关于使用python,批量给组内多语言json文件添加字符串的初步探究
简介
在日常的项目开发中,若项目支持多国语言,那么常常会需要把新增的json字符串(未翻译)批量添加到各国语言对应的多语言json文件中,防止因为未添加多语言字符串而导致海外版的web渲染异常等问题。
然而,现在组内的多语言处理工具暂未有批量添加指定json字符串的功能,我在自学python的文件操作方法过程中,写了一个能简单实现功能的python脚本
源码
# 用户输入文件名,脚本遍历当前路径下的所有文件夹和文件,匹配到包含该文件名的所有文件,并添加到json文件中
import os
import json
# By Kiri
# 使用绝对路径 先把json文件内容读取 然后赋值 再写入 缺点:无序,而且会覆盖同名属性
def appendJSON(dir, jsonDict):
with open(dir, 'r', encoding='utf-8') as f:
content = f.read()
# 清除JSON的BOM
if content.startswith(u'\ufeff'):
content = content.encode('utf8')[3:].decode('utf8')
content_str = json.loads(content)
for i in content_str:
jsonDict[i] = content_str[i]
with open(dir, 'w', encoding='utf-8') as f:
json.dump(jsonDict, f, indent=4, ensure_ascii=False)
# 第一次遍历当前目录 (使用os.walk()可以优化)当时对着几个原生库方法自己撸出来的,适用性和优化做的太差了。好绕
def printStrFile(arg):
main_dir = [x for x in os.listdir('.')]
file_list = [x for x in main_dir if os.path.isfile(x)]
dir_list = [x for x in main_dir if os.path.isdir(x)]
for x in file_list:
if(arg in x):
result_list.append(os.path.abspath(x))
# 开始
recursion_list(dir_list, arg, result_list)
# 输出结果List
if result_list == []:
print('No Match')
else:
for x in result_list:
print(x)
appendJSON(x, dict)
# 递归遍历目录,传参分别为只含目录的列表,比对字符串,结果list,和上一级的path
def recursion_list(Dir__List, arg, mainList, fatherPath=''):
# List是目录的集合
if Dir__List == []:
return
for item in Dir__List:
# 如果是第一次递归 则没有父亲路径
if fatherPath:
# 当前目录的绝对路径
dir_path = os.path.join(fatherPath, item)
else:
dir_path = os.path.abspath(item)
file_list = [x for x in os.listdir(
dir_path) if os.path.isfile(os.path.join(dir_path, x))]
dir_list = [x for x in os.listdir(
dir_path) if os.path.isdir(os.path.join(dir_path, x))]
for x in file_list:
if(arg in x):
mainList.append(os.path.abspath(os.path.join(dir_path, x)))
# 获取到当前目录下的目录文件列表,开始下一次递归
recursion_list(dir_list, arg, result_list, os.path.abspath(item))
result_list = []
# 需要追加的字符串在这里定义 会覆盖已有属性
dict = {"input233": "输入口",
"ioInput233": "IO输入口",
"function233": "用途",
"output233": "输出口",
"ioOutput233": "IO输出口",
"disable233": "禁用",
"custom233": "自定义",
"openDoor233": "开门按钮",
"doorStatus233": "门状态"
}
# 用户输入想要批量处理的文件名
match_str = input(
'Please enter a String to match the file in this DIR \n')
printStrFile(match_str)
使用方法
需要事先搭建python3环境,将该py文件放入项目目录,运行py MulitLanTest.py
输入想批量添加的文件名即可。
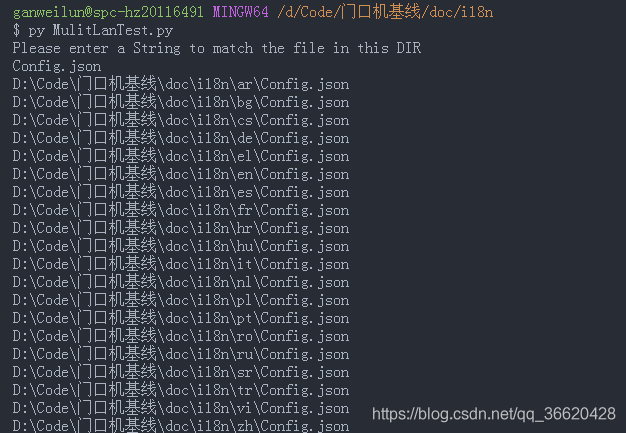
注意文件名可以不输入完全,但是要保证没有其他不需要的重名文件被添加
使用效果
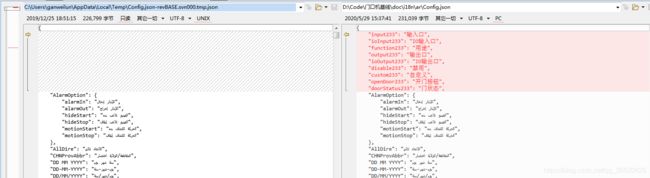
如图所示 确实添加上去了

待优化,是乱序的实际上,不利于我们后期整理和多语言工具兼容
缺点和改进方案
毕竟是学习python的途中顺手做的小脚本,在运用到组内实际场景中遇到了很多问题,待后续改进:
1.最主要的问题是,由于python的dict是无序的,所以目前通过赋值的方法添加到json文件中,不能指定插入位置和顺序 后续考虑用OrderedDict来初始化有序dict
2.待添加的json字符串目前要在python代码里手动更改,较为麻烦,后续考虑采用一种更方便的模式
3.目前敲一次命令只能添加一次,考虑改成设置多个关键词 一次性遍历和添加(不过实际上业务里没这个需求)
4.python代码较为粗糙 考虑优化下实现