Vulkan简介
最近学习了一下Vulkan,通过这篇文章来对我所学的知识进行一个总结。

前言
Vulkan可以认为是Opengl版本的重写,它提供高性能和低CPU负担,天然支持多线程,能较好发挥多核CPU的性能,是一个能和DX12相提并论的东西。同时Vulkan几乎支持所有平台,跨平台API具有非常好的优势。Vulkan把驱动层做的很薄,把很多权限交给开发者,使开发者能更精确地控制渲染流程和资源管理。把很多功能做成一种扩展的形式,当你需要的时候才把它加进来。有的扩展还可以在开发的时候加入来提高开发效率,发布的时候将其去掉提高运行效率。也可以把传统的Opengl当做C#、Vulkan当C++来理解吧。
Vulkan概念介绍
VkPhysicalDevice & VkDevice
这是Vulkan独有的,VkPhysicalDevice是物理设备或者说显卡,程序启动前要找到一块支持Vulkan的显卡,比如是否支持GeometryShader,是否支持光追扩展等。VkDevice就是从PhysicalDevice中创建得到的一个虚拟Device,在代码中都是通过这的虚拟Device来控制显卡的。在这个虚拟的Device中也需要检查是否支持需要的Queue、数据格式等。
Pipeline:
- 传统API:
- 1、可以认为只有一条全局管线,驱动会记录状态,比如开启了模板测试,后面的所有DrawCall就会开启模板测试。
- Vulkan:
-
1、有一个叫VkPipeline的类型,每一个DC都可以对应一条管线,管线的设置项非常多,比如顶点数据输入信息、数据格式、Viewport、Shader、MultiSample、属于哪个RenderPass的第几个Subpass等等。
2、管线创建后基本是不允许修改的,只有少量的信息可以修改,要修改这些信息也要在创建管线的时候提前声明。
3、管线的创建可以用pipelineCache加速创建速度,缓存信息可以从文件读取。
下面是创建管线的一些基本设置。
VkGraphicsPipelineCreateInfo pipelineInfo = {};
pipelineInfo.sType = VK_STRUCTURE_TYPE_GRAPHICS_PIPELINE_CREATE_INFO;
pipelineInfo.stageCount = 2;
pipelineInfo.pStages = shaderStage;
pipelineInfo.pVertexInputState = &vertexInputInfo;
pipelineInfo.pInputAssemblyState = &inputAssembly;
pipelineInfo.pViewportState = &viewportState;
pipelineInfo.pRasterizationState = &rasterizer;
pipelineInfo.pMultisampleState = &multisampling;
pipelineInfo.pDepthStencilState = nullptr;
pipelineInfo.pColorBlendState = &colorBlending;
pipelineInfo.pDynamicState = nullptr;
pipelineInfo.layout = pipelineLayout;
pipelineInfo.renderPass = renderPass;
pipelineInfo.subpass = 0;
pipelineInfo.basePipelineHandle = VK_NULL_HANDLE;
pipelineInfo.basePipelineIndex = -1;
if (vkCreateGraphicsPipelines(device, VK_NULL_HANDLE, 1, &pipelineInfo, nullptr, &graphicsPipeline) != VK_SUCCESS) {
throw std::runtime_error("failed to create graphics pipeline!");
}
总结:每个DC可以有一个独立管线,减少DC之间的耦合,有利于并行。管线可以提前创建,运行时不能修改,如果要切换一些渲染状态, 可以直接绑定另一个Pipeline,状态切换消耗低,保证高效。不像传统API,不同DC间要大量设置状态,驱动要做检查。
Buffer
Buffers in Vulkan are regions of memory used for storing arbitrary data that can be read by the graphics card。Vulkan中的Buffer是一块用来存储显卡可以读取的的任意数据存储区。Buffer的类型有几种,比如有Device Local 的,在创建这种Buffer要是使用一个叫VK_MEMORY_PROPERTY_DEVICE_LOCAL_BIT的参数。这种存储区域是显卡本地的,而且CPU不能访问的。而CPU能访问的存储区域,显卡访问性能比上面的略差一点。这些存储区域主要是显存和主存的一小部分区域。当显存用完可以把显存的数据交换到主存。这些存储区域是开放的,像一个数组,由开发者自己管理。
