AURORA核多通道绑定使用注意事项
正文
在Aurora片间接口的调试中,一共需要用到两片FPGA,为达到速率的要求,所以Aurora需要采用主从双核,双通道绑定的工作模式,一共需要四个GTX(一个GTX 支持4Gbps的速率,一个Aurora核使用两个GTX,所以本例程中一个Aurora核最高支持8Gbps的速率)来完成片间数据的传输工作。
在工程中,主从双核的例化截图如下图所示(上图为主核,下图为从核):
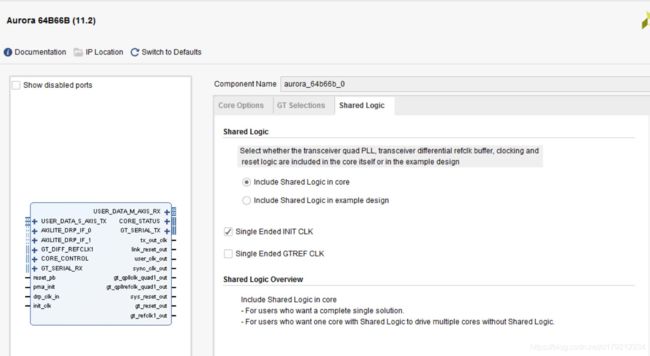
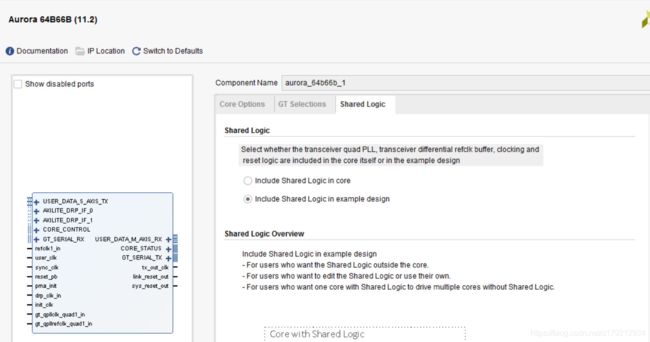
由上两图可以发现,主从双核最大的区别在于时钟和复位的逻辑是否包含在例化的IP核中,主核的时钟和复位的逻辑包含在例化的IP核中,而从核是包含在生成的example design中。
在完成Aurora的外部设计后,需要对GTX分配管脚,FPGA1和FPGA2中GTX的管脚如下图所示(上图为FPGA1,下图为FPGA2):
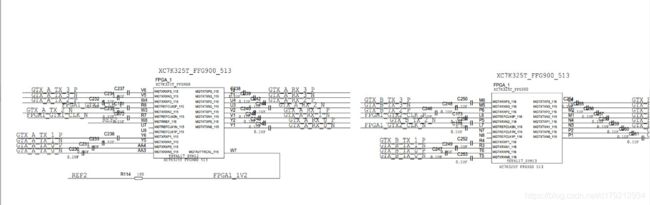
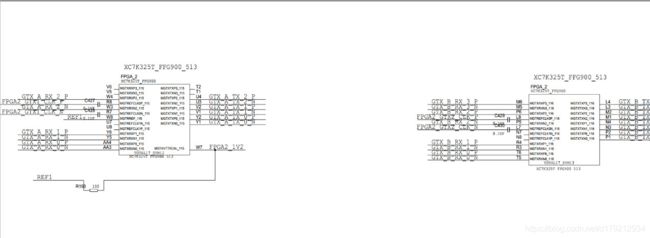
在之前的设计计划中,可以使用同一个BANK中的四个GTX,但是在实际分配时发现,FPGA1正常,但是FPGA2中的BANK 115只接了三个GTX的管脚,而BANK 116的时钟管脚没有接晶振,考虑到差分时钟可以驱动相邻的BANK,所以采用BANK 115和BANK 116共同使用,在两个BANK中各接两个GTX的方案。
此时在工程在实现时报了如下的错误:
[Place 30140] Unroutable Placement! A GTXE_COMMON / GTXE_CHANNEL clock component pair is not placed in a routable site pair. The GTXE_COMMON component can use the dedicated path between the GTXE_COMMON and the GTXE_CHANNEL if both are placed in the same clock region. If this sub optimal condition is acceptable for this design, you may use the CLOCK_DEDICATED_ROUTE constraint in the .xdc file to demote this message to a WARNING. However, the use of this override is highly discouraged. These examples can be used directly in the .xdc file to override this clock rule.
< set_property CLOCK_DEDICATED_ROUTE FALSE [get_nets core_wrapper_i/inst/core_gt_common_i/gt0_qplloutclk_out] >
core_wrapper_i/inst/core_gt_common_i/gtxe2_common_i (GTXE2_COMMON.QPLLOUTCLK) is provisionally placed by clockplacer on GTXE2_COMMON_X1Y1
core_wrapper_i/inst/pcs_pma_block_i/transceiver_inst/gtwizard_inst/inst/gtwizard_i/gt0_GTWIZARD_i/gtxe2_i (GTXE2_CHANNEL.QPLLCLK) is locked to GTXE2_CHANNEL_X1Y1
The above error could possibly be related to other connected instances. Following is a list of
all the related clock rules and their respective instances.
