卷积神经网络中十大经典的操作算法

自2012年AlexNet在CNN的发展以来,科学家们发明了各种CNN模型,一种更深,一种更准确,一种更轻。我将简要回顾一下近年来的一些革命性工作,并从这些创新工作中探讨CNN未来变革的方向。
注意:由于水平有限,以下意见可能有偏见。我希望丹尼尔可以纠正他们。此外,仅介绍代表性模型。由于原理相同,不会引入一些着名的模型。如果有遗漏,欢迎您指出。
1.卷积只能在同一组中进行吗?
组卷积分组卷积首次出现在AlexNet中。由于当时硬件资源有限,训练AlexNet中的卷积操作无法在同一GPU中进行处理,因此作者将功能映射分配给多个GPU进行单独处理,最后融合多个GPU的结果。
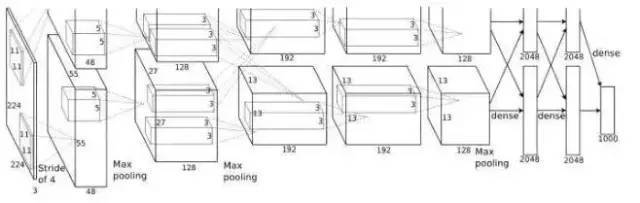
2.卷积核心越大越好? - 3 x 3卷积核心
AlexNet使用一些非常大的卷积内核,例如11 * 11和5 * 5卷积内核。以前,人们认为卷积核越大,感受野越大,他们看到的图片信息越多,他们得到的特征就越好。然而,大的卷积核将导致计算复杂度的大幅增加,这不利于模型深度的增加和计算性能的降低。因此,在VGG和Inception网络中,两个3 * 3卷积内核的组合优于一个5 * 5卷积内核。同时,参数(3 * 3 * 2 + 1 VS 5 * 5 * 1 + 1)减小,因此3 * 3卷积核被广泛用于各种模型中。
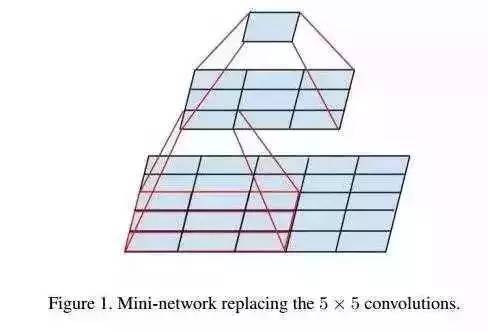
3.每层卷积只能使用一个大小的卷积核心吗? - 初始结构
传统的级联网络基本上是一堆卷积层,每层只使用一个大小的卷积核心,例如使用大量3 * 3卷积层的VGG结构。事实上,同一层特征映射可以使用不同大小的几个卷积核心来获得不同的特征尺度,然后结合这些特征来获得比使用单个卷积核心更好的特征。Google的Google Net或Inception系列网络使用多个卷积核心的结构。:
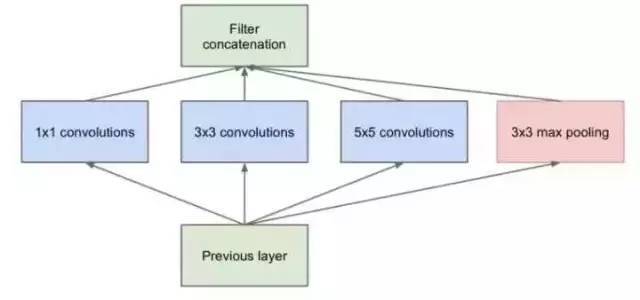
Inception结构的初始版本
如上图所示,输入特征图由1 x 1,3 x 3和5 x 5的卷积核同时处理,并且所获得的特征被组合以获得更好的特征。然而,在这种结构中存在严重的问题:参数的数量远多于单个卷积核心的数量。如此大量的计算将使模型效率低下。这导致了一个新的结构:
4.我们如何减少卷积层的参数? - 瓶颈
发明Google Net的团队发现,只引入多种尺寸的卷积核心会带来许多额外的参数,这些参数受到Network In Network中的1 * 1卷积核心的启发。为了解决这个问题,他们在Inception结构中添加了一些1 * 1卷积核心,如图所示:
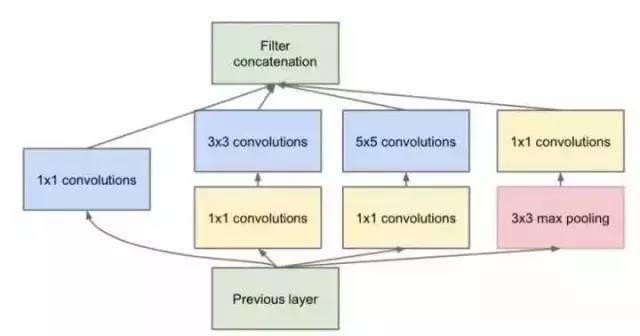
