得到:
从公式(4)可以看出,引入L2正则化并没有对FTRL结果的稀疏性产生任何影响。
3. Per-Coordinate Learning Rates
前面介绍了FTRL的基本推导,但是这里还有一个问题是一直没有被讨论到的:关于学习率![]() 的选择和计算。事实上在FTRL中,每个维度上的学习率都是单独考虑的(Per-Coordinate Learning Rates)。
的选择和计算。事实上在FTRL中,每个维度上的学习率都是单独考虑的(Per-Coordinate Learning Rates)。
在一个标准的OGD里面使用的是一个全局的学习率策略![]() ,这个策略保证了学习率是一个正的非增长序列,对于每一个特征维度都是一样的。
,这个策略保证了学习率是一个正的非增长序列,对于每一个特征维度都是一样的。
考虑特征维度的变化率:如果特征1比特征2的变化更快,那么在维度1上的学习率应该下降得更快。我们很容易就可以想到可以用某个维度上梯度分量来反映这种变化率。在FTRL中,维度i上的学习率是这样计算的:
 公式(5)
公式(5)
由于![]() ,所以公式(4)中有
,所以公式(4)中有 ,这里的
,这里的 和
和 是需要输入的参数,公式(4)中学习率写成累加的形式,是为了方便理解后面FTRL的迭代计算逻辑。
是需要输入的参数,公式(4)中学习率写成累加的形式,是为了方便理解后面FTRL的迭代计算逻辑。
4. FTRL算法逻辑
到现在为止,我们已经得到了FTRL的特征权重维度的更新方法(公式(4)),每个特征维度的学习率计算方法(公式(5)),那么很容易写出FTRL的算法逻辑(这里是根据公式(4)和公式(5)写的L1&L2-FTRL求解最优化的算法逻辑,而论文[3]中Algorithm 1给出的是L1&L2-FTRL针对Logistic Regression的算法逻辑):
FTRL里面的4个参数需要针对具体的问题进行设置,指导性的意见参考论文[3]。
结束语
本系列博文作为在线最优化算法的整理和总结,沿着稀疏性的主线,先后介绍了简单截断法、TG、FOBOS、RDA以及FTRL。从类型上来看,简单截断法、TG、FOBOS属于同一类,都是梯度下降类的算法,并且TG在特定条件可以转换成简单截断法和FOBOS;RDA属于简单对偶平均的扩展应用;FTRL可以视作RDA和FOBOS的结合,同时具备二者的优点。目前来看,RDA和FTRL是最好的稀疏模型Online Training的算法。
谈到高维高数据量的最优化求解,不可避免的要涉及到并行计算的问题。作者之前有篇博客[4]讨论了batch模式下的并行逻辑回归,其实只要修改损失函数,就可以用于其它问题的最优化求解。另外,对于Online下,文献[5]给出了一种很直观的方法:
对于Online模式的并行化计算,一方面可以参考ParallelSGD的思路,另一方面也可以借鉴batch模式下对高维向量点乘以及梯度分量并行计算的思路。总之,在理解算法原理的基础上将计算步骤进行拆解,使得各节点能独自无关地完成计算最后汇总结果即可。
最后,需要指出的是相关论文里面使用的数学符号不尽相同,并且有的论文里面也存在一定的笔误,但是并不影响我们对其的理解。在本系列博文中尽量采用了统一风格和含义的符号、变量等,因此在与参考文献中的公式对比的时候会稍有出入。另外,由于笔者的水平有限,行文中存在的错误难以避免,欢迎大家指正、拍砖。
另外,为了方便阅读,本系列博文被整理成pdf:在线最优化求解(Online Optimization)-冯扬-2014.12.09
参考文献
[1] H. Brendan McMahan & M Streter. Adaptive Bound Optimization for Online Convex Optimization. In COLT, 2010
[2] H. Brendan McMahan. Follow-the-Regularized-Leader and Mirror Descent: Equivalence Theorems and L1 Regularization. In AISTATS, 2011
[3] H. Brendan McMahan, Gary Holt, D. Sculley, Michael Young, Dietmar Ebner, Julian Grady, Lan Nie, Todd Phillips, Eugene Davydov, Daniel Golovin, Sharat Chikkerur, Dan Liu, Martin Wattenberg, Arnar Mar Hrafnkelsson, Tom Boulos, Jeremy Kubica, Ad Click Prediction: a View from the Trenches. In ACM SIGKDD, 2013
[4] 冯扬. 并行逻辑回归.http://blog.sina.com.cn/s/blog_6cb8e53d0101oetv.html
[5] Martin A. Zinkevich, Markus Weimer, Alex Smola & Lihong Li. Parallelized Stochastic Gradient Descent. In NIPS 2010