//with cpu assessable memory
void createVertexBuffers() {
VkDeviceSize bufferSize = sizeof(vertices[0])*vertices.size();
//VK_MEMORY_PROPERTY_HOST_COHERENT_BIT使用这个bit可以保证显卡在使用数据之前,数据已经复制到vertexbfferMemory了
//不会因为cache导致数据还没过去(也可以flush一下)
createBuffer(bufferSize, VK_BUFFER_USAGE_VERTEX_BUFFER_BIT, VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT |
VK_MEMORY_PROPERTY_HOST_COHERENT_BIT, vertexBuffer, vertexBufferMemory);
void* data;
vkMapMemory(device, vertexBufferMemory, 0, bufferSize, 0, &data);
memcpy(data, vertices.data(), (size_t)bufferSize);
vkUnmapMemory(device, vertexBufferMemory);
}
这是创建VertexBuffer的一点代码,这里使用的是HOST_VISIBLE的存储类型,就是CPU能访问的,这种的使用比较简单,直接map然后memcpy复制就行。
Image
Image在Vulkan中也是对应一种类型(VkImage),Image的用途非常多,具体如下所示。创建的时候可以指定Iamge大小,数据类型、数据布局、使用的颜色空间等。

其中值得一提的是数据布局,数据的不同布局会影响效率,比如你是一行一行读取Image,但是存储却是一列一列的,会降低命中率。下面是一些ImageLayout的选项。
typedef enum VkImageLayout {
VK_IMAGE_LAYOUT_UNDEFINED = 0,
VK_IMAGE_LAYOUT_GENERAL = 1,
VK_IMAGE_LAYOUT_COLOR_ATTACHMENT_OPTIMAL = 2,
VK_IMAGE_LAYOUT_DEPTH_STENCIL_ATTACHMENT_OPTIMAL = 3,
VK_IMAGE_LAYOUT_DEPTH_STENCIL_READ_ONLY_OPTIMAL = 4,
VK_IMAGE_LAYOUT_SHADER_READ_ONLY_OPTIMAL = 5,
VK_IMAGE_LAYOUT_TRANSFER_SRC_OPTIMAL = 6,
VK_IMAGE_LAYOUT_TRANSFER_DST_OPTIMAL = 7,
VK_IMAGE_LAYOUT_PREINITIALIZED = 8,
VK_IMAGE_LAYOUT_DEPTH_READ_ONLY_STENCIL_ATTACHMENT_OPTIMAL = 1000117000,
VK_IMAGE_LAYOUT_DEPTH_ATTACHMENT_STENCIL_READ_ONLY_OPTIMAL = 1000117001,
VK_IMAGE_LAYOUT_DEPTH_ATTACHMENT_OPTIMAL = 1000241000,
VK_IMAGE_LAYOUT_DEPTH_READ_ONLY_OPTIMAL = 1000241001,
VK_IMAGE_LAYOUT_STENCIL_ATTACHMENT_OPTIMAL = 1000241002,
VK_IMAGE_LAYOUT_STENCIL_READ_ONLY_OPTIMAL = 1000241003,
VK_IMAGE_LAYOUT_PRESENT_SRC_KHR = 1000001002,
VK_IMAGE_LAYOUT_SHARED_PRESENT_KHR = 1000111000,
VK_IMAGE_LAYOUT_SHADING_RATE_OPTIMAL_NV = 1000164003,
VK_IMAGE_LAYOUT_FRAGMENT_DENSITY_MAP_OPTIMAL_EXT = 1000218000,
VK_IMAGE_LAYOUT_DEPTH_READ_ONLY_STENCIL_ATTACHMENT_OPTIMAL_KHR = VK_IMAGE_LAYOUT_DEPTH_READ_ONLY_STENCIL_ATTACHMENT_OPTIMAL,
VK_IMAGE_LAYOUT_DEPTH_ATTACHMENT_STENCIL_READ_ONLY_OPTIMAL_KHR = VK_IMAGE_LAYOUT_DEPTH_ATTACHMENT_STENCIL_READ_ONLY_OPTIMAL,