具有1 * 1卷积核的初始结构
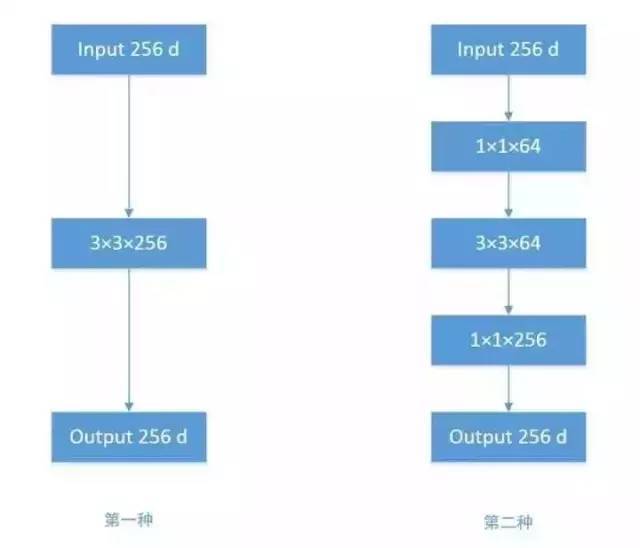
根据上图,假设输入特征映射的维数为256,输出维数为256,我们进行比较计算。有两个操作:
256维的输入直接通过3 x 3 x 256的卷积层,并输出256维的特征图。参数是256 x 3 x 3 x 256 = 589,824。
256维的输入通过1 * 1 * 64的卷积层,然后通过3 * 3 * 64的卷积层,最后通过1 * 1 * 256的卷积层。256维的输出是256 * 1 * 64 + 64 * 3 * 64 + 64 * 1 * 256 = 69,632。将第一次操作的参数减少到九分之一!
1 * 1卷积核心也被认为是一项影响深远的操作。为了减少大型网络中的参数数量,将来会应用1 * 1卷积核心。
5.网络越深,训练越难吗? Resnet残留网络
传统的卷积级联网络将遇到问题。当层数加深时,网络的性能变得越来越差。在很大程度上,因为当层数加深时,梯度消失得越来越严重,因此反向传播很难训练到浅层网络。为了解决这个问题,何开明发明了一种“残余网络”,使梯度流更容易进入浅层网络,这种“跳过连接”可以带来更多的好处。在这里我们可以参考PPT:非常深的网络。
6.卷积运算必须同时考虑渠道和地区吗? - DepthWise操作
标准卷积过程可以在上图中看到。当2 * 2卷积核心被卷积时,相应图像区域中的所有信道被同时考虑。问题是,为什么我们必须同时考虑图像区域和通道?为什么我们不能将通道与空间区域分开?Xception网络是在上述问题的基础上发明的。首先,我们对每个通道进行卷积运算,并且存在与通道一样多的滤波器。在获得新的信道特征映射之后,对这些新的信道特征映射执行标准的1 * 1跨信道卷积操作。该操作称为“深度明智卷积”或“DW”。
因此,与标准卷积运算相比,深度运算减少了许多参数。同时,论文指出该模型具有更好的分类效果。
7.分组卷积可以随机分组通道吗? - ShuffleNet
在AlexNet Group Convolution中,特征通道被均匀地分成不同的组,然后通过两个完整的连接层融合特征。这样,不同组之间的特征只能在最后时刻融合,这对于模型的推广是非常不利的。为了解决这个问题,ShuffleNet在该组转换层的每个堆栈之前执行一次信道混洗,并且通过其将shuffle传递的信道分配给不同的组。在组conv之后,通道再次进行shuffle,然后将其分成下一组卷积循环。
通道随机播放后,组转换输出功能可以考虑更多通道,输出功能自然更具代表性。此外,AlexNet的分组卷积实际上是一个标准的卷积运算,而在ShuffleNet中,分组卷积运算是深度卷积。因此,结合频道改组和深度卷积分组,ShuffleNet可以获得极少数的参数以及超越移动网络和竞争对手AlexNet的精度。