Clock Rule: rule_bufds_bufg
Status: PASS
Rule Description: A BUFDS driving a BUFG must be placed on the same half side (top/bottom) of the device
core_wrapper_i/inst/core_clocking_i/ibufds_gtrefclk (IBUFDS_GTE2.O) is locked to IBUFDS_GTE2_X1Y0
core_wrapper_i/inst/core_clocking_i/bufg_gtrefclk (BUFG.I) is provisionally placed by clockplacer on BUFGCTRL_X0Y2
Clock Rule: rule_bufds_gtxchannel_intelligent_pin
Status: PASS
Rule Description: A BUFDS driving a GTXChannel must both be placed in the same or adjacent clock region
(top/bottom)
core_wrapper_i/inst/core_clocking_i/ibufds_gtrefclk (IBUFDS_GTE2.O) is locked to IBUFDS_GTE2_X1Y0
core_wrapper_i/inst/pcs_pma_block_i/transceiver_inst/gtwizard_inst/inst/gtwizard_i/gt0_GTWIZARD_i/gtxe2_i (GTXE2_CHANNEL.GTREFCLK0) is locked to GTXE2_CHANNEL_X1Y1
Clock Rule: rule_bufds_gtxcommon_intelligent_pin
Status: PASS
Rule Description: A BUFDS drivin
错误显示GTX的布局出了问题,问题指到了GTX COMMON和GTX CHANNEL上,然后查阅Aurora的用户手册发现了下面的内容:
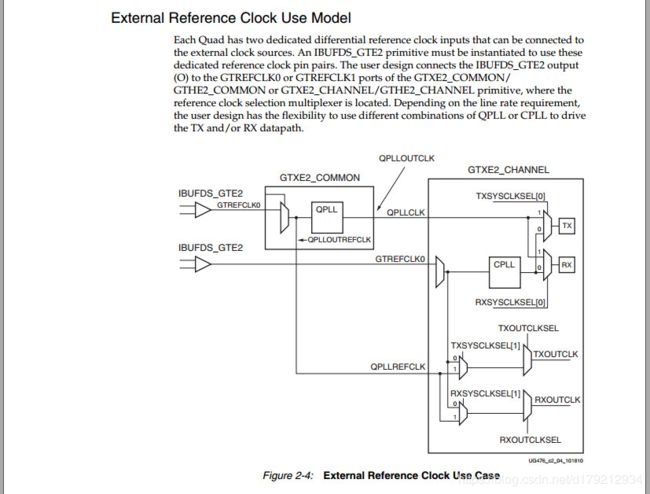
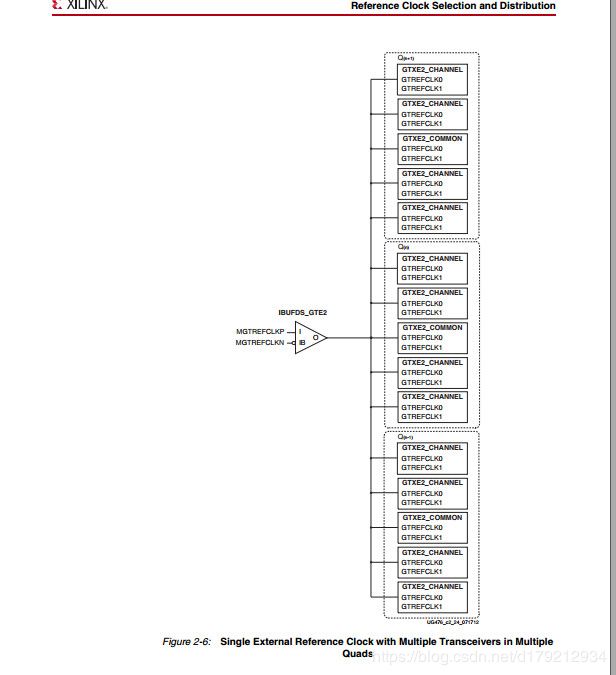
在图中我们可以发现差分时钟可以最多驱动12个GTX正常工作,但是在驱动时要注意GTX_COMMOM模块,即一个GTX_COMMON最多可以驱动同一个QUAD上的4个GTX_CHANNEL,如果说要驱动超过四个或者其他QUAD上的GTX,必须要生成新的GTX_COMMON模块,来保证其他QUAD上的GTX可以正常工作。
这是检查了一下工程发现了问题,主核的Aurora IP核中包含了GTX_COMMON模块,但是从核GTX_COMMON模块在IP核的外面被注释掉了,因为在之前的设计中,两个IP核的四个GTX在同一个BANK中,所以在从核的顶层将GTX_COMMOM模块删掉了,所以该模块产生的信号(gt_qpllclk_quad1_in_i和gt_qpllrefclk_quad1_in_i)采用了主核产生后外接到从核的工作模式。
发现问题后,将从核的GTX_COMMON模块添加到从核的顶层,并且将gt_qpllclk_quad1_in_i和gt_qpllrefclk_quad1_in_i这两个信号从外接改成了从核的GTX_COMMON模块产生后再接到IP核的方式,问题解决。