VK_IMAGE_LAYOUT_DEPTH_ATTACHMENT_OPTIMAL_KHR = VK_IMAGE_LAYOUT_DEPTH_ATTACHMENT_OPTIMAL,
VK_IMAGE_LAYOUT_DEPTH_READ_ONLY_OPTIMAL_KHR = VK_IMAGE_LAYOUT_DEPTH_READ_ONLY_OPTIMAL,
VK_IMAGE_LAYOUT_STENCIL_ATTACHMENT_OPTIMAL_KHR = VK_IMAGE_LAYOUT_STENCIL_ATTACHMENT_OPTIMAL,
VK_IMAGE_LAYOUT_STENCIL_READ_ONLY_OPTIMAL_KHR = VK_IMAGE_LAYOUT_STENCIL_READ_ONLY_OPTIMAL,
VK_IMAGE_LAYOUT_BEGIN_RANGE = VK_IMAGE_LAYOUT_UNDEFINED,
VK_IMAGE_LAYOUT_END_RANGE = VK_IMAGE_LAYOUT_PREINITIALIZED,
VK_IMAGE_LAYOUT_RANGE_SIZE = (VK_IMAGE_LAYOUT_PREINITIALIZED - VK_IMAGE_LAYOUT_UNDEFINED + 1),
VK_IMAGE_LAYOUT_MAX_ENUM = 0x7FFFFFFF
} VkImageLayout;
Descriptor Sets & Layouts
Vulkan强调资源的复用,资源可以通过DescriptorSet绑定到Shader使用,一个Image绑定到上一个DC作为ColorAttachment,再绑定到当前DC做普通纹理使用。绑定的方式可以通过Multi-Set或者Multi-Binding。下面是使用Multi-Binding来绑定数据的Shader。这些资源布局和绑定和Pipeline类似都是预先创建好的,驱动不做验证,运行时Shader通过descriptorSet的信息寻找资源。
layout (binding = 0, rgba32f) uniform readonly image2D samplerPositionDepth;
layout (binding = 1, rgba8) uniform readonly image2D samplerNormal;
layout (binding = 2, rgba32f) uniform readonly image2D ssaoNoise;
layout (binding = 3, rgba8) uniform image2D resultImage;
CommandBuffer
- 传统API的渲染方式:
-
1、bind&draw的模式,绑定一些东西然后Draw,再绑定一些东西再Draw,是同步的,非常适合串行。
2、命令在驱动层记录和自动提交,开发者不知道命令什么时候提交到显卡计算。 如下图所示,驱动会根据它的策略判断是否应该提交命令,就有点像TCP,你的数据比协议头还小,是不会立刻发出去的。这样就会出现图中的问题,如果第一次Submit的任务在第二次Submit前就已经完成了,则有一段时间GPU不工作,就会产生气泡,GPU利用率不够高。

- Vulkan:(multi-thread rendering, control submission)
-
1、命令在CommandBuffer中记录。
2、命令的记录和提交是分离的,在使用Vulkan的时候记录指令可以在MainLoop之前就记录好,在主循环中直接Submit即可。
3、可以自定义提交的时机。在合适的时机提交命令可以提高CPU和GPU的利用率,减少一帧的计算时间。
4、可以创建多个CommandBuffer,多线程记录命令。如下所示,左边表示开两个线程来记录命令,充分发挥多核CPU的性能,提交完后再处理Physics和AI,这时候GPU和CPU一起工作,在EndOfFrame的时候所有渲染工作已经完成了。

为什么多线程渲染那么重要?实际上很多游戏都不止一个线程,如果渲染指令的提交只能单线程就会很拉胯。当使用多线程高效去计算游戏各种对象下一帧的方位后,却只能用单线程渲染所有对象,这时候很自然地就会想到把渲染也多线程一下。
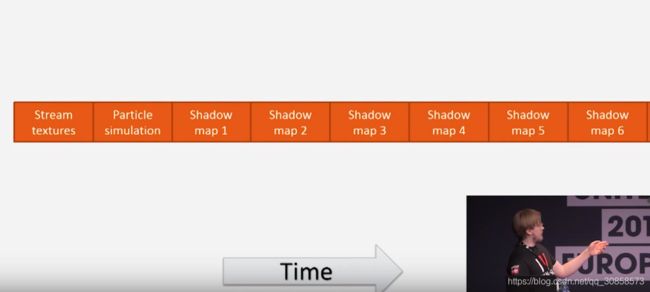
应用实例:
比如要为六个灯渲染各一张ShadowMap,在CPU多线程中可以像图中那样安排任务,其中橙色的代表指令提交。

总的来说,使用CommandBuffer可以更精确控制提交时机、提高运行效率。以前DrawCall会很严重限制帧率,十分消耗CPU资源,而现在则有所改观,使用多线程可以提高利用率,缩短计算时间,在高端电脑游戏中可以选择压榨性能,渲染更多物体,在手机上可以降低CPU的负担。
GPU Queue
- 传统API:
-
没有Queue,渲染方式如图,按照时间顺序渲染。这样的坏处是每次只能使用显卡的一小部分功能。一般显卡会有Copy Engine(专门做数据的复制传输)、Graphic Engine(管线化用来做渲染)、Compute Engine(只是计算数据)等。图中在Stream textures阶段时只有Copy Engine在工作,而其他不工作。
- Vulkan
- 有Transfer、Graphic、Compute功能的队列,其中带Compute和Graphic的队列都有Transfer功能,有的队列同时支持Compute和Graphic,而有的只支持Compute。比如我的1660同时支持Compute和Graphic有16条Queue,在编程中是可以开启多条线程向多条队列提交渲染指令的,这些Queue并行计算,Vulkan也提供了一些同步原语可以对并行计算进行同步。其中,提交到同一条Queue的指令是按顺序执行的。使用Queue后,上面的流程可以如下设计,其中最上面的是纯粹离线计算,在Compute Queue算,中间的使用Graphic Queue计算。

总的来说,使用Queue可以充分利用GPU,可以进行异步计算,未来Compute Shader的应用会越来越多,把一些Graphic Queue上的计算工作抽出来到Compute Queue上计算,获得更好的性能表现。资源加载也类似。
同步原语
因为Vulkan任务提交和执行是异步的,使用多条Queue的时候计算也是并行的,不同的DC之间难免有依赖关系,需要进行一些同步操作。Vulkan提供了几种不同粒度的同步原语,包括event、fence、barrier、semaphore。Vulkan的一些API可以自动wait和signal指定的同步原语,在资源上可以使用barrier定义依赖关系。比如在DC1中一张Image是一个被写入的,在DC2中是只读的,而DC1和DC2是并行的,就有可能DC2执行,读到空数据,然后DC1再去写入,或者DC1和DC2同时读写之类的。这时候可以在DC2的RenderPass中对这个image定义一个Barrier。
VkImageMemoryBarrier imageMemoryBarrier = {};
imageMemoryBarrier.sType = VK_STRUCTURE_TYPE_IMAGE_MEMORY_BARRIER;
// We won't be changing the layout of the image
imageMemoryBarrier.oldLayout = VK_IMAGE_LAYOUT_GENERAL;
imageMemoryBarrier.newLayout = VK_IMAGE_LAYOUT_GENERAL;
imageMemoryBarrier.image = textureComputeTarget.image;
imageMemoryBarrier.subresourceRange = { VK_IMAGE_ASPECT_COLOR_BIT, 0, 1, 0, 1 };
imageMemoryBarrier.srcAccessMask = VK_ACCESS_SHADER_WRITE_BIT; //注意这里
imageMemoryBarrier.dstAccessMask = VK_ACCESS_SHADER_READ_BIT; //注意这里
vkCmdPipelineBarrier(
drawCmdBuffers[i],
VK_PIPELINE_STAGE_COMPUTE_SHADER_BIT,
VK_PIPELINE_STAGE_FRAGMENT_SHADER_BIT,
VK_FLAGS_NONE,
0, nullptr,
0, nullptr,
1, &imageMemoryBarrier);
注意中间两行,大概就是说我要等到这个Image从可写变成可读再执行后面的操作。
总结
Vulkan把驱动层的一些任务交给开发者,使开发者能够以较低的消耗更深入地控制硬件,按照自己的需求来使用硬件,可以自定义内存管理,较好支持多线程。使用Vulkan的游戏应该尽量使用多线程,把一些复杂计算从Graphic queue转到Compute queue计算。由于本人能力有限,有错误的地方可以在评论中帮我指出。
Reference:
https://vulkan-tutorial.com/Introduction
https://www.khronos.org/registry/vulkan/specs/1.1-extensions/html/vkspec.html#introduction
https://zhuanlan.zhihu.com/p/20712354
https://zhuanlan.zhihu.com/p/73016473
https://www.youtube.com/watch?v=H1L4iLIU9xU
http://on-demand.gputechconf.com/gtc/2016/video/S6817.html
https://github.com/SaschaWillems/Vulkan