8.渠道之间的特征是否相等? - SEnet
无论是在Inception,DenseNet还是ShuffleNet,我们都可以直接组合所有通道的特性,而不管重量如何。为什么我们认为所有渠道的特征对模型都有相同的影响?这是一个很好的问题,因此ImageNet 2017冠军SEnet问世。
在上层输出一组特征。这时,有两条路线。第一个直接通过。第二个首先执行挤压操作(全局平均合并),其将每个通道的二维特征压缩成一维特征向量(每个数字代表相应通道的特征)。然后执行激励操作以将特征信道矢量输入到两个完整连接层和S形模型中以模拟特征信道之间的相关性。输出实际上是每个通道的相应权重。这些权重通过Scale乘法通道加权到原始特征(第一条路径),这就完成了。特征通道的重量分配。
9.固定大小的卷积核可以看到更广泛的区域吗? - 扩张卷积
标准的3 * 3卷积核心只能用于
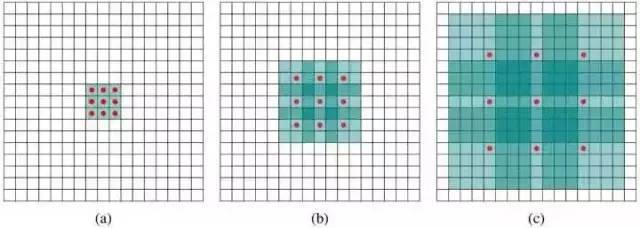
上面的图B可以理解为卷积核心大小仍然是3 * 3,但每个卷积点之间有一个洞,也就是说,在绿色的7 * 7区域,只有9个红点已被卷曲,并且重量为 其余的点为0.因此即使卷积核心大小相同,它看到的区域也会变大。详细解释显示答案:如何理解扩张卷积?
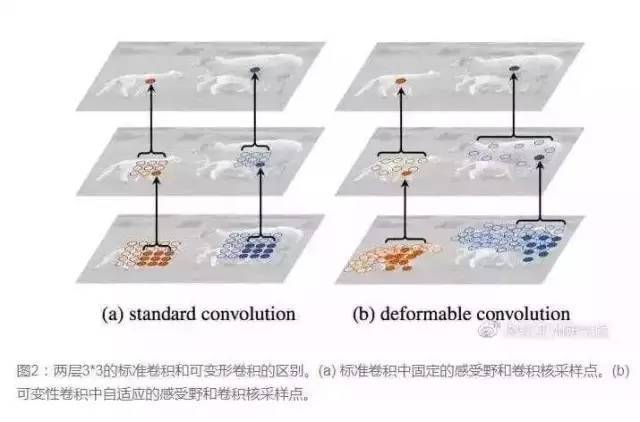
10.卷积核心的形状是否必须是矩形?可变形卷积可变形卷积核心
传统的卷积核通常是矩形或正方形,但MSRA提出了一种相反的直观观点,即卷积核的形状可以改变,变形卷积核只能查看感兴趣的图像区域,因此识别特征更好。
启蒙与反思
如今,越来越多的CNN模型逐步从巨型网络发展到轻量级网络,模型的准确性也在不断提高。现在行业的焦点不是提高准确性(因为它们已经非常高),它们都专注于速度和准确性之间的交易,他们都希望模型快速准确。所以从AlexNet和VGGnet到尺寸较小的Inception和Resnet系列,移植网和ShuffleNet都可以移植到移动终端(体积可以减少到0.5mb!)。我们可以看到这样的趋势:
卷积内核:
大卷积内核被小卷积内核取代。
单尺寸卷积核心被多尺寸卷积核心取代。
固定形状卷积内核倾向于使用可变形卷积内核。
使用瓶颈结构。
卷积频道:
标准卷积由深度卷积代替。
使用分组卷积;
在数据包卷积之前使用信道混洗。
频道加权计算。
卷积层连接:
Skp连接用于使模型更深入。
密集连接,使每一层融合另一层的特征输出(DenseNet)
启发
通过类比信道加权操作,卷积层跨层连接是否也可以加权?瓶颈+ Group conv + channel shuffle + depthwise的组合是否会成为未来减少参数的标准配置?
关注微信公众号:“图像算法”或者搜索imalg_cn 即可获取更多资源