Hive系列-unix_timestamp 问题
问题描述
环境测试集群
服务器系统版本:centos 7.2
cdh 版本:cdh5.9.0
hadoop 版本:2.6.0+cdh5.9.0
hive 版本:1.1.0+cdh5.9.0
nodeManger 节点:cdh003,cdh004, cdh005, cdh006
HiveServer2 节点:cdh001, cdh003,cdh004, cdh005, cdh006
需求:xxx_detail_incr_表的数据根据create_time字段按天分区导入xxx_detail_incr_par_表
mongodb同步数据到hive,按天分区时调用hive函数unix_timestamp 将时间字符串create_time=Sun May 20 23:59:21 CST 2018 格式化成 create_date=2018-05-20,格式化后的字符串当分区字符串,同样的sql,有时候跑任务格式化成功,有失败。效果十分诡异。
转换SQL如下:
INSERT OVERWRITE TABLE xxx_detail_incr_par_ PARTITION (create_date)
SELECT *,from_unixtime(unix_timestamp(create_time,'EEE MMM dd HH:mm:Ss z yyyy'),'yyyy-MM-dd') AS create_date
FROM xxx_detail_incr_;查看是否成功:
show partitions xxx_detail_incr_par_;成功时候:

失败时候:
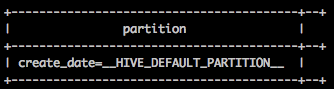
问题分析
这里用了hive的两个时间函数 from_unixtime,unix_timestamp 估计是这两个刁民在害朕。
create_time的字符串中包含特殊字符
使用hive regexp_replace 函数将不是英文、数字、空格的字符串替换掉。
INSERT OVERWRITE TABLE xxx_detail_incr_par_ PARTITION (create_date)
SELECT *,from_unixtime(unix_timestamp(regexp_replace(regexp_replace(create_time,'[^:a-zA-Z0-9 \s]+',''),'\\s+',' '),'EEE MMM dd HH:mm:Ss z yyyy'),'yyyy-MM-dd') AS create_date
FROM xxx_detail_incr_;重新执行,成功了,所有的分区都有。心中窃喜! 为了稳,多次执行,第二次执行的时候失败。
不是特殊字符。。
hiveserver2 问题
只留cdh004中的hiveserver2将集群中多余的停掉。多次执行,时间字符串个格式化有成功有失败。
不是hive server2 问题??
hive 转 mr job 时候问题
只留cdh003中的nodeManger 别的停掉。多次执行,时间字符串个格式化有全部失败。
问题出现了。。
依次单独只留一个nodeManger依次校验,发现
cdh003,cdh006 的 nodeManger 有问题启动的任务有问题。
cdh004,cdh005的 nodeManger 有问题启动的任务ok。
多次验证 hiveserver2 nodeManger 、服务器任务成功与失败的关系的得出
cdh003,cdh006 的机器环境和cdh004,cdh005 环境有差异。
网上找到unix_timestamp/from_unixtime 格式化时间是调用JAVA的SimpleDateFormat时间时间格式化的。
猜测 机器的时区不一致 ,语言不一致,检查发现时区ok,语言不一致。


心中窃喜,以为联系运维改系统语言。重启集群,重跑任务,问题解决。然并卵用,问题依旧。。。。
猜想定问题是因为本地化Locale的不同导致SimpleDateFormat转换失败,于是本地做了个小实验。
本地SimpleDateFormat实验
SimpleDateFormat使用默认Locale(中文)转换”Tue May 20 22:41:01 CST 2014”,报错
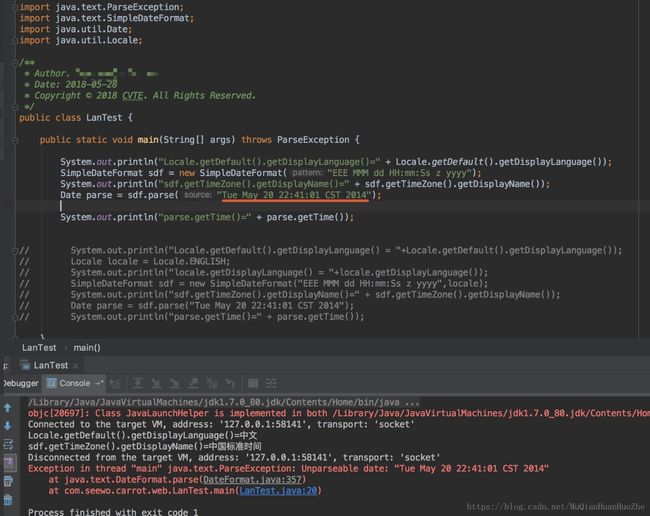
SimpleDateFormat使用Locale.ENGLISH转换,ok

看到这里问题貌似出来了,估计是服务器的默认Locale值存在差异。于是乎,撸起袖子就干。
服务器SimpleDateFormat实验
分别在服务器cdh003,cdh004 执行,代码,为了确定问题,指定使用coudera用的jdk版本:
/usr/java/jdk1.7.0_67-cloudera/bin/javac -d . LanTest.java && /usr/java/jdk1.7.0_67-cloudera/bin/java LanTest
然而的出来的结果出人意料,cdh003,cdh004结果都一样!!不应该啊,不应该啊,真的不应该这样子的。。

百思不得其解,郁闷。。。
SimpleDateFormat没有设定时区是会使用默认的操作系统的locale配置
Java 官方的说明:http://www.oracle.com/us/technologies/java/locale-140624.html
github翻阅hive源码
没办法了,是能去挖坟了,默默打开github,找出hive udf 实现的源码。
源码地址:里面有hive的所有udf源码实现 我用的版本是1.1所以看了1.1分支的代码
from_unixtime 函数的实现类 UDFFromUnixTime ,截图只是重点部分截图
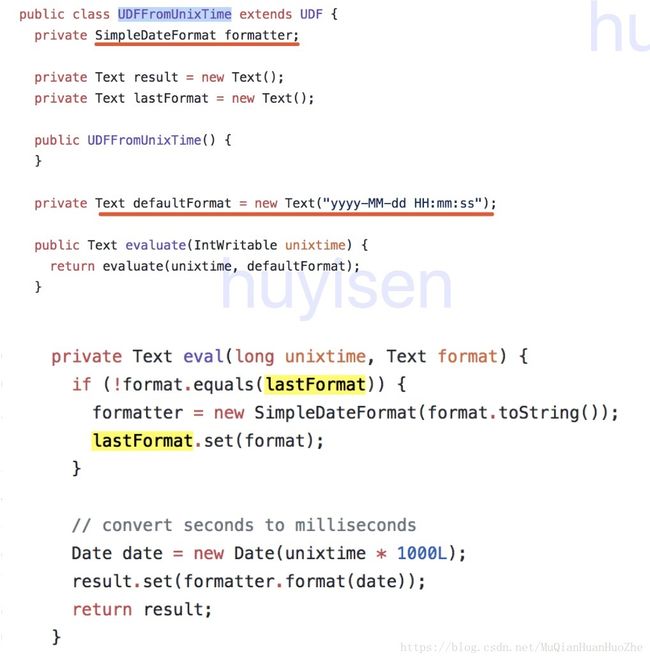
源码中发现from_unixtime的实现中并没有指定Locale,跟我猜想的一样,不指定Locale是正常的啦,必将全世界都在用嘛。。
再看看unix_timestamp函数的实现类 GenericUDFUnixTimeStamp ,这哥们的代码稍等惊人。

然而这里并没有任何SimpleDateFormat的身影,别慌看父GenericUDFToUnixTimeStamp,熟悉的身影
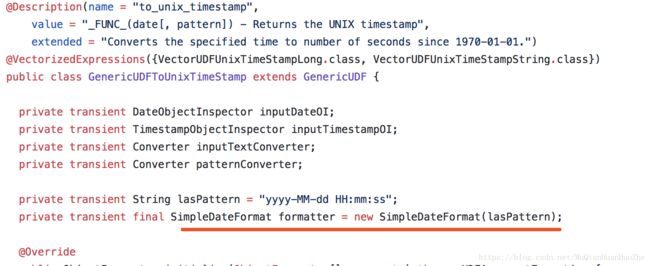
GenericUDFToUnixTimeStamp的转换不走大致可以分为2个步骤:
1、根据输入的不同类型转成不同类型的ObjectInspector

2、根据不同类型的ObjectInspector格式化字符串

源码中发现unix_timestamp的实现中并没有指定Locale,还是那就老话,必将全世界都在用嘛,不指定是正常的啦。
unix_timestamp、from_unixtime 实现中都没有指定Locale,hive 跑 mr job 时候获得的Locale值跟我在服务器上跑测试例子 LanTest.java 一样的才对,这里为什么不一样呢?无解,真的无解,有被坑过的同学可以告诉下我吗?
问题原因
跟运维沟通确认后发现,服务集群中由于不同批次上线的机器的配置略不同,有些机器装机的时候选择的默认语言是中文的,有的是英文的,后来然统一改成了英文,这样会引发java的一些默认环境有说差异。由于java 默认解析的默认Locale 存在差异,有些机器使用中文,hive 的unix_timestamp函数,使用SimpleDateFormat 格式化这样的”Sun May 20 23:59:21 CST 2018”时间字符串时会报错。
但是,机器已经改已经修改成英文的,为什么hive 跑 mr job 时候获得的Locale值还是获取到原来的中文??????无解,真的无解,有被坑过的同学可以告诉下我吗?
解决方案
终极大法 :hiveServer2,mapreduce.map.java.opts,mapreduce.reduce.java.opts 添加 -Duser.language=en 指定语言


重启服务器之言,多次校验通过,世界和平,稳稳的。。
总结
- 服务集群中由于不同批次上线的机器的默认语言配置略不同,引发了本次血案
- 建议后又的服务器机器环境尽可能相同,默认语言,时区,jdk版本 等
不要一味的想着让机器的软环境适应jvm,能用-D指定的默认值尽可能用-